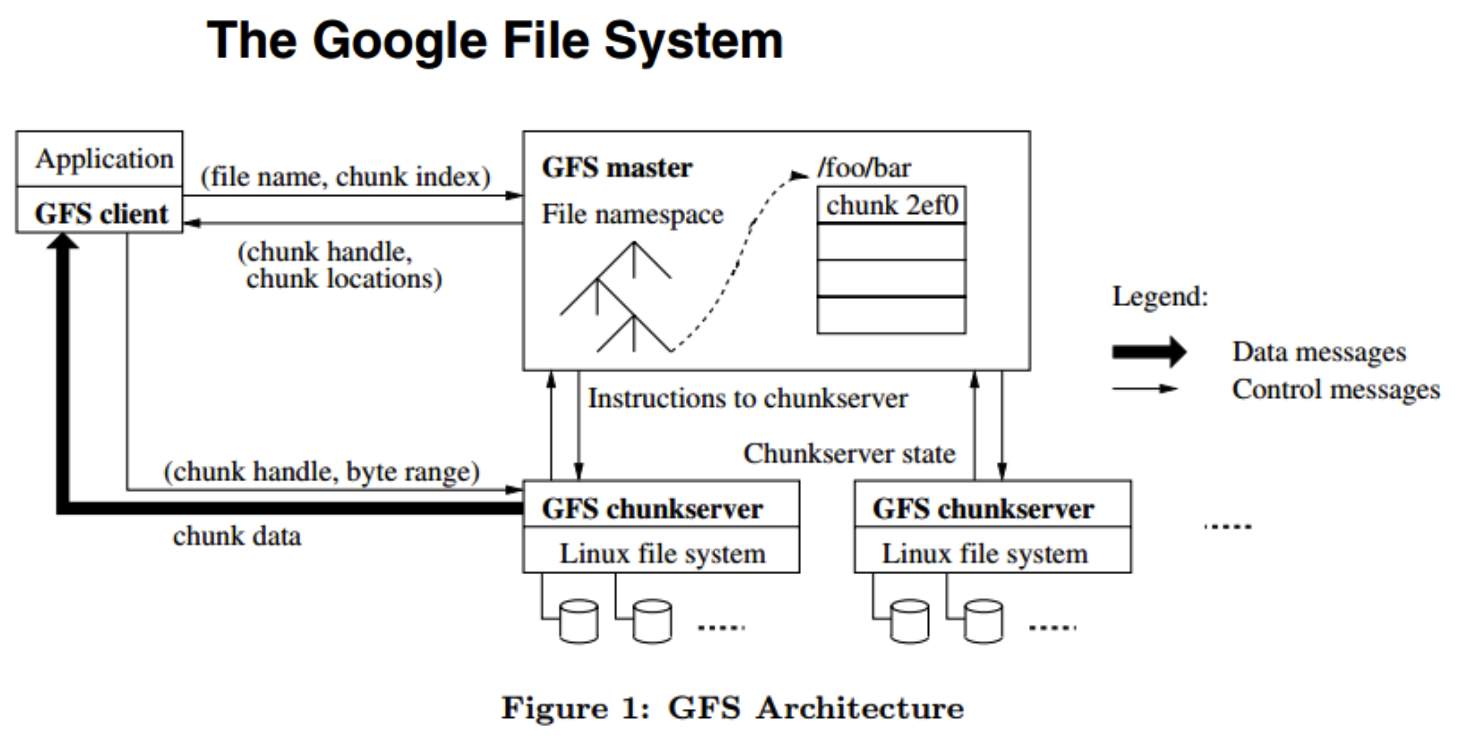
아래 그림은 앞에서 말한 구글 파일 관리 시스템 논문 중 한 부분이다
분산환경이란?
물리적으로 여러대의 서버가 하나의 클러스터처럼 동작하는 그런 플랫폼을 의미
그런 분산 플랫폼들의 아키텍쳐를 크게 두개로 구분하면 master-slave구조와 master가 없는 구조로 나눌수가 있다
master-slave 구조
- 최종 마스터 역활을 하는 마스터쪽 데몬들이 존재하며 이런 마스터의 관리를 받는 slave쪽 데몬들이 있는 형태
- slave서버들은 보통 n개의 서버로 계속 확장을 해 나갈 수 있는 아키텍쳐를 갖는다
master가 없는 구조
- 마스터가 하거나 가져야 하는 역활/정보들을 모든 노드들이 공유하는 플랫폼 아키텍쳐
Google File System의 구조는 master-slave구조이다
위 구조 그림에서 보면 알 수 있는데 GFS master가 Master이며, GFS chunkserver들이 Slave들이다
여기서 중요한 점은 항상 master에 부하가 가지않는 구조로 만들어 줘야 한다는 것이다
chunk data가 GFS chunkserver와 GFS client와 직접 연결이 되어있는데 이부분이 트래픽을 주고 받을 때 둘은 서로 커넥션을 갖고 데이터를 주고받지만 GFS master하고는 전혀 데이터를 주고받지 않는 구조이다
master-slave구조는 master의 오류가 발생시 관련된 전 서버가 다운되게 되므로 항시 master의 안정성을 최우선으로 여기게 된다. 운영을 할때도 마찬가지이다
구글 플랫폼의 철학
- 한대의 고가장비보다 여러대의 저가 장비가 낫다
- scale up, scale out
- 데이터는 분산저장한다
- parallel computing
동시에 많은 계산을 하는 연산의 한 방법이다. 크고 복잡한 문제를 작게 나눠 동시에 병렬적으로 해결하는 데에 주로 사용 - distributed computing
인터넷에 연결된 여러 컴퓨터들의 처리 능력을 이용하여 메시지를 하나에서 다른 하나로 보냄으로써 거대한 계산 문제를 해결하려는 분산처리 모델
-
시스템(H/W)는 언제든 죽을 수 있다 (smart S/W)
-
시스템 확장이 쉬워야 한다
- cluster노드수를 늘려도 평소처럼 작동해야한다
하둡 특성
- 수천대 이상의 리눅스 기반 범용 서버들을 하나의 클러스터로 사용
- 마스터-슬레이브 구조
- 파일은
블록(block)단위로 저장 - 블록 데이터의 복제본 유지로 인한 신뢰성 보장 (기본 3개의 복제본)
복사만해도 백업을 하지 않아도 하둡 플랫폼 자체적으로 복제본을 갖게 되어서 장애가 나더라도 데이터를 전부 잃는 경우가 발생하지 않는다 - 높은 내고장성 (Fault-Tolerance)
장애, 오류가 발생하더라도 정상적으로 혹은 부분적으로 기능을 수행하는 시스템 - 데이터 처리의 지역성 보장 (locality)
하둡 클러스터 네트워크 및 데몬 구성
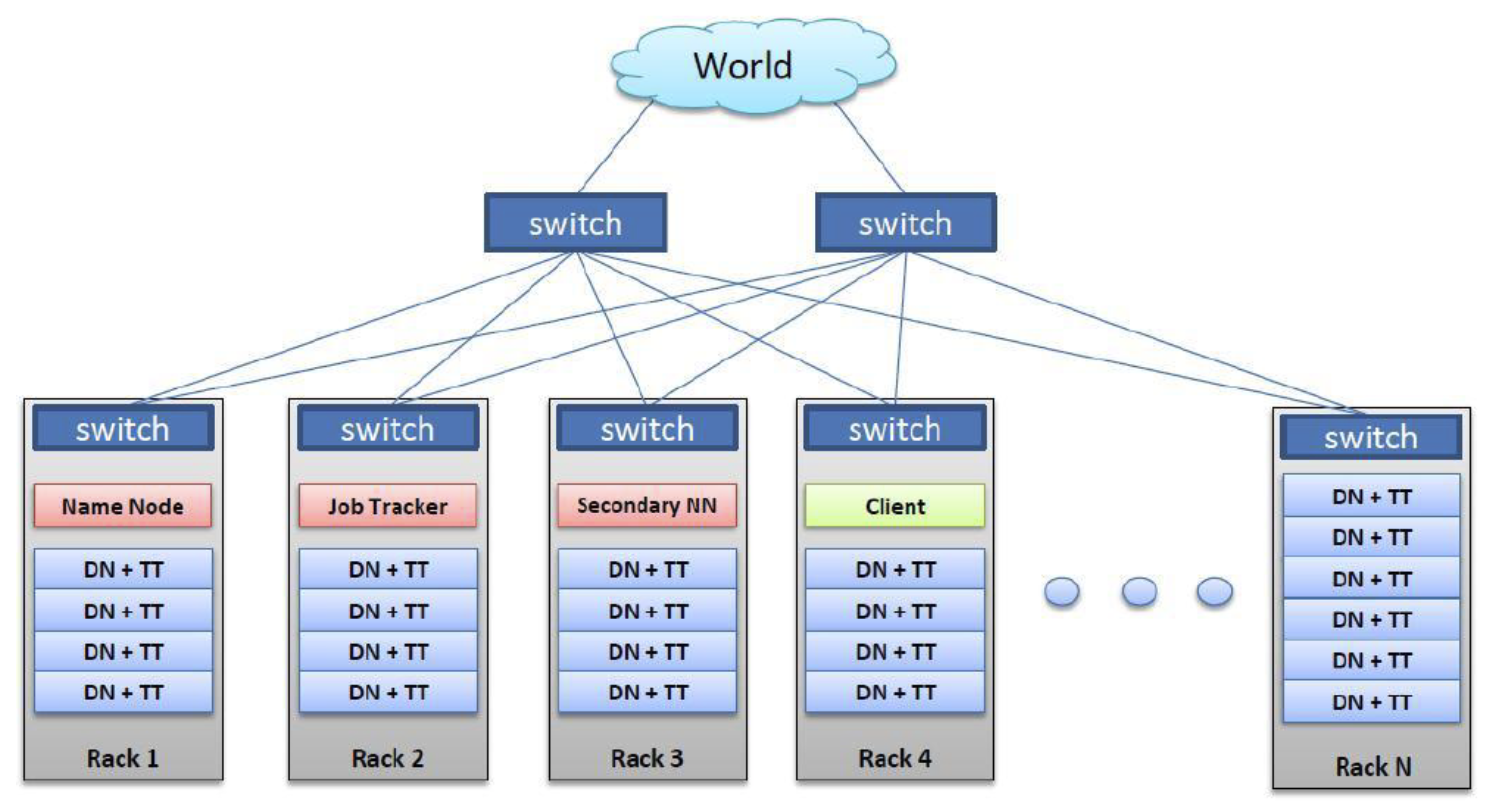
하둡 1.0을 기준으로 여러대의 서버를 하나의 클러스터로 구성을 하는 하둡은 위와 같은 rack-switch 구성을 갖는다. 즉 하둡 클러스터는 rack단위로 매우 큰 클러스터를 구성하는게 일반적인 구성
Name Node
- DFS의 마스터 서버 역활, 마스터에서 하둡 분산 파일 시스템을 관리하는 마스터 데몬
Jop Tracker
- 분산 파일 시스템에 저장되있는 데이터의 jop, 애플리케이션 연산 처리를 하기 위한 애플리케이션을 관리하는 마스터 데몬
DN, TT(Data Node와 Task Tracker) 데몬
- 이들은 한쌍으로 데몬을 띄우는데, 하둡 플랫폼 분산 파일 시스템의 slave, Jop을 관리하는 Jop Tracker의 salve 등 rack의 slave에 뜨게 되는 slave 데몬
- Task Tracker : 실제 애플리케이션 업무를 수행
하둡에서 블록(block)이란?
Data Blocks in Hadoop DFS
만약 하둡에서 612mb의 파일을 복사 명령을 통해 복사를 하게 하면 이 파일을 A(128) + B(128) + C(128) + D(128) + E(100) 의 형태로 알아서 쪼개서 DFS에 저장을 한다
- 하나의 파일을 여러개의 Blcok으로 저장
- 내부 설정에 의해 하나의 Block는 64MB 또는 128MB등의 크기로 나누어 저정
- 블록 크기가 128mb보다 작을 경우는 실제 크기 만큼만 용량을 치자한다
하둡에서 Block하나의 크기가 큰 이유는 ?
- HDFS의 블록은
128mb로 매우 큰 단위를 갖는다 - 블록이 큰 이유는 탐색 비용을 최소화할 수 있기 때문이다
- 블록이 크면 하드디스크에서 블록의 시작점을 탐색하는 데 걸리는 시간을 줄일 수 있고, 네트워크를 통해 데이터를 전송하는데 더 많은 시간을 할당할 수 있다
HDFS의 진행 예시
-
분당 24Gb의 데이터가 생성되고 이를 관리한다고 가정
-
보통 이런류의 데이터는 시간의 흐름에 따라서 끊임없이 계속 생성되는 로그성 데이터들 (Time-Series Data 시계열 데이터)
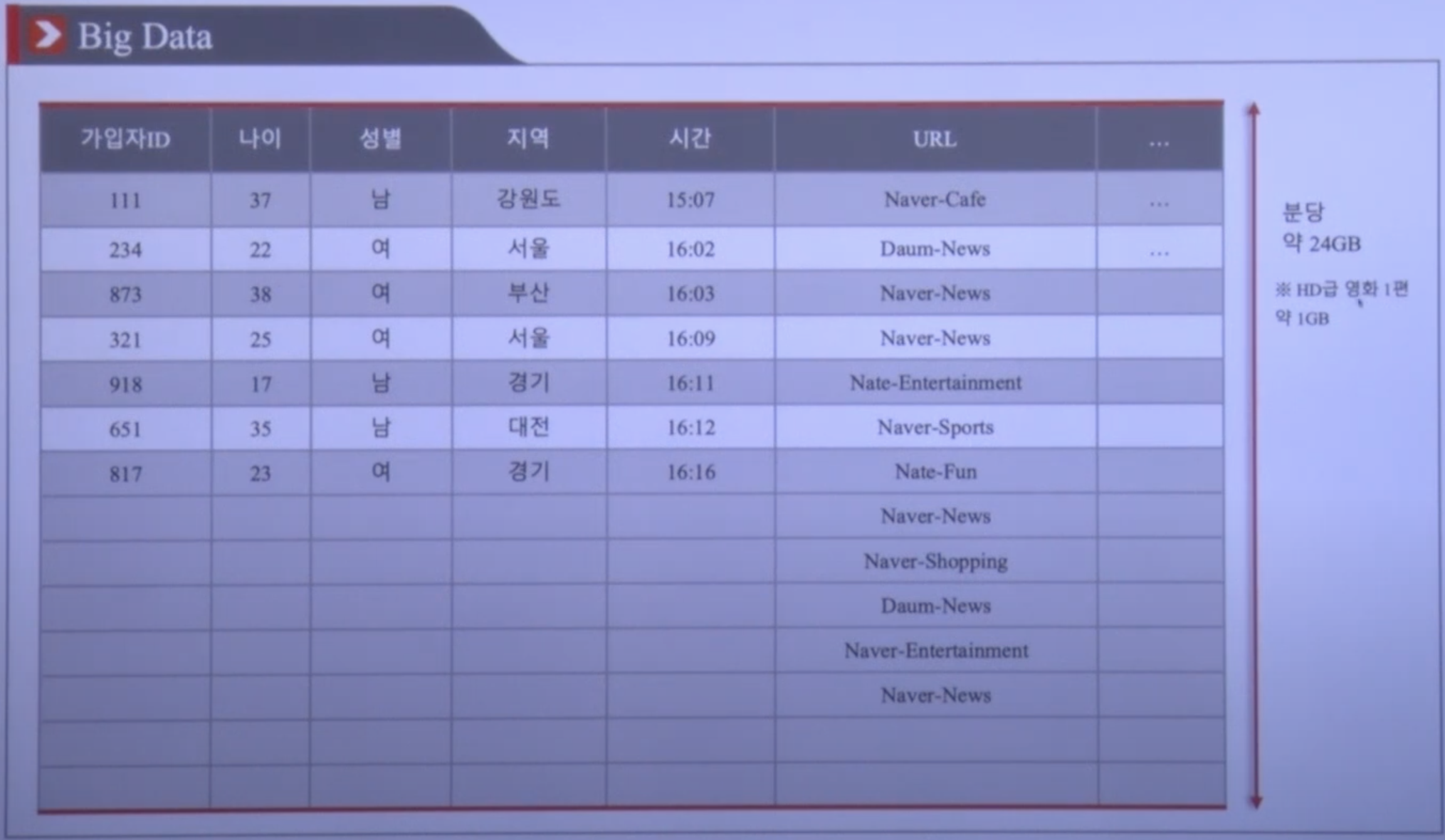
-
해당 대량의 데이터를 하둡 클러스터에 저장
(하둡 커맨드 이용 외에도 카프카 등 다른 플랫폼과 연계해서 적재하는 다양한 방법 존재)
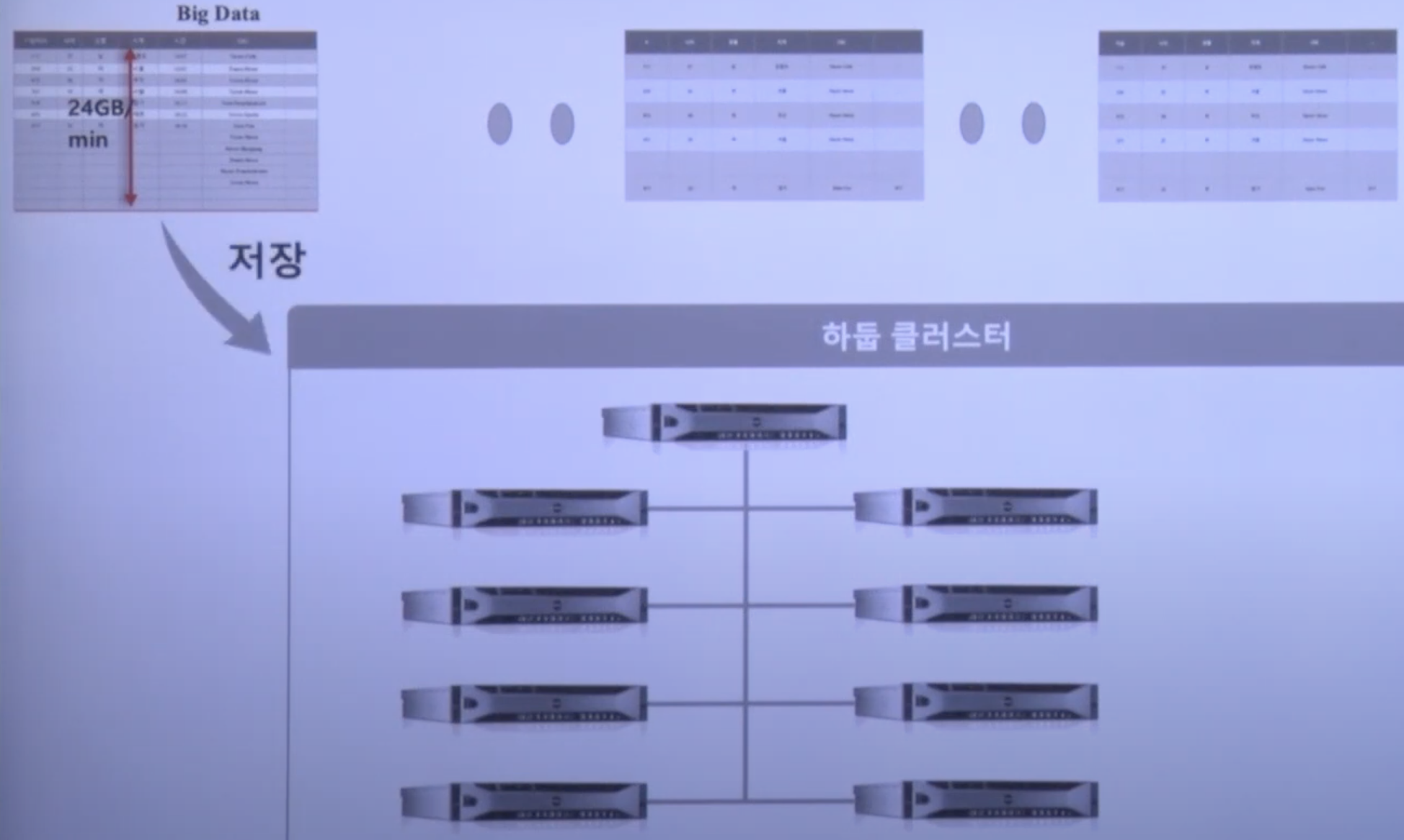
-
파일을 저장을 할 때, 하둡은 알아서 내부적으로 큰 파일들을 128Mb의 크기들로 쪼개게 된다
(즉, 매분 24Gb / 128Mb의 블락이 생성) -
아래 그림처럼 데이터를 분산 저장하게 되는데 DFS의 마스터 서버인 Name Node에는 데이터를 저장하지 않고 각 slave서버(8대)에 저장한다
-
데이터를 저장하게 되면 플랫폼 스스로 3개의 복사본을 분산 저장하게 된다, 이때 물론 노드는 서로 다른 노드에 저장한다
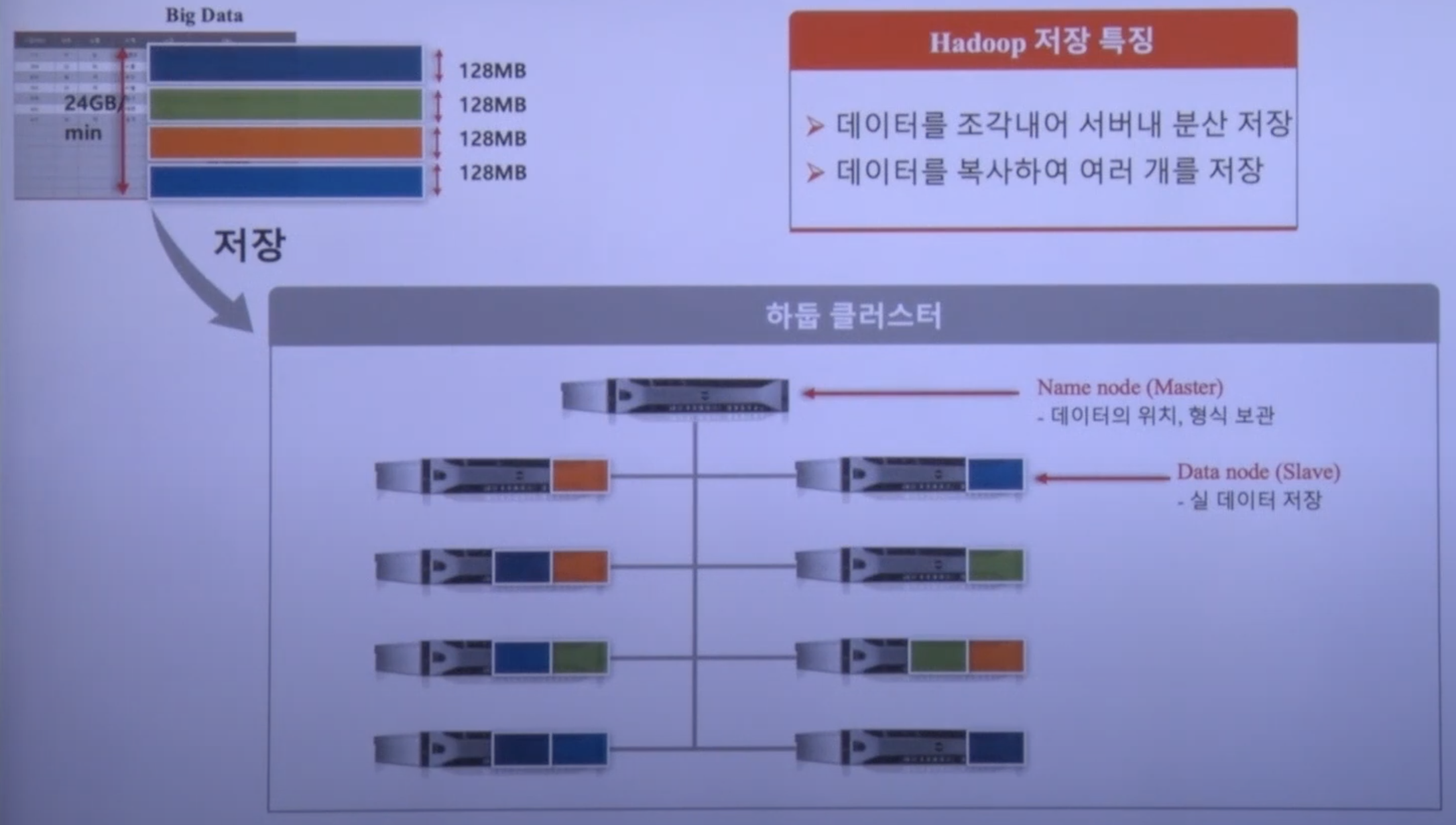
Name node(Master) : 데이터의 위치, 형식 보관
Data node(Slave) : 실 데이터 저장
- 데이터를 조각내어 서버내 분산 저장
- (조각낸) 데이터를 복사하여 여러개를 저장
- 즉, 3배의 데이터 공간 필요
슬래이브 노드의 장애 발생시? (중요)
만약, 위 사진에서 맨 왼쪽 위의 1번 노드가 장애가 발생하면 (네트웍이 끊기는 등) 실제 서버는 살아있지만 통신이 멈추게 되고, 해당 슬레이브 노드는 3초에 한번씩 마스터 노드에 하트비트(heartbeat)을 전송하는데 이 통신도 멈추게 된다. 네임노드는 1번 노드가 하트비트를 보낸지 일정 시간이 지났다고 판단되면 해당 슬레이브노드가 장애가 났다고 판단하게 된다
이때, 마스터 노드는 클라이언트가 어떠한 파일을 저장한다고 했을때 해당 파일명과 사이즈의 정보를 받아서 파일의 몇번째 블락은 몇번 슬레이브 노드에 저장을 하라고 정보를 주고, 해당 슬레이브 노드는 그 블락과 커넥션을 연결하고 블락을 받게 된다. 따라서 네임노드는 해당 블락이 어느 노드에 저장되어있는지 모든 정보를 알고 있으며 그 정보를 하트비트를 받을때 같이 슬레이브노드 DN(데이타노드)에서 임포트를 받게 되있다
따라서, 네임노드는 연결이 끊긴 1번 노드가 갖고있던 주황블럭을 갖고있는 슬레이브 노드를 알고있으므로 해당 노드인 2, 7번 노드 중 하나에게 해당 주황 블럭을 복사해서 다른 노드에 저장하도록한다. 이때 슬레이브의 DN(데이타 노드)들 끼리 통신을 하게되어 3개의 카피를 유지하게 된다
이러한 자동 복구 과정에서 운영자가 할 일은 전혀 없다. 이 과정은 모두 자동으로 작동하게 되어있다
만약 운영자가 1번노드를 복구하게 되면 1번 슬레이브노드는 다시 네임노드에 하트비트와 임포트를 주게 된다. 그러면 네임노드는 주황블락이 블럭 duplication설정 개수인 3개보다 4개로 오버카피된 것을 인지하고(혹은 적다면) 그 부분을 슬레이브 노드들끼리 통신해서 해당 부분을 수정해서 유지하도록 관리하게 된다
데이터 유실의 발생 가능성
- 특정 블럭이 저장된 3개의 데이터 노드가 동시에 혹은 매우 비슷한 시간에 장애 발생시 유실할 가능성이 존재
데이터를 3개의 카피로 저장하는 부분에 대한 정리
- EMC 등의 스토리지 업체들에서도 언급한 부분이지만 3배의 저장용량이 필요함에 불구하고 하둡으로 구성하는 것이 훨씬 비용이 적다
하둡은 클러스터를 구성할 때 커뮤니티 서버로 구성을 하는데 리눅스, 메모리, Cpu, 오픈소스 리눅스(OS), sata디스크 등 매우 저가의 장비로 구성하게 되며, 기존의 Dell, Oracle, EMC, HP 등의 솔류션 벤더들이 제공하는 고가의 장비를 사용하지 않는다
결과적으로 하둡이 같은 2페타데이터를 저장한다했을때 6페타를 저장하고 다른 벤더사들이 2페타를 저장한다 하더라도 비교가 되지않을 정도로 훨씬 저렴하게 제공을 할 수 있으며, 만약 해당 데이터가 단순 로그로 약간의 유실이 발생하더라도 크게 문제가 되지않는다면 duplication설정을 3이아닌 2로 설정하는 경우도 있다. 이외에도 데이터 저장공간을 절약하기 위한 방법들이 존재한다
마스터 서버의 장애 발생 및 버전 별 변화
기존 1.0버전에서는 마스터 서버에서 장애가 발생하면 말 그대로 서버에 장애가 발생하는것으로 이어지게 된다
단, 1.0에서 2.0으로 가면서 생긴 변화가 마스터 서버의 이중화로 마스터 서버의 장애에 대비하게 되었다
2.0에서 3.0으로 가면서 생긴 변화는 위에서 말한 duplication 설정을 3이 아닌 다른 설정 (보통 2)로 변경할 수 있게 된 부분이다
하둡 서버의 일반적인 스펙
-
DN의 메모리의 크기는 128, 256(보통), 512Gb 정도를 갖는다
-
cpu는 가장 저가이면서 효율적인 모델을 사용하며 코어수는 하이퍼쓰레딩을 켜서 16코어를 가상코어 포함 32코어를 갖는다
-
DN의 대스크 개수는 6개에서 12개 정도를 사용하며 하나의 디스크마다 2~3테라파이트 정도의 크기를 사용한다
(하나에서 6, 12페타 등 큰 크기를 갖기보단 적당한 크기로 여러대를 꽂아 사용하는 방식으로 구성한다)
블록의 지역성 (Data Locality)
어떠한 데이터를 128MB의 블럭으로 쪼개서 여러 슬레이브 노드에 분산 저장하였을 때 해당 데이터의 처리를 요청받게 되면 필요로 하는 블락을 갖고있는 노드들에 대해서 해당 노드의 TT(Task Tracker)가 자신이 갖고있는 로컬 데이터를 읽어서 처리를 진행하게 된다. 즉 추가적인 복사나 이동없이 배정 받은 노드에서 로컬데이터로 처리를 하는 개념 (Data Locality)
만약, 슬레이브 노드에 TT를 띄우지 않아서 DN만 존재하고 다른 슬레이브 노드에 존재하는 경우 네임노드가 TT가 존재하는 노드에 배정을해서 처리하도록 하는데 이때에도 렉내에서 처리하도록 하는 렉 로컬리티가 보장된다
블록 캐싱
어떤 데이터가 있을 때 해당 데이터에 유저의 ID가 로그로 남아 로그가 있다 가정
이때, 유저 Id의 마스터성 테이블을 보면 그 ID에 해당하는 유저의 이름이나 성별 등을 관계형 데이터베이스(RDB)에서 보게되면 JOIN을 해서 봐야한다. 이런 케이스 등을 캐시로 등록해서 볼 수 있다
-
데이터 노드에 저장된 데이터 중 자주 읽는 블록은 블록 캐시(block chace)라는 데이터 노드의 메모리에 명시적으로 캐싱할 수 있다
-
파일 단위로 캐싱할 수도 있어서 JOIN에 사용되는 데이터들을 등록하여 읽기 성능을 높일 수 있다
-
여기서 JOIN해야 할 마스터성 데이터가
크지않다라는 전제하에 가능한데, 크지않다의 기준은 데이타 노드도 데몬을 띄울 때 메모리 설정등을 해줄 수 있는데 이 메모리는 서버가 갖고있는 물리적 하드웨어 디스크의 스펙에서 데이터 메모리가 가지고 올라갈 메모리이다
따라서 이 메모리에 들어갈 수 있는 크기 이하의 데이터일 때 크지않다 할 수 있다 (일반적으로는 수십메가바이트)
네임노드 (Name node) 역활
-
전체 HDFS에 대한 Name Space 관리
-
DataNode로부터 Block 리포트를 받음 (하트비트랑 같이)
-
Data에 대한 Replication 유지를 위한 커맨더 역활 수행 (카피본 유지 관리)
-
파일시스템 이미지 파일 관리 (fsimage)
네임노드가 또 있는 어느 데이터 디스크에fsimage를 저장을하게 되어있다. 이 fsimage가 손상되면 하둡에 존재하는 대량의 데이터가 전부 날라갈 수 있으므로 fsimage를 잘 관리하는 방법들이 존재한다 -
파일시스템에 대한 Edit Log 관리
fsimage는 스냅샷이고 이후로 발생하는 변경들에 대해서는Edit Log에 남으므로 매우 중요한 파일이다
보조 네임노드 (SNN)
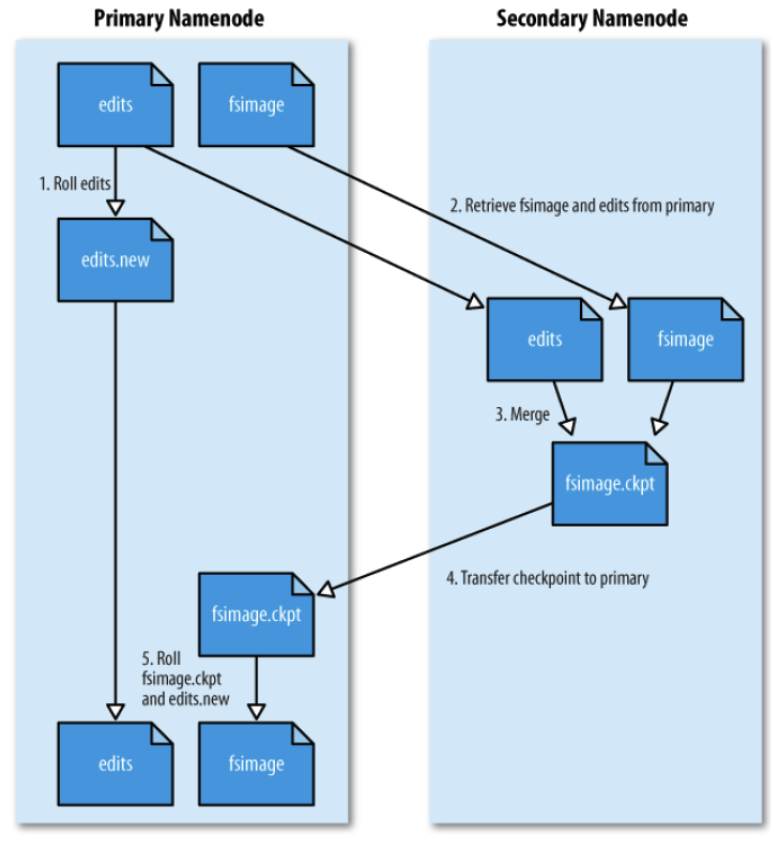
-
네임노드(NN)와 보조 네임노드(SNN)
- Active/Stanby 구조가 아니다
- 같이 구동하는 관계
-
네임노드 디스크 어딘가 남아있는 fsimage에 대해 네임노드가 fsimage를 최신상태로 갖도록 하기 위한 작업 수행
- 처음 구동시 fsimage가 meta정보와 Edit log를 확인해서 세팅을 한 후에 추가적인 시트 변경 등으로 변경사항이 Edit log에 누적되면 이를 fsimage와 병합하여 fsimage를 최신상태로 업데이트 해주는 역활을 하게 된다
- 일정 시간마다 혹은 edit 로그가 일정 사이즈 이상이 되면 실행
만약 구동중에 secondary Namenode(보조 네임노드)가 오류가 발생하게 되면 어떤 문제가 발생할까?
- 구동중에는 하둡상에 문제가 발생하지 않으나
edit log가 패치되지 않으므로 무한히 로그가 쌓이게 되고 나중에 하둡을restart하게 되면fsimage가 구동을 위해meta data와edit log를 읽고 세팅하는 과정에서 메모리 아웃 오브 익셉션이 발생할 수 있다
데이터 노드 (Data node)의 역활
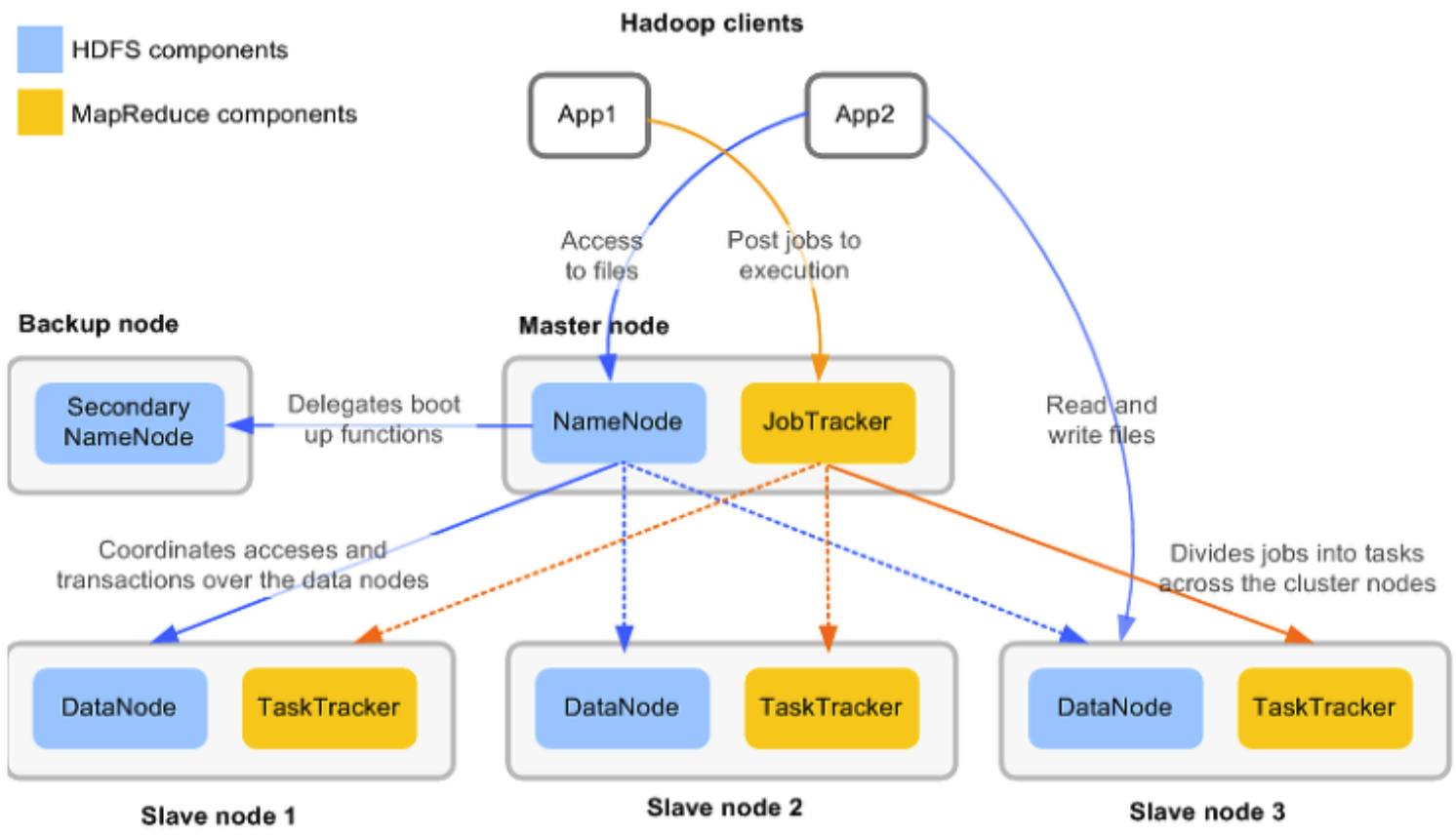
-
마스터 서버에게 DN이 갖고있는 데이터를 계속 report를 하는 형태이다
-
실제로 데이터는 Data Node의 물리적 로컬 파일시스템에 HDFS데이터가 저장되어 있다, NameNode는 전혀 데이터를 갖지 않는다
-
하나의 데이터 노드에 디스크가 6개가 꽂혀 있다고 가정하면 OS가 설치 되고 하둡 플랫폼 등이 설치하는 OS설치 영역에 관련된 디스크는 굉장히 작은 크기의 빠른 디스크로
레이즈 제로등의 레이드 구성을 하게 된다.
디스크 두개 정도를 사용해서 하나의 장애가 발생해도 실제 서비스에는 문제가 없도록 하는 방식이다 -
이에 반해 진짜 데이터가 저장되는 Data Disk들은 레이드 구성을 하지않는다. 레이드 구성을 함으로서 실제 사용할 수 있는 용량이 줄어들게 되므로 JBOD(Just Bunch Of Dist)구성으로 온전히 용량을 사용 할 수 있게한다
-
블록 리포트
- NameNode가 시작될 때, 그리고 HearBeat를 줄때마다 로컬 파일시스템에 있는 모든 HDFS 블록들을 검사 후 정상적인 블록의 목록을 만들어서 NameNode에 전송한다
- 만약 디스크가 나가게 되어 블록에 문제가 생기면 Data Node가 블록 스캔을 하다가 문제가 생겼다고 Name Node에 문제를 포함하여 블록 리포트를 보내게 된다.
그러면 Name node가 그 리포트를 통해 해당 블록을 지우고 새로운 노드에 복사하도록 하는 관리를 하게 된다
데이터 노드 블록스캐너
- 데이터 노드에서 쭉 스캔을 한 후에 문제가 있는 블록을 블록리포트에 명시하도록 해주는 역활
HDFS 읽기/쓰기 연산 처리 메커니즘
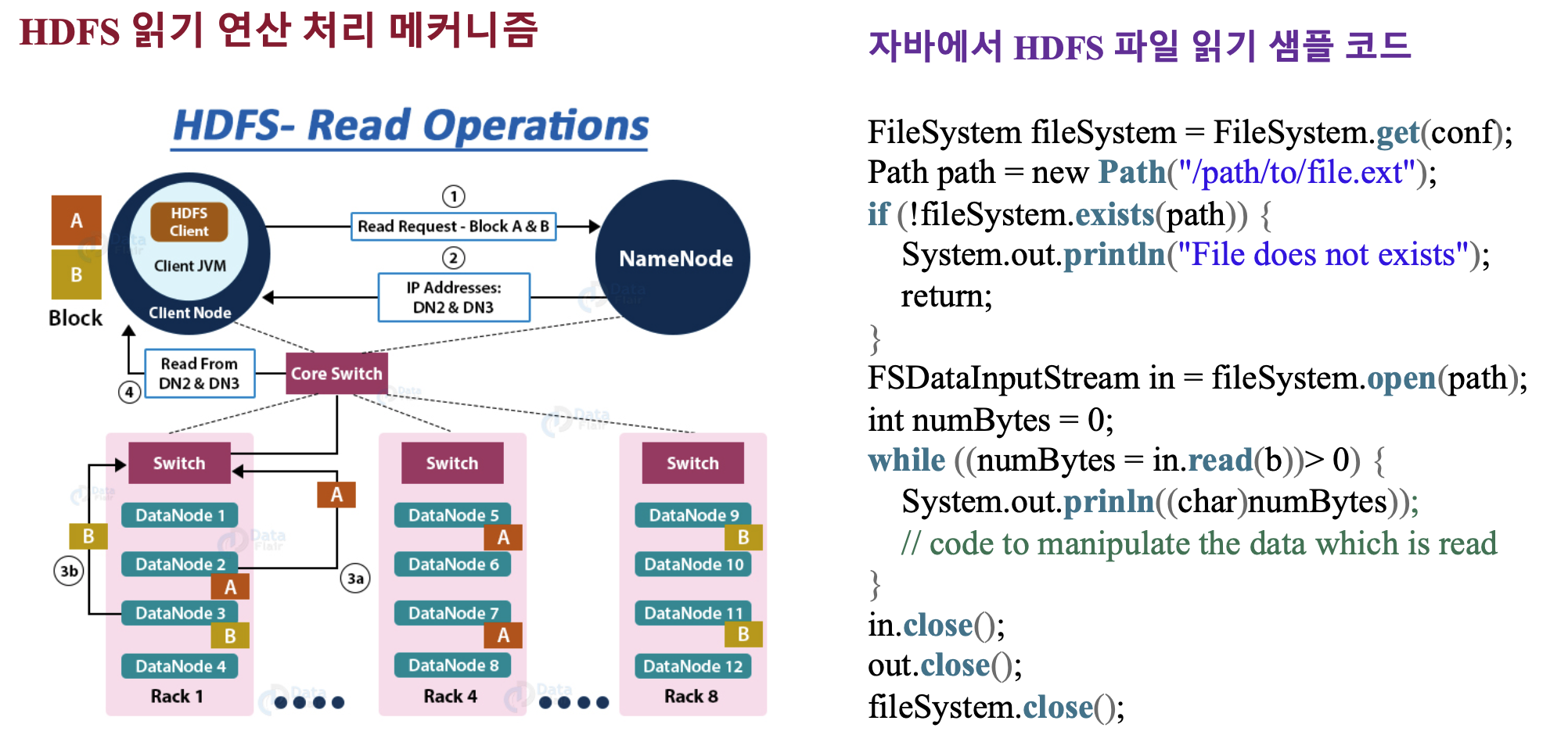
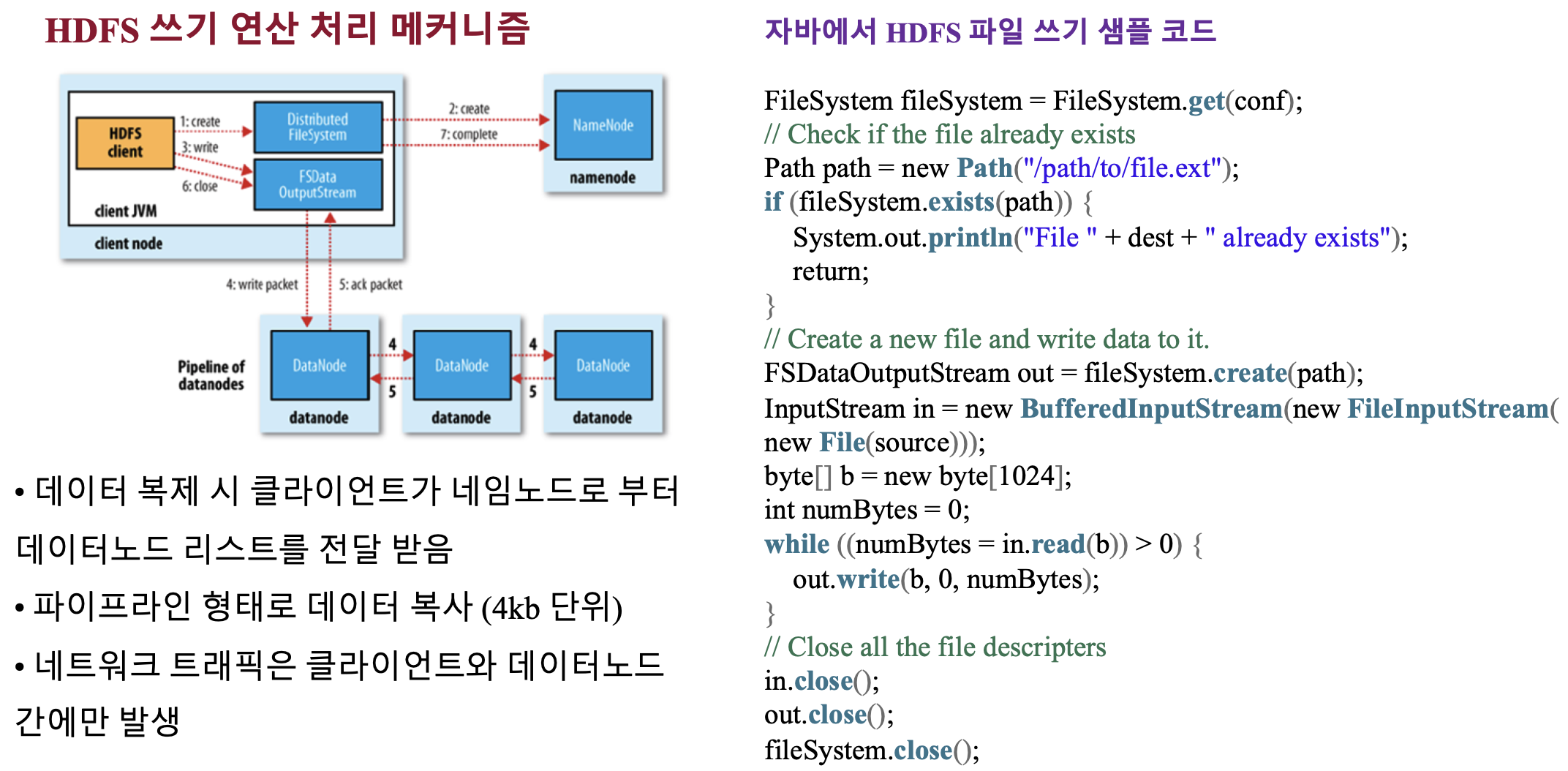
- 네임노드와 데이터 노드간의 통신은 하나의 데이터 노드와만 연결이 되어 있으며 복사본 3개를 유지하기 위한 데이터 노드들의 통신은 하나의 데이터 노드가 네임노드로 부터 정보를 받은 후에 자기들끼리 통신을 해서 이뤄진다
- 데이터 복제시 클라이언트가 네임노드로 부터 데이터노드 리스트를 전달 받는다
- 파이프라인 형태로 데이터 복사 (4bk 단위)
- 네트워크 트래픽은 클라이언트와 데이터 노드간에만 발생
클라이언트로 부터 복사 명령 하달 시
replication 3으로 복사할 때, 클라이언트가 어떤 파일을 하둡에 저장하겠다는 요청을 하면 네임노드가 해당 파일을 어디에 복사하라고 클라이언트에 전달을 하게 된다
그러면 클라이언트와 데이터 노드는 단 한대랑만 통신을 하고 있는데 해당 DN에 명령을 하달하고 DN은 자기들끼리 통신을 하여서 해당 파일의 3개의 카피를 하고 유지하게 된다 (즉, 클라 또는 네임노드에서 각 DN에 복사해주거나 명령을 주는 것이 전혀 아니다)


이해하기 좋은 글이었습니다. 감사합니다.