커맨드 part 1

-
-version
- .bash_profile 수정
export HADOOP_HOME=/Users/groom/Platform/hadoop-3.3.0
export PATH=$HADOOP_HOME/bin:$PATH- 수정 후
source ~/.bash_profile적용 hadoop version명령어를 통해 버전 확인 가능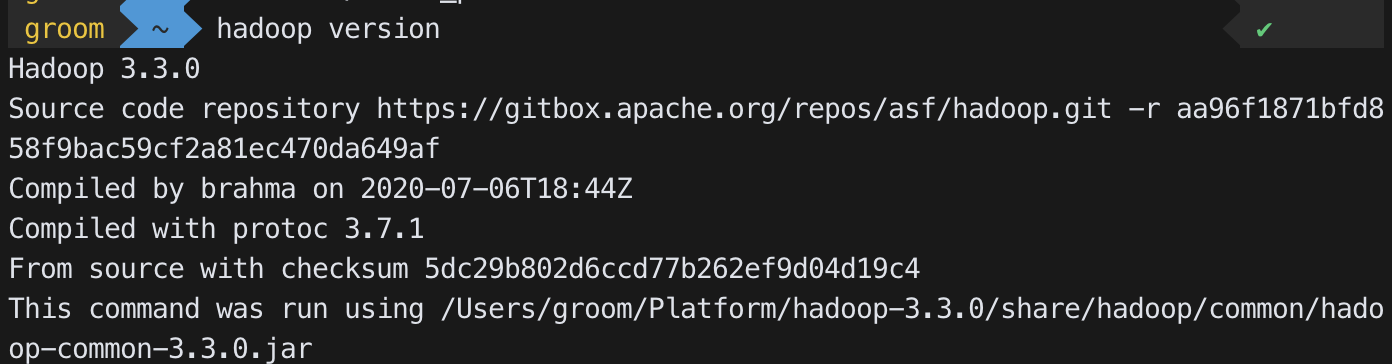
-
-mkdir, -ls
- mkdir와 ls는 기본 리눅스 명령어와 동일
hadoop fs -ls /hadoop fs -mkdir /tmphadoop fs -ls -R /
(특정 디렉토리의 하위 디렉토리를 모두 보여준다)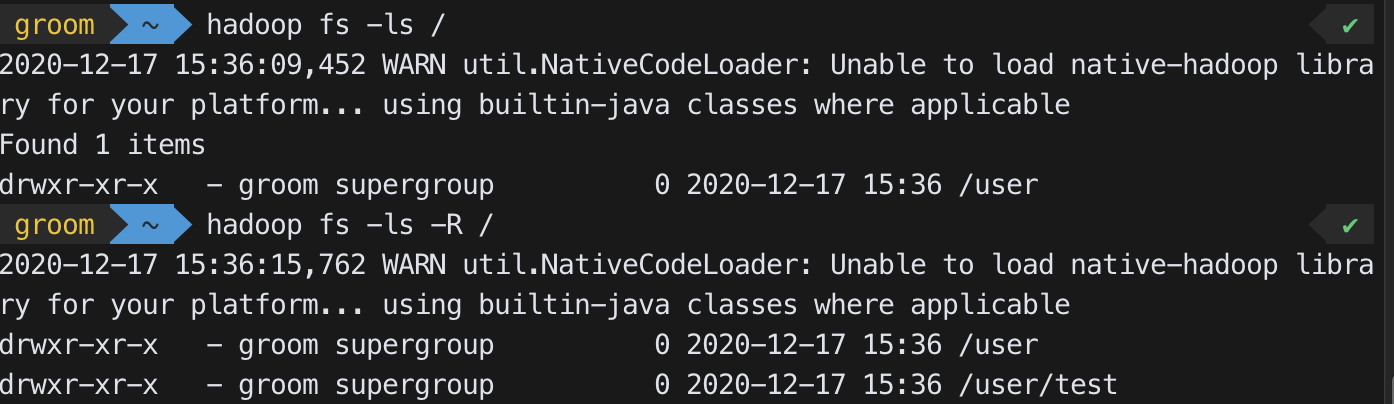
-
-put
hadoop fs -put <local src> <hdfs dest>- 로컬파일을 hdfs에 저장
-
-copyFromLocal
hadoop fs -copyFromLocal <local src> <hdfs dest>- 로컬 파일을 hdfs에 업로드 (put과 유사하다)
-
-get
hadoop fs -get <hdfs src> <local dest>- Hdfs의 파일을 Local directory로 다운로드
-
-copyToLocal
hadoop fs -copyToLocal <hdfs src> <local dest>- Hdfs에 있는 파일을 local directory에 다운로드, get 명령어와 유사
-
-cat
hadoop fs -cat <path to file in hdfs>- 리눅스 cat과 동일
-
-mv
hadoop fs -mv <src> <dest>- 리눅스 mv와 동일
-
-cp
hadoop fs -cp <src> <dest>- 리눅스 cp와 동일
커맨드 part 2

-
-moveFromLocal
hadoop fs -moveFromLocal <localsrc> <dest>- local에 있는 파일을 하둡으로 이동
-
-tail
- `hadoop fs -tail [-f]
- 특정 file에 대해 마지막 kilobyte을 stdout으로 보여줌

-
-rm
hadoop fs -rm <path>- rm -R : 특정 디렉토리 이하의 폴더 모두 제거
- rm -r : -R과 동일
- rm -skipTrash : 즉시 완전 삭제
-
-chown
hadoop fs -chown [-R] [owner] [:[group]] <path>- 슈퍼오너일 경우에만 해당 파일의 owner 변경가능
-
-chgrp
hadoop fs -chgrp <group> <path>- 해당 파일의 오너거나 슈퍼오너라면, 해당파일의 그룹권한을 변경 가능하다
- 그룹명이 변경된 모습
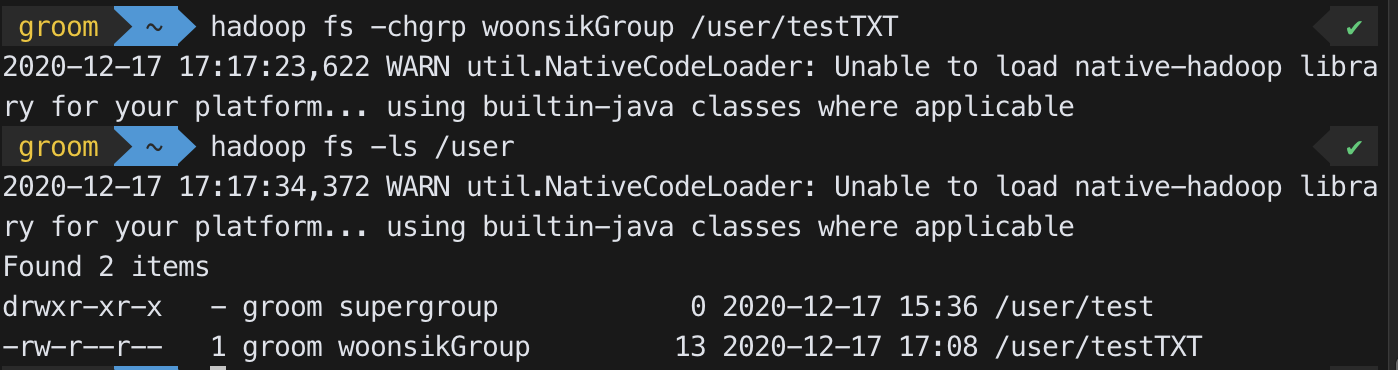
-
-setrep
hadoop fs -setrep <rep> <path>- set Replication으로 카피본의 수를 조절한다
hadoop fs -setrep 2 /user 를 입력시 해당 폴더는 replication을 3이아닌 2로 갖게된다
-
-df
hadoop fs -df [-h] <path>- -h를 붙이면 사람이 보기 쉬운 mb, gb 등의 단위로 보여준다
-
-du
hadoop fs -du -s <file path>- 특정 디렉토리 혹은 파일을 기준으로 디스크 사용량을 확인

커맨드 part 3

-
-touchz
hadoop fs -touchz <dir/filename>- Zero length인 file을 생성
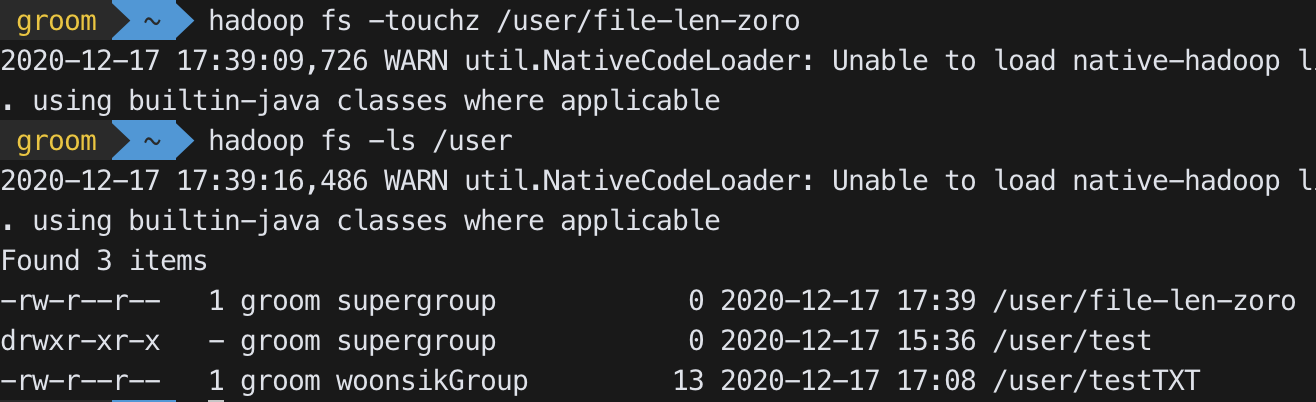
-
-text
hadoop fs -text <src>- Hdfs의 특정 파일을 text format으로 확인
-
-stat
hadoop fs -stat [format] <path>- hdfs의 특징 디렉토리의 stat info를 확인
Foramts - %b - file size in bytes
- %g - group name of owner
- %n - file name
- %o - block size
- %r - replication (복사 개수)
- %u - user name of owner
- %y - modification data
-
-usage
hadoop fs -usage <command>- 명령어의 사용법 출력 (간단히 입력 형식만 나온다)
-
-help
hadoop fs -help <command>- 명령어의 모든 사용법 출력
- 명령어의 설명 및 모든 옵션들에 대한 설명이 나온다
-
-checksum
hadoop fs -checksum <src>- 무결성 테스트를 위한 명령어
-
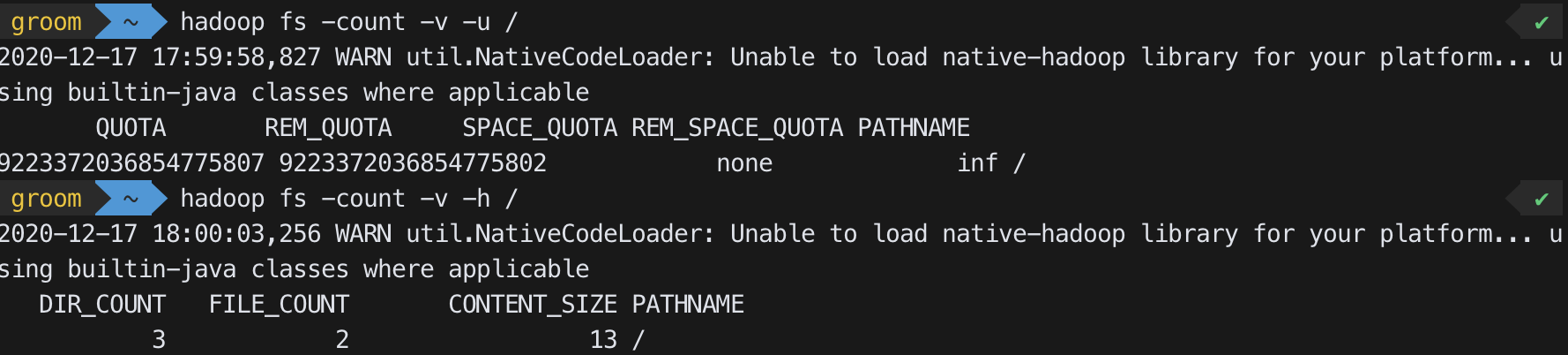
-count
hadoop fs -count [options] <path>- Directory 개수, file 개수 등을 카운트하여 숫자로 보여준다
Options - -q : show quotas
(quotas는 개별 디렉터리에 사용되는 이름 수 및 공간의 하드의 제한이다) - -u : quotas와 사용하는것만 보여주는 제한적인 출력을 한다
- -h : 사람이 보기 쉽게 단위를 변경해서 보여준다
- -v : header line을 보여준다
-
-find
- `hadoop fs -find
... - 원하는 파일을 찾는 방식을 입력하고 해당 조건의 원하는 파일을 입력 후 표현 방식을입력

- `hadoop fs -find
-
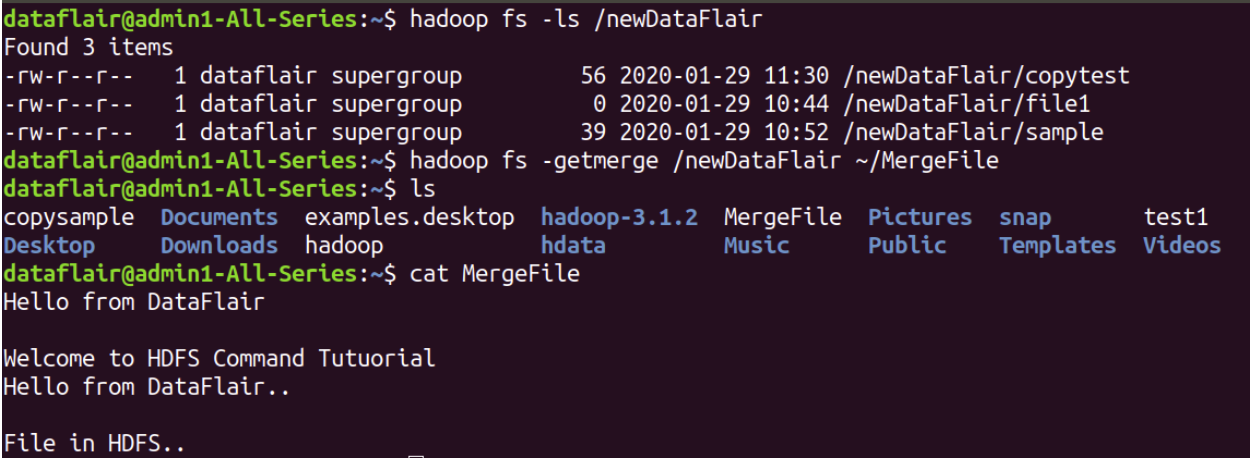
getmerge
hadoop fs -getmerge <src> <local dest>- 하둡에 파일 개수가 굉장히 많을 때 해당 파일들을 하나의 파일로 합쳐서 로컬에 다운받고 싶을때 사용한다
- Hdfs내부의 source file을 local file에 append하여 로컬로 다운로드
HDFS에 대하여
Rack Awareness 설정
렉(rack)단위로 장애가 나는 상황이 날수 있다. 랙의 스위치가 장애가 나거나 랙의 전원에 장애가 날 수 있으므로, 블록을 저장할 때, 2개의 블록은 같은 블록에, 나머지 하나는 이외의 다른 랙에 저장하도록 하는 것
-> 랙 단위 쟁애 발생에도 전체 블록이 유실되지 않도록 함
HDFS 세이프 모드
HDFS의 세이프 모드는 데이터 노드의 추가와 수정을 할 수 없으며 데이터 복제도 일어나지 않는 상태이다
하둡이 가지고 있는 데이타 노드중에 미싱블록의 발생이 일정 퍼센티지 이상의 수준이 되면 시스템상 문제가 있다고 보고 하둡이 세이프 모드에 들어가게 된다
하둡이 가져야할 Replication 3 설정에서 2를 가지고있다면 under replicated 되있다고 하며, 하나도 없다면 missing block이라고 한다
클러스터를 재구동 했을때에도 Name space 정보를 재구성하기 전까지는 세이프 모드로 동작을 하게 된다
HDFS Admin명령어
관리자용 명령어가 별도록 존재한다
이를 통해서 세이프 모드에 대한 관리를 해줘야 하는 경우도 존재한다
- 운영중에 세이프 모드에 진입하면 네임노드의 문제인지, 데이타 노드의 문제인지 파익이 필요하고,
fsck명령으로 HDFS의 무결성을 체크 후,hdfs dfsadmin -report명령으로 각 데이터 노드의 상태를 확인하여 문제를 확인하고 해결한 후에 세이프 모드를 해제할 수 있다
커럽트 블록
HDFS는 하트비트를 통해 데이터 블록에 문제가 생기는 것을 감지하고 자동으로 복구를 진행한다. 복구시에는 다른 데이터노드에 복제된 데이터를 가져와서 복구하는데 모든 복제 블록에 문제가 생겨서 복구를 하지 못하게 되면 커럽트 상태가 된다
-> 커럽트 상태의 파일들은 삭제하고 원본 파일을 다시 HDFS에 올려주어야 한다
HDFS 휴지통
HDFS는 데이터 삭제시 바로 영구적으로 데이터를 삭제하지않고 휴지통(trash)로 보내는 설정을 할 수 있다
fs.trash.interval: 체크 포인트를 삭제하는 시간 간격(분), 0이면 휴지통 기간을 끈다fs.trash.checkpoint.interval: 체크 포인트를 확인하는 간격(분), fs.trash.interval값 이하여야 한다. 체크 포인터가 실행 될 때마다 체크포인트를 생성하고, 유효기간이 지난 체크 포인트는 삭제한다
보통 1~3일 정도를 설정해놓으며 HDFS는 가장 로우 단의 저장장치인 경우가 많으므로 여기서 삭제가 되면 해당 자료를 찾기는 어렵다고 봐야한다
HDFS 휴지통 설정 및 명령어
- core-site.xml에 설정
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
<property>
<name>fs.trash.checkpoint.interval</name>
<value>120</value>
</property>- 휴지동 비우기
hadoop fs -expunge
- 휴지통을 거치지않고 즉시 삭제
hadoop fs -rm -skipTrash <file>- 사용하지 말자 !!
운영자 커맨드 목록
- 주로 실행이나 설정에 관련된 명령어가 많다
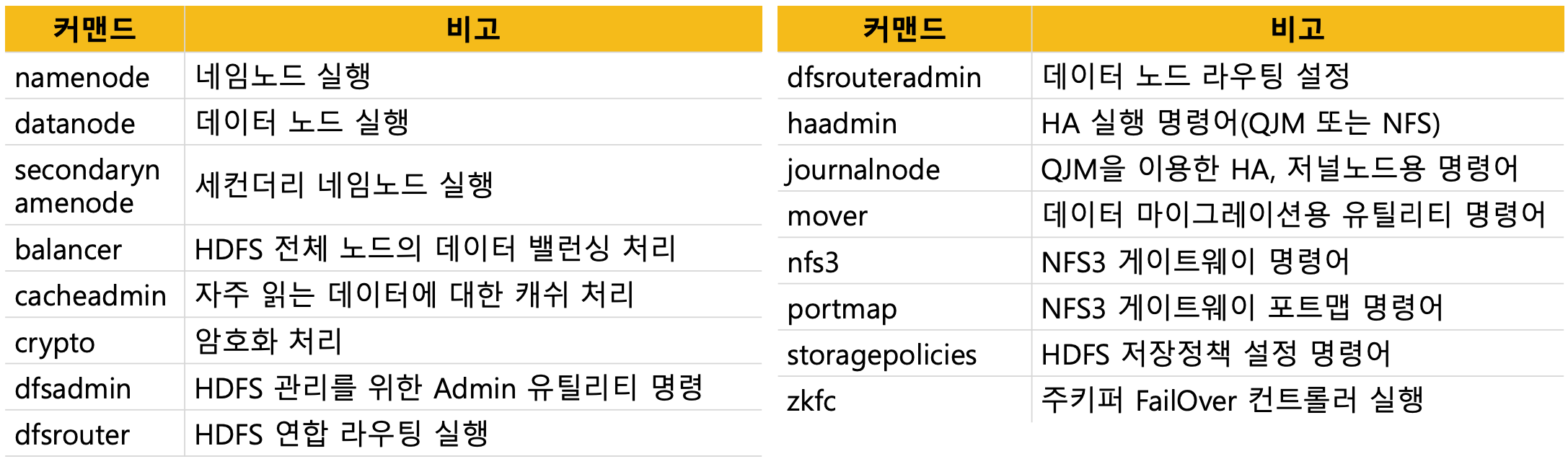
HDFS 운영자 커맨드 : hdfs dfsadmin + ~
dfsadmin -report
- HDFS의 각 노드들의 상태를 출력하며, HDFS의 전체 사용량과 각 노드의 상태를 확인할 수 있다
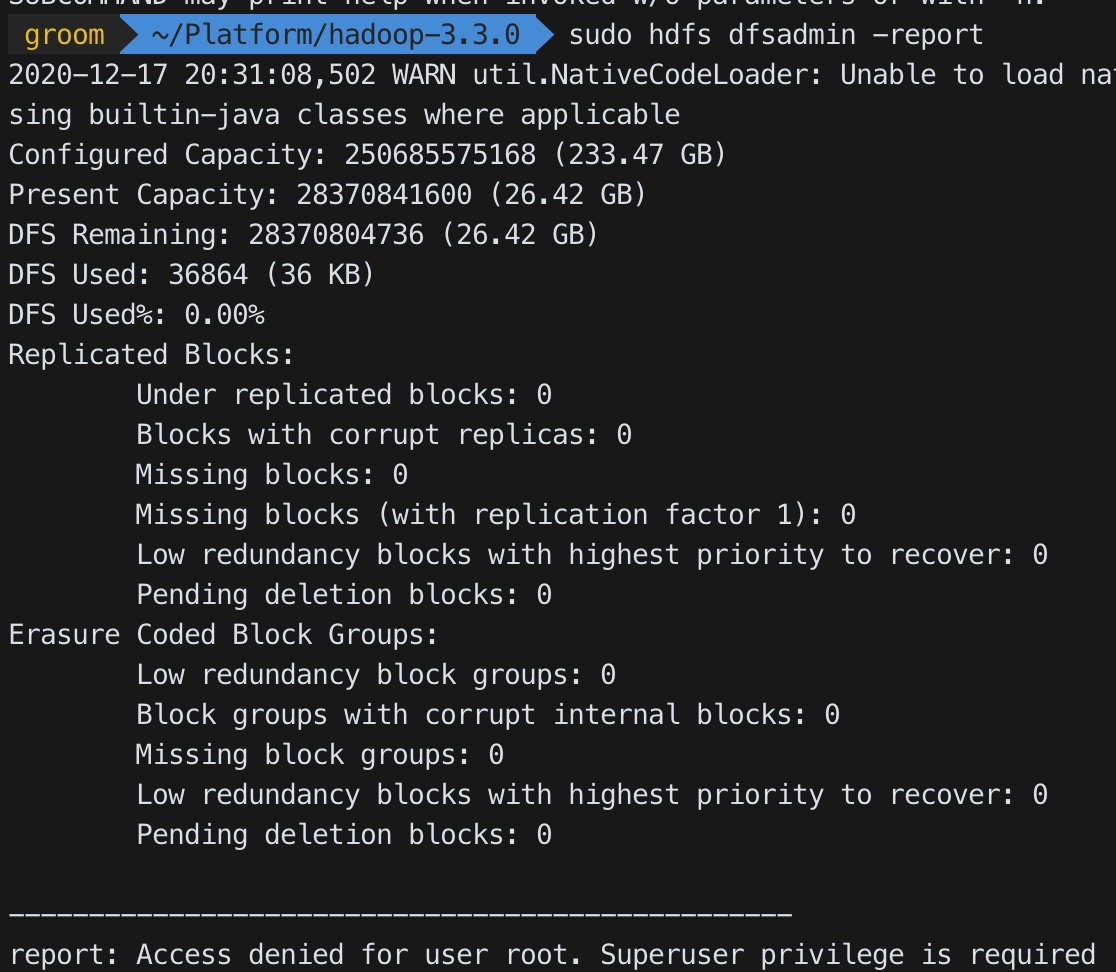
- 용어
• Configured Capacity: 각 데이터 노드에서 HDFS에서 사용할 수 있게 할당 된 용량
• Present Capacity: HDFS에서 사용할 수 있는 용량
• DFS Remaining: HDFS에서 남은 용량
• DFS Used: HDFS에 저장된 용량
• DFS Used% : 사용중인 용량 %
• Under replicated block : 블록 리플리카 설정보다 블록개수가 적은 블록 수
활용
-
hdfs dfsadmin -report -live: live한 data node를 포함한 Hadoop 상태 report -
hdfs dfsadmin -report -dead: dead한 data node report
위와 같은 명령어를 통해 데이타 노드를 확인하고 관리할 수 있다
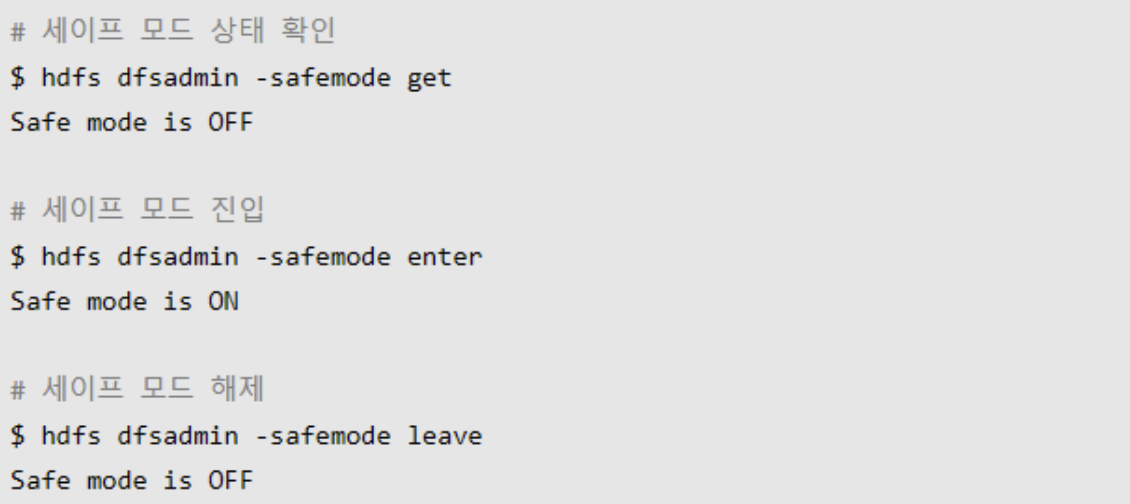
dfsadmin -safemode
- 세이프 모드에 집입하거나 빠져나올수 있다
- get : 세이프 모드 상태를 확인
- enter : 세이프 모드 진입
- leave : 세이프 모드 복구(나옴)
- wait : 세이프 모드이면 대기하다가, 세이프 모드가 끝나면 회복
dfsadmin -setQuota
특정 디렉토리는 어떤 팀한테만 데이터를 저장을하거나 복사를 할수 있게 가이드를 해줬는데 해당 디렉토리의 용량을 1테라로 제한을 하고 싶다하면 쿼터 설정을 해줄수 있다
- 특정 디렉토리에 용량 Quota를 설정, n의 단위는 byte
- 설정 :
sudo -u hdfs hdfs dfsadmin -setSpaceQuota n <dir> - 해제 :
sudo -u hdfs hdfs dfsadmin -clrSpaceQuota n <dir>
- 설정 :
HDFS Balcancers (중요)
하둡을 운영하다보면 하둡 클러스터가 서로 상이한 스펙의 데이터노드들로 하나의 클러스터를 구성하게 되는 경우가 존재한다 (추가적인 슬레이브 노드 구매 등의 이유로)
이런 경우에는 노드들 간에 밸런싱이 안되는 경우가 많다.
예를 들어 2018년에 도입했던 서버에는 하나의 데이타노드에 디스크가 20테라를 가지고 있는데 2020년에 도입한 서버에는 40테라를 가지고 있다고 하자
이렇게되면 네임 노드가 블럭을 데이터 노드에 할당 할 때 데이터 적재량이 적은 노드를 우선적으로 선정하여 데이터 블럭을 적재하게 되는데 이때, 상대적으로 디스크(용량)가 부족한 노드는 총 용량의 80프로를 사용하는 반면 최신 서버의 경우에는 총 용량의 30프로만 사용하게 되는 데이터 저장상태의 불균형이 발생하게 된다
(적재 용량은 같지만 전체 수용 가능 데이터양 중에서 적재량의 퍼센티지의 불균형)
이 부분을 잘 관리를 해줘야 한다 (하둡 2.0까지는), 3.0 버전에 들어오면서 부터 어느정도 관리를 해준다
HDFS Balancers 설정
하둡 파일 (hdfs-site.xml)설정 중 Balancer와 연관된 중요한 설정이 있다
<property>
1. <name>dfs.datanode.balance.max.concurrent.moves</name>
<value>50</value>
</property>
<property>
2. <name>dfs.datanode.balance.bandwidthPerSec</name>
<value>104857600</value>
</property>이 설정은 보통 하둡 클러스터 운영에 문제가 없도록 방어적으로 설정하는 것이 일반적이다. 명령어로도 설정을 반영할 수 있다
1번 : 디스크의 밸런싱을 할 때, 동시에 얼마나 빨리 복사를 할 것인가에 대한 옵션, 얼마나 많은 쓰레드를 사용해서 이 일을 처리하게 할것인지
2번 : 데이터 노드기준으로 bandwidth를 얼마까지 줄것인지, 데이터 노드들끼리 자기들끼리 데이터를 교환해야하므로 통신 트래픽이 발생하는데 이를 어느정도로 잡을것인지 (보통 보수적으로 잡음)
balancer 대역폭을 100mb로 올림 : $HADOOP_HOME/bin/hdfs dfsadmin -setBalancerBandwidth 104857600
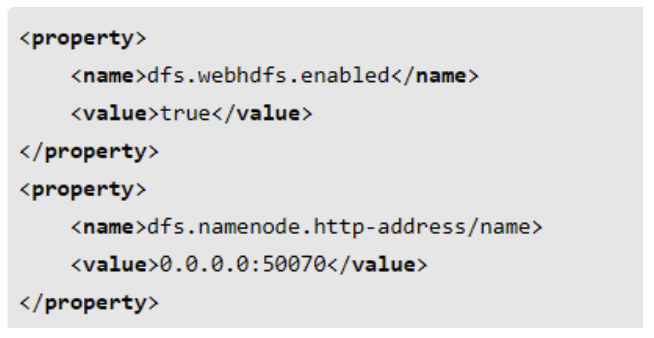
WEB HDFS REST API
HDFS는 REST API를 이용해서 웹상에서 파일을 조회하고, 생성, 수정, 삭제하는 기능을 제공한다
이 기능을 이용하여 원격지에서 HDFS의 내용에 접근하는 것이 가능하다
파일리스트 확인 예
curl -s http://127.0.0.1:50070/sebhdfs/v1/user/hadoop/?op=LISTSTATUShdfs-site.xml의 파일 설정이 필요하다
HDFS 암호화 - KMS (key Management Server)
하둡 KMS는 KeyProvider API를 기반으로 하는 암호화 키 관리 서버이다 (REST API 제공)
