MapReduce 2
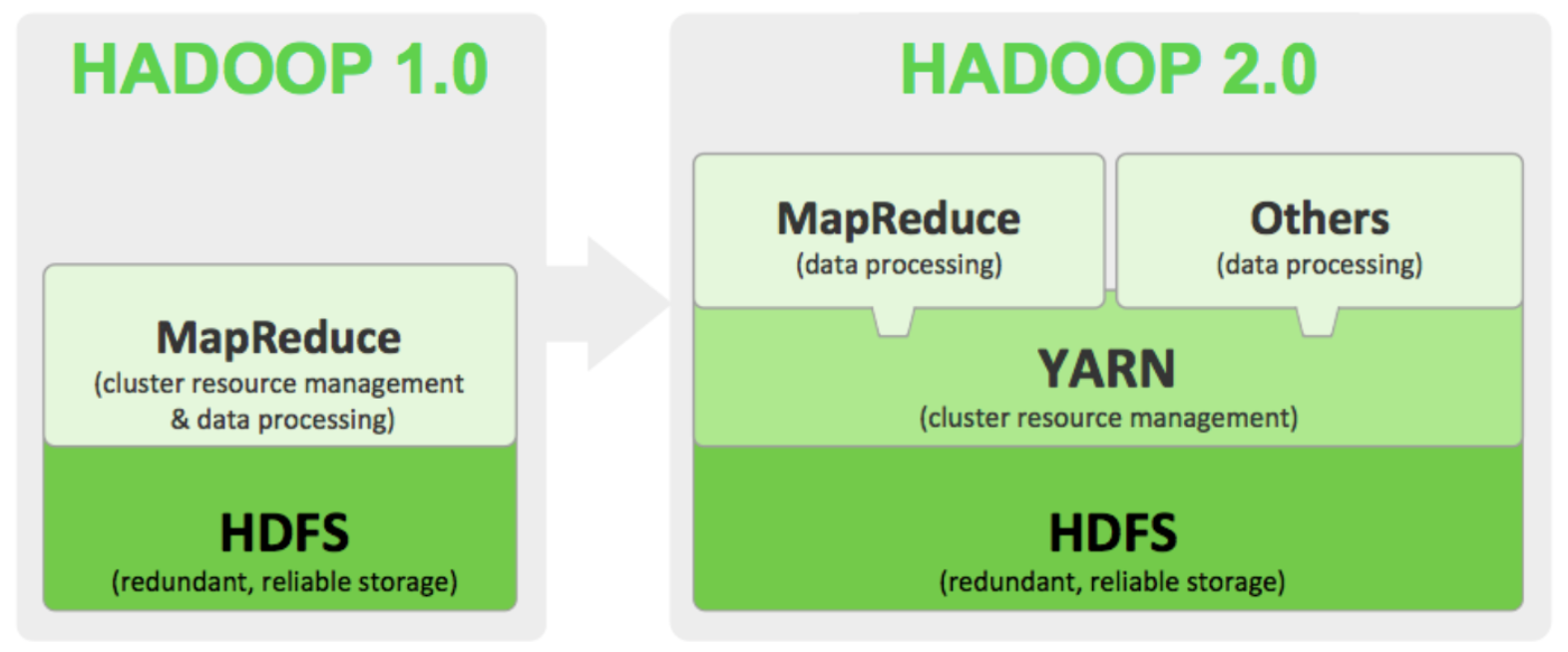
기존에 맵리듀스에서 자원관리와 데이터 처리를 같이하던 것에서 YARN에게 클러스터의 자원 관리를 맡기고 맵리듀스는 데이터 처리를 하도록 분할 하였다. 또한 맵리듀스 이외의 다른 Data Processing 방식도 수용가능한 아키텍쳐로 변경되었다
기존 맵리듀스1에서는 4000노드 이상의 매우 큰 클러스터에서 동작 시 병목현상 이슈가 발생했다 - JobTracker에 발생
확장성 문제를 해결하기 위해 JobTracker의 책임을 여러 컴포넌트로 분리
- ResourceManager : 클러스터의 컴퓨팅 리소스 를 관리
- ApplicationMaster : 클러스터에서 실행중인 Job의 LifeCycle을 관리
- NodeManager : 컨테이너를 모니터링하고, Job이 할당 받은 그 이상의 리소스가 사용되지 않도록 보장
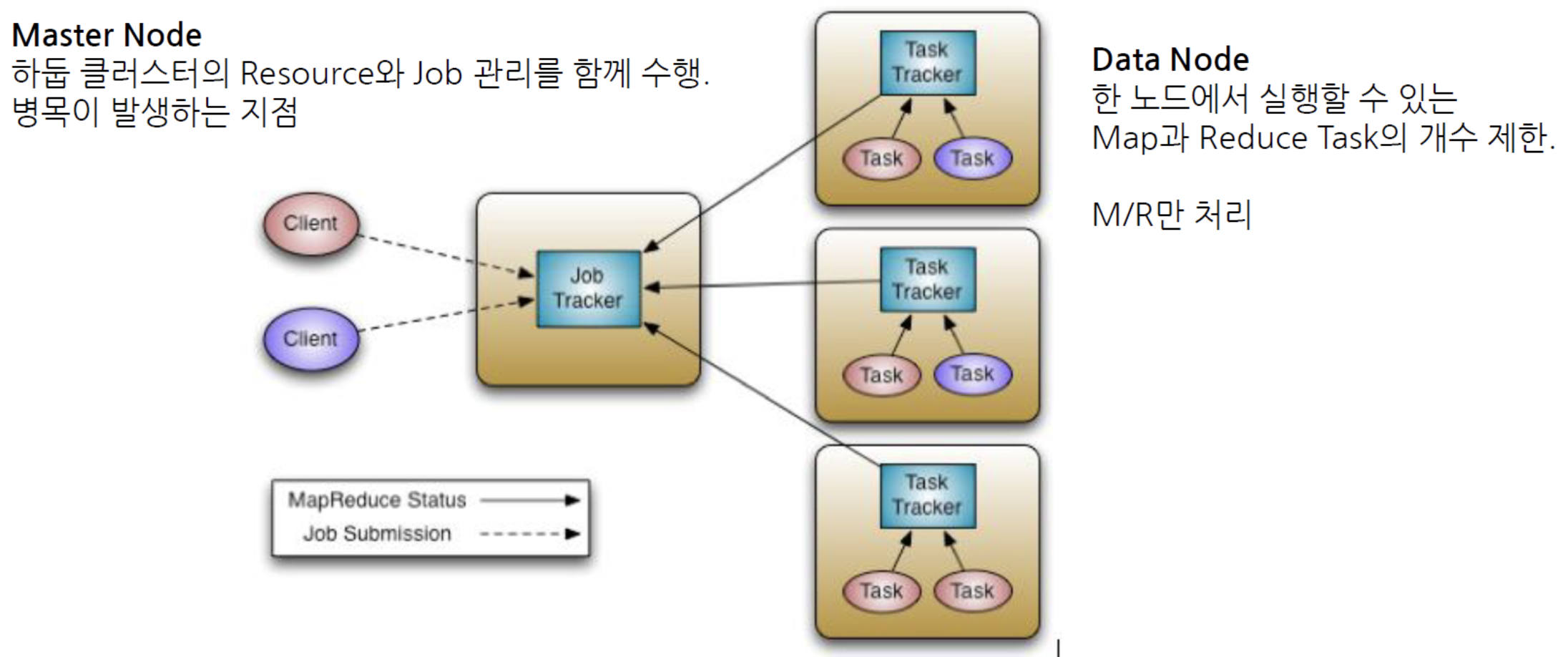
기존 1.0 맵리듀스
변경된 2.0 맵리듀스
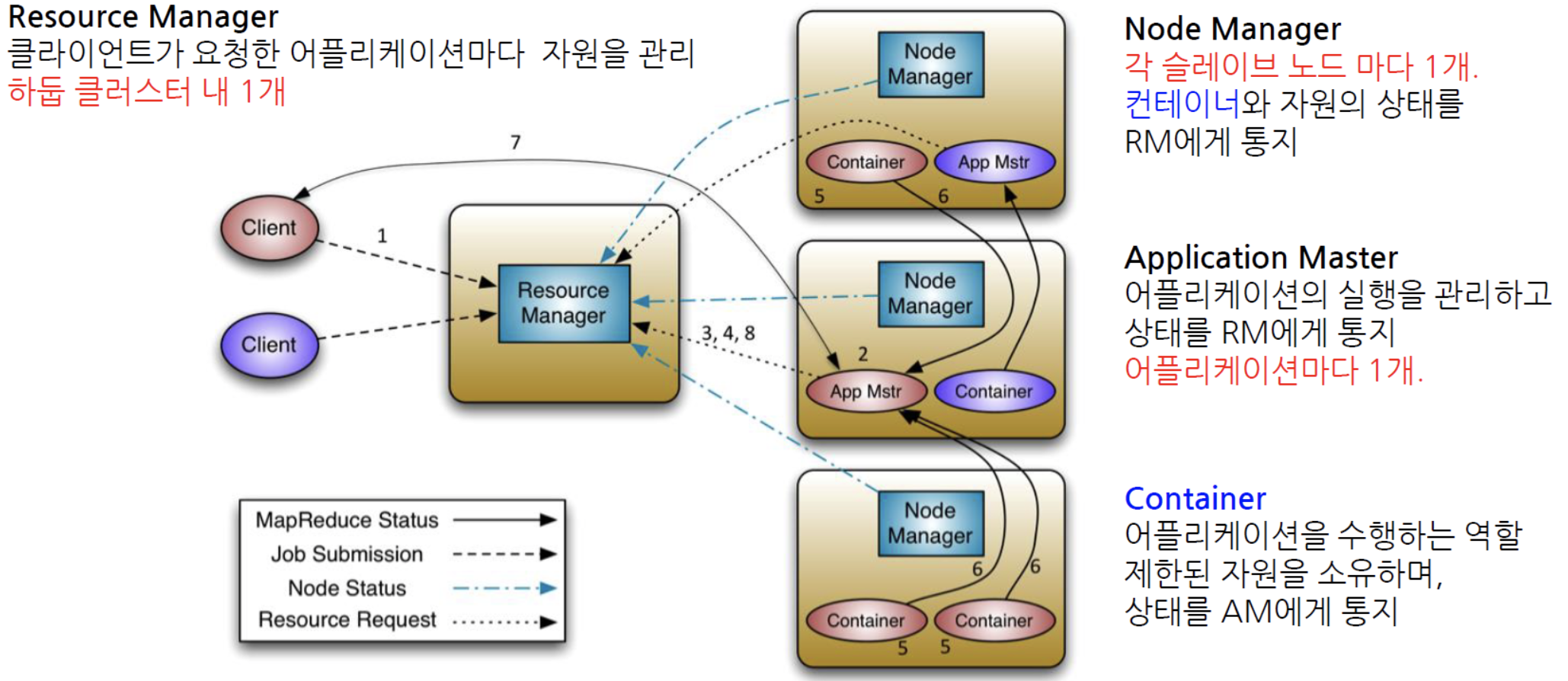
모든 노드에 NodeManger가 존재한다
클라이언트가 어떤 애플리케이션을 만들어서 Job을 submit을 하게 되면 ResourceManager가 전체 클러스터의 리소스를 주기적으로 리포트를 받다가 Application Master를 2번 서버에 실행을 하겠다고 2번 NodeManager에게 명령을 내리면 2번 NodeManager가 평소에는 존재하지 않다가 Application Master를 구동을 하는 방식이다
여기서 구동되는 Application Master가 1.0의 Job Tracker와 유사한 개념이다
Application Master가 Container에 명령을 내리게 된다. 이 Container가 1.0의 TaskTracker와 유사하다
상대적으로 복잡하기 때문에 Job Initialize에 걸리는 시간이 10~30초 정도 소요되므로 아무리 간단한 작업이라 할지라도 기본 세팅 시간이 오래잡아먹는다. 따라서 대규모의 데이터 처리에 적합한 시스템이다
YARN 맵리듀스 동작 흐름
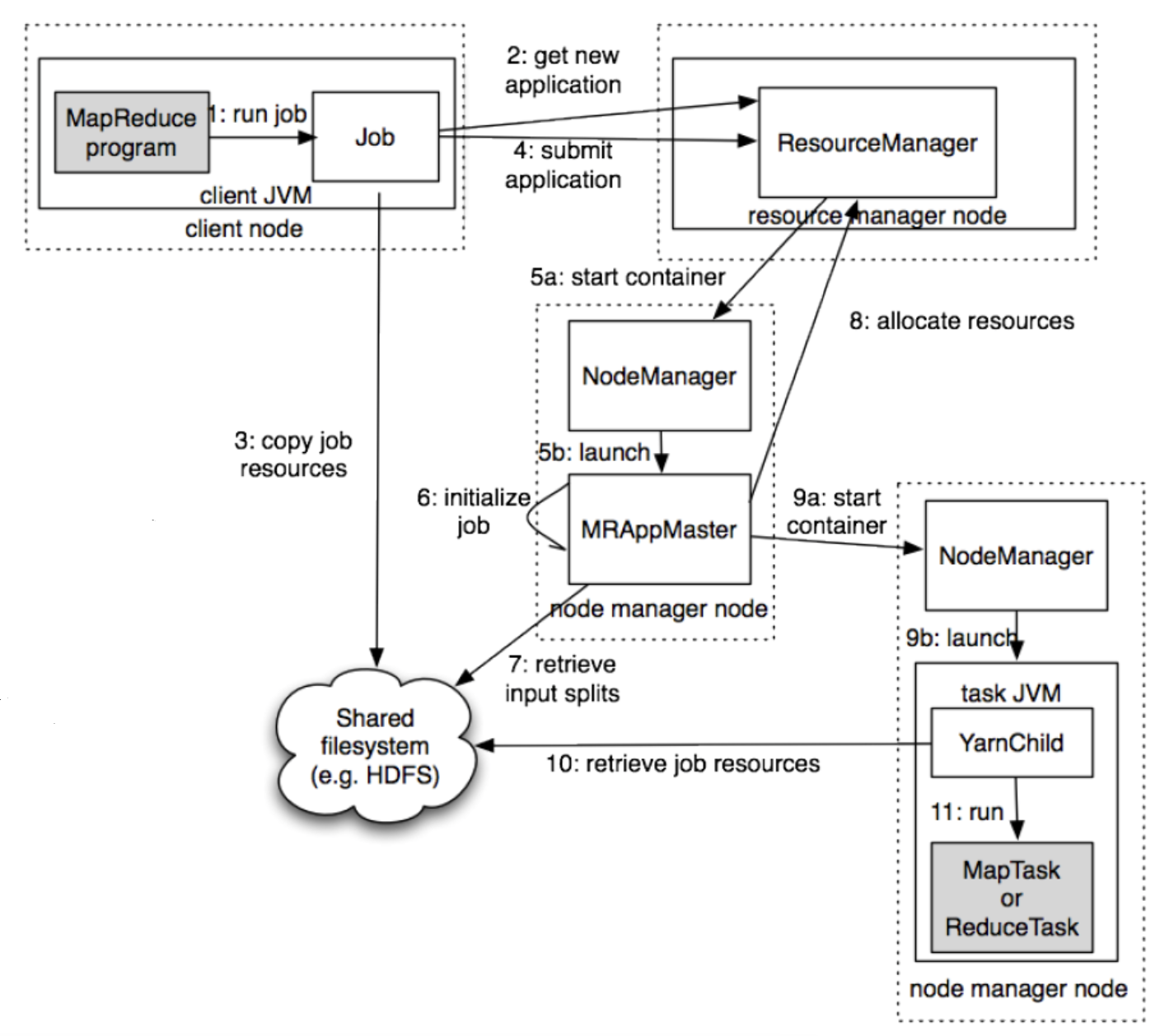
RM : 리소스 매니저
NM : 노드 매니저
AM : 애플리케이션 마스터
- 클라가 RM에게 애플리케이션 제출
- NM를 통해 AM 실행
- AM는 RM에게 자신을 등록
- AM는 RM에게 컨테이너 할당할 공간/위치를 받는다
- AM는 NM에게 컨테이너의 실행을 요청
- 앱 정보를 NM에게 제공
- 컨테이너는 앱의 상태정보를 AM에게 알린다
- 클라는 앱의 실행정보를 얻기 위해 AM와 직접 통신
- 앱이 종료되면 AM는 RM에게서 자신의 자원을 해제하고 종료
요청 흐름도
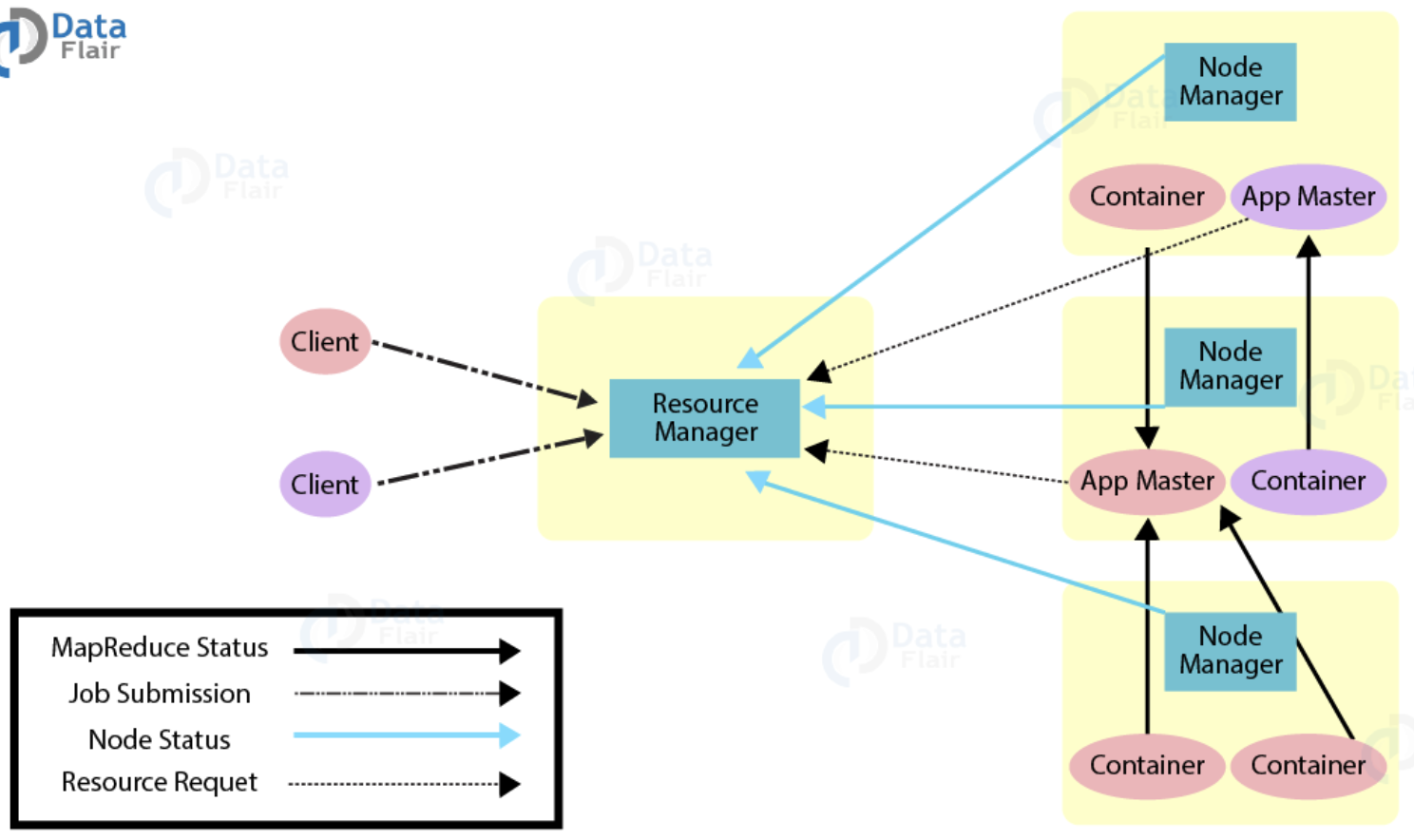
Container들이 앱 마스터에게 맵리듀스 상태정보 제공
클라가 RM에게 jop제출
Node Manager들이 RM에게 상태 항시 전송
AM가 RM에게 자원(리소스) 요청
YARN 맵리듀스
- Job 제출
- Job 초기화(Initialization)
- Task 할당
- Task 실행
YARN에서는 진행상황과 상태정보를 Application Master에게 보고한다
클라이언트는 진행상황의 변화를 확인하기 위해 매초마다 AM을 조회
하둡 3.0의 변화 확인
실습해보기
텍스트 파일에 대해서 단어 별로 카운트를 해주는 애플리케이션을 만들고 jar파일 생성
해당 파일을 HDOOP_HOME으로 복사
분석을 원하는 텍스트 파일을 HDFS로 복사
hadoop fs -mkdir /input
hadoop fs -put LICENSE.txt /input

실행
hadoop jar hadoop_edu-1.0-SNAPSHOT.jar com.sk.hadoop.WordCount /input/LICENSE.txt output
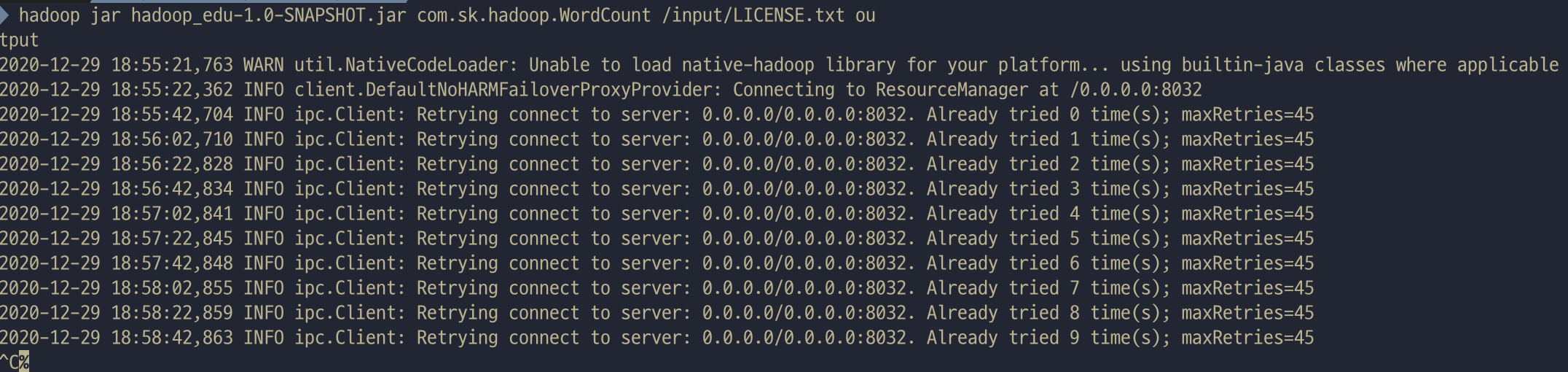
실행을 하니깐 서버에 연결을 못하고 헤메고 있어서
sbin/start-all.sh를 다시 실행 시켜주고 다시 명령어를 입력해 주었더니
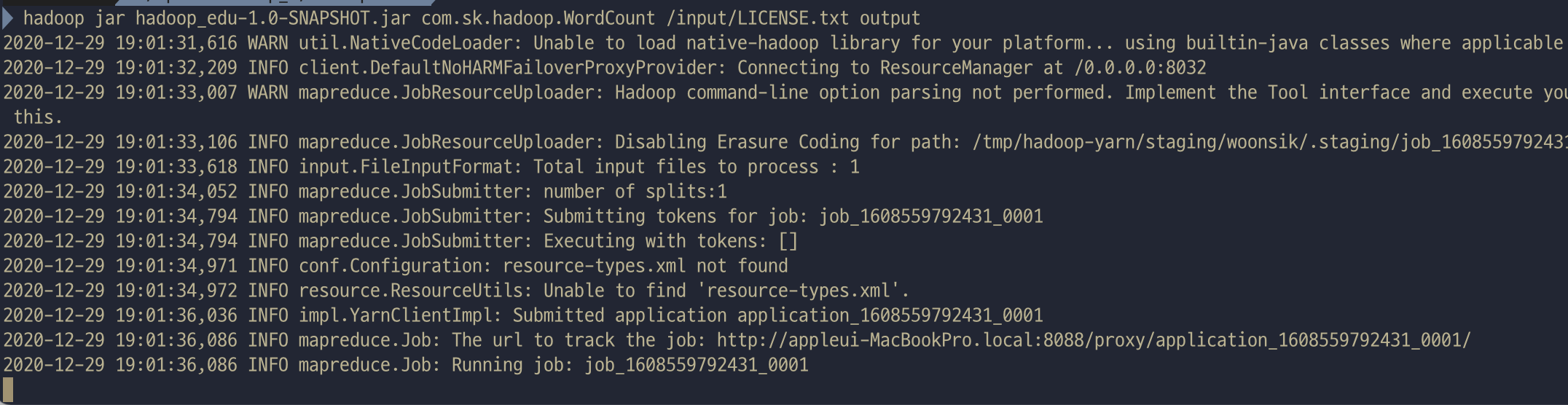
뭔가 진행되는 듯 나오면서 Runnig job이 떴다
문제는 더이상 진행되지 않고 멈춰있다는 것인데
로컬로 hadoop에 들어가서 보니
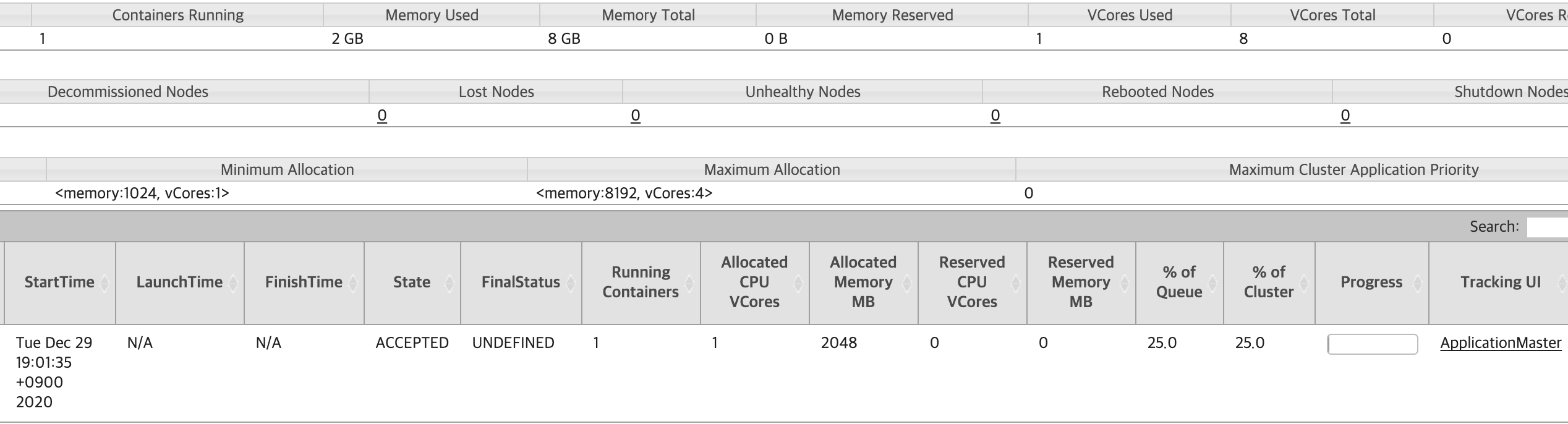
하둡 상에 정상적으로 등록은 되었는데 진행이 전혀 올라가지 않고 있었다
