하둡에 적합하지 않은 것
- 크지않은 데이터에 하둡을 적용하는것은 오히려 느리므로 적합하지 않다
- 파일사이즈가 기본적으로 크게 해서 관리하는것이 좋다. 작은 파일들이 여러개로 저장되있는것이 더 안좋다
- 헤르 라는 압축유형이 존재하는데, 작은 파일들을 헤르로 모아서 압축을 해서 보통 관리를 한다
- 데이터 파일이 1kb등의 수천파일들이 존재할 수 있는데 이를 하둡에서 잘 관리하기 위해서 combine format이 존재하므로 이를 이용하면 적합하다
- MapReduce는 프로그래밍 레벨등의 개발이 필요하다 (java, python, c++)
- 더 쉬운 분석 지원을 위해 SQL을 지원하는 쿼리 엔진이 필요하다
- Hive, Apache Spark SQL
(하둡에 저장되 있는 데이터를 sql 배치로 던질수 있다, Rdd 구조를 가지고 메모리상에서 처리하므로 속도가 매우 빠르다, 단 메모리 공간에서 처리하므로 메모리 이상의 너무 큰 파일은 처리가 힘드므로 Hive에서 처리를 해야한다)
일반적으로는 스파크가 더빠르고 메모리 이내의 사이즈일 경우에 대부분 스파크를 이용
- Hive, Apache Spark SQL
Hive
- 하둡에 저장된 데이터를 쉽게 처리할 수 있는 데이터 웨어하우스 패키지
- FaceBook에서 매일같이 생산되는 대량의 데이터를 관리하고 학습하기 위해 개발
- SQL과 유사한 Query Lang을 지원
- SQL레벨의 ETL 처리도구로 활용가능
- 작성된 쿼리를 내부적으로 MapReduce 형태로 변환
apache Spark
- 머신러닝, 실시간 분석, SQL 쿼리 분석, 그래프 처리 등 다양한 곳에 이용이 가능하다
- 메모리 기반 분산 처리라 Hive보다 3배가량 빠르다
aws 적용 모습
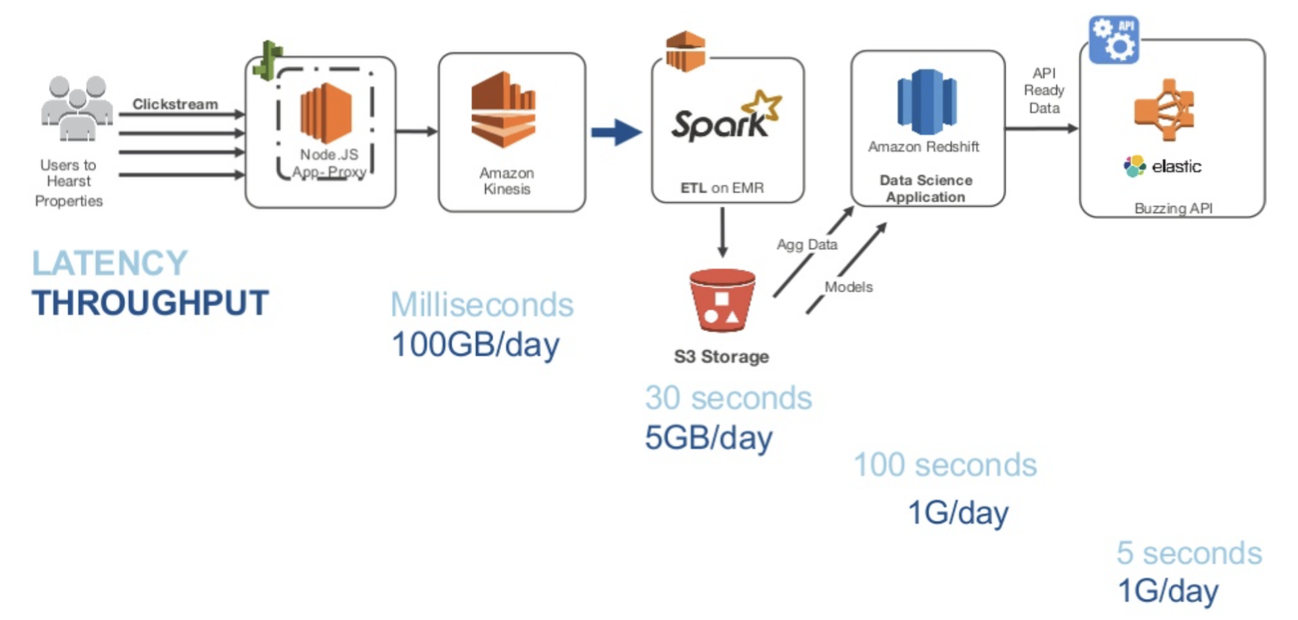
스타트업 등에서 서비스를 구성한다고 가정하면
그 서비스를 제공하면서 나오는 많은 로그 데이타들이 발생하게 될것이다
그 로그 데이타들을 실시간으로 처리해서 수집해주는 시스템으로 Amazon Kinessis 혹은 아파치 카프카와 같은 서비스가 존재한다
그렇게 수집한 데이터를 Spark의 EMR 상에서 ETL, (Extraction, Trasformation, Load)(추출, 변형, 적재, 데이터의 이동 및 변환 절차) 처리를 한다
여기서 EMR은 elastic MapReduce로 하둡 에코 시스템들을 managed Service(관리형 서비스)로 제공을 한다
그러면 손쉽게 하둡클러스터를 구성할 수 있게 된다
그렇게 나온 데이타들은 일반적으로 AWS에서 제공하는 S3의 저장장치에 저장을하고 해당 데이터들을 분석을 하기 위해서 빅데이터를 빠르게 처리하기 위한 Aamzon의 RedShift의 Data Warehouse 솔류션이 존재한다
번외
빅데이터관리는 거의 하둡 기반인가?
- 온프레미스 환경에서 자체구축한다고 하면 하둡이 일반적이다
- 클라우드 환경에서는 다양한 방법이 존재한다
- s3의 오브젝트 스토리지를 직접 사용하는 등
스트림 데이터가 들어올때 하나의 데이터를 두개의 카피를 통해서 하나는 실시간 데이터 처리용 플랫폼 등의 Spark 스트리밍 등으로 보내고(팬아웃) 하나는 HDFS의 데이터 저장용으로 보내게 된다

내꿈은 숲속의잠자는공주