1. 링크드인에서 얻은 영감
이 프로젝트의 시작은 우연히 링크드인 피드를 보다가 얻은 영감이었습니다.
여러 개발자분들이 아이폰 '단축어' 기능을 활용해 기발한 방식으로 생산성을 높이는 사례들을 공유해주시고 계시더군요. 그 글들을 보면서 문득 "나도 저 기능을 활용해서 내 고민을 해결해 볼 수 있지 않을까?" 하는 생각이 들었습니다.
제 가장 큰 고민은 '정보 쌓아두기'이었습니다. 유튜브 영상이든 기술 블로그든, 읽고 끝나면 금방 잊어버리거나 "나중에 정리해야지" 하고 북마크만 쌓아두다가 다시는 안 보는 일이 반복되었습니다. 특히 Frontend나 AI 관련 글처럼 밀도가 높은 콘텐츠는 정리가 필수적인데도 말이죠.
그래서 링크드인에서 본 아이디어에 제 니즈를 더해, 아이폰에서 링크 한 번 공유하면 n8n이 내용을 긁어와 LLM으로 요약하고, 옵시디언에 마크다운 노트를 자동으로 만들어 주는 파이프라인을 구축하게 되었습니다.
이제는 "좋은 콘텐츠를 발견했다"는 생각이 들면, 고민 없이 공유 버튼만 누르고 나중에 옵시디언에서 편하게 리뷰하면 됩니다.
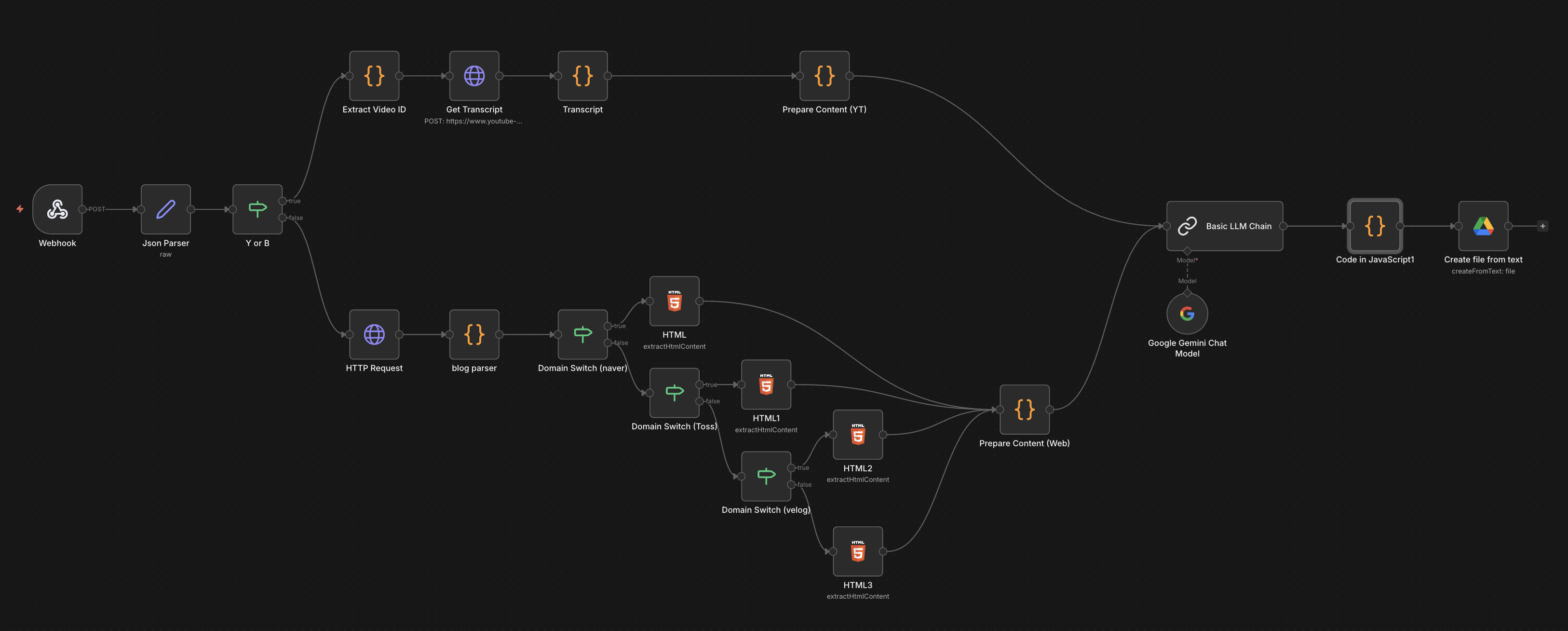
2. 전체 아키텍처 개요
자동화의 전체 데이터 플로우는 다음과 같습니다.
아이폰(공유) → 단축어(Webhook) → n8n(처리 및 요약) → Google Drive(저장) ↔ 옵시디언(Sync)
- 아이폰(브라우저/유튜브)에서 공유 → 단축어 실행
- 단축어가 현재 URL을 n8n 웹훅으로 POST
- Process (n8n):
- URL 분석 (유튜브 vs 일반 웹)
- 유튜브: Transcript API로 자막 추출
- 웹: HTML 파싱 후 본문 텍스트 추출
- 정제된 텍스트를 Google Gemini에 넘겨 "지식 관리용 마크다운"으로 요약
- 결과물을 Google Drive(옵시디언 Vault 폴더)에 .md 파일로 저장
결과적으로 "어디에서 링크를 공유하든, 옵시디언 Inbox에 표준화된 요약 노트가 쌓이는 구조"가 완성됩니다.
3. 아이폰 단축어
가장 먼저 iOS 단축어를 만들었습니다. 이 단축어의 역할은 단순합니다. 공유 시트에서 넘어온 URL을 n8n에게 던져주는 것입니다.
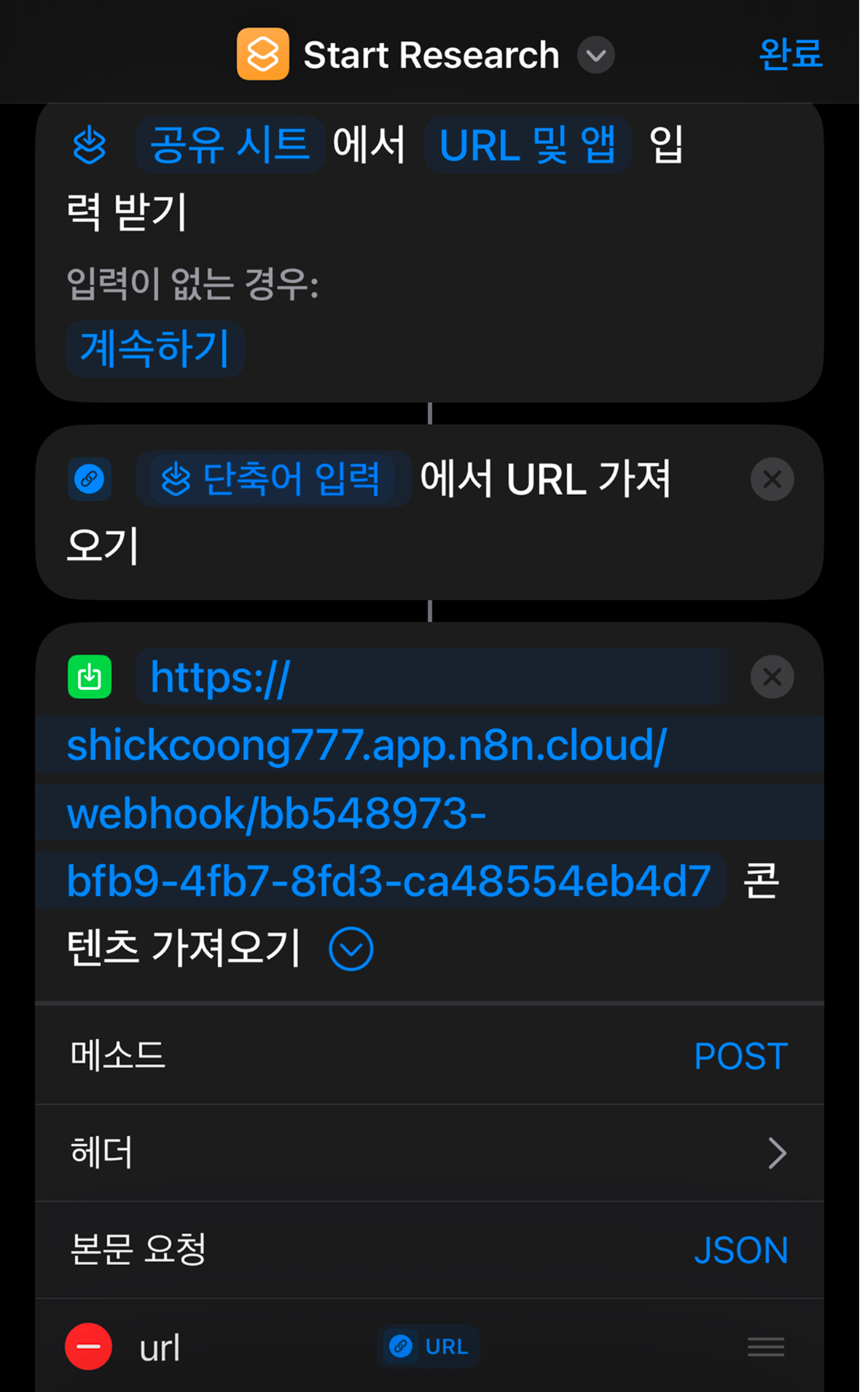
설정 순서:
- 단축어 앱에서 새 단축어 생성 → 설정에서 "공유 시트에서 보기" 활성화
- 입력 타입은 "URL"로 지정
- 액션 1: "단축어 입력에서 URL 가져오기"
- 액션 2: "URL의 콘텐츠 가져오기" (HTTP Request)
- URL: n8n Webhook URL (Production)
- Method: POST
- Body: JSON → {"url": "입력된 URL 변수"}
이렇게 하면 유튜브 앱이나 브라우저에서 "공유 → 단축어 실행" 시 해당 URL이 n8n으로 전송됩니다.
4. n8n 워크플로우
n8n에서는 들어온 URL이 유튜브인지, 일반 블로그인지 판단하여 처리 방식을 다르게 가져갑니다.
4-1. 웹훅 및 분기
맨 앞단에는 Webhook 노드를 두고 POST 요청을 기다립니다. 들어오는 데이터는 {"url": "https://..."} 형태입니다.
그다음 IF 노드를 사용하여 URL에 youtube.com 혹은 youtu.be가 포함되어 있는지 확인합니다.
- True: YouTube 브랜치로 이동
- False: Web Page 브랜치로 이동
각 브랜치의 끝에서는 동일한 스키마(type, content, title, url)로 데이터를 통일시켜, 이후 LLM 노드가 헷갈리지 않게 설계했습니다.
5. 유튜브 브랜치: 영상 ID와 자막 추출
유튜브 영상은 내용을 텍스트로 바꾸는 것이 핵심입니다.
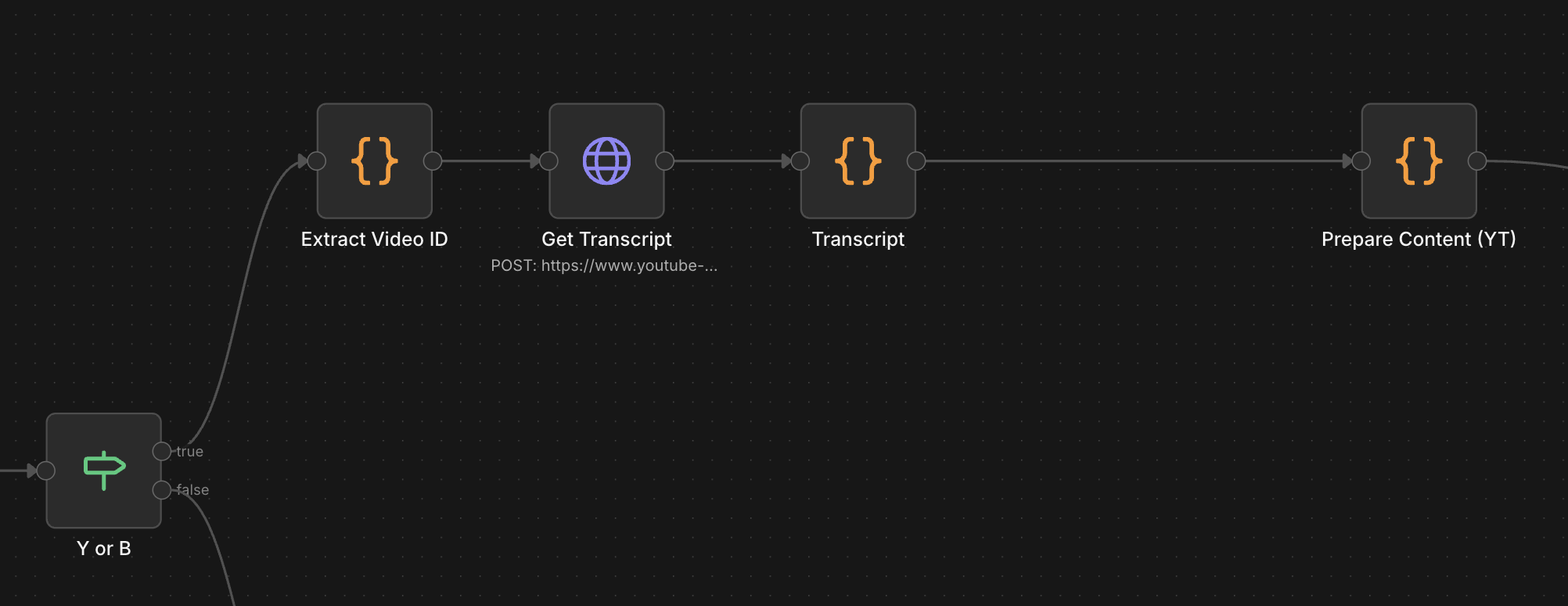
- Extract Video ID: Code 노드(JS)를 이용해 URL에서
v=뒤의 ID나 단축 URL의 ID를 파싱합니다. - Get Transcript: YouTube Transcript API를 호출해 자막을 가져옵니다.
- Transcript(데이터 정제): 자막 세그먼트들을 하나의 긴 텍스트(fullTranscript)로 합칩니다.
- Prepare Content(Youtube 포메팅):
- type: "youtube"
- content: 자막 전체 텍스트 (fullTranscript)
- title: 영상 제목
6. 블로그 브랜치: 블로그 스크래핑
웹페이지는 사이트마다 구조가 달라서 조금 까다롭습니다.
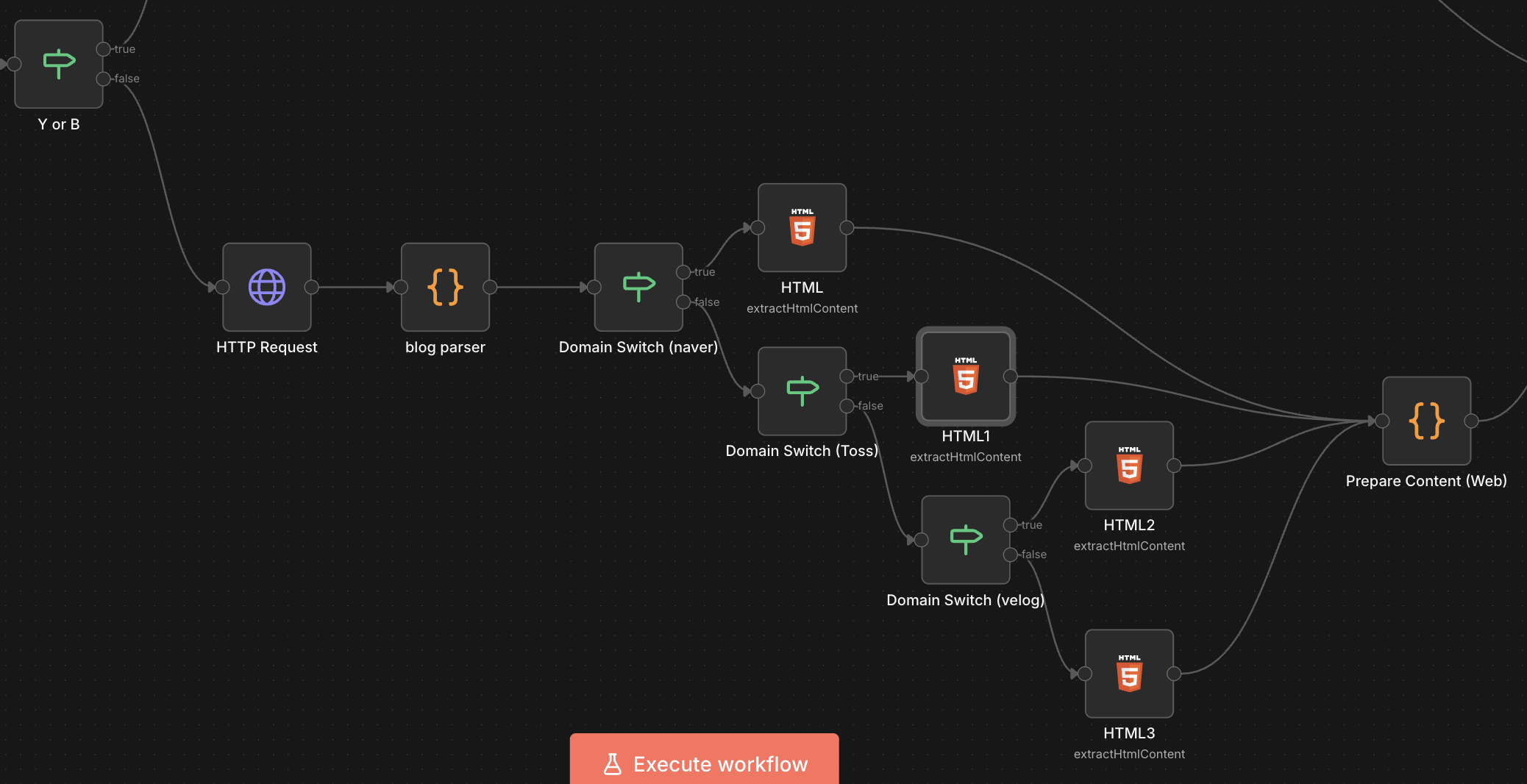
- HTML Request: HTTP Request (GET)로 원본 HTML을 긁어옵니다.
- 콘텐츠, 도메인 나누기: 긁어온 HTML에서 콘텐츠와 도메인을 추출합니다.
- 도메인별 Selector 분기:
- 단순히 body 태그를 긁으면 메뉴나 광고까지 다 딸려옵니다.
- velog.io, tistory.com, naver.com 등 자주 가는 사이트의 도메인을 추출해 Switch 노드로 분기했습니다.
- Velog: div.atom-one
- Naver: div.con_view
- Toss: div.css-lvn47db
- 그 외: article, main, .post 등 일반적인 본문 태그 시도
- Prepare Content(Blog 포메팅): HTML 태그를 제거하고 순수 텍스트만 남겨 content 필드에 저장합니다.
7. LLM으로 요약 (Gemini)
이제 가장 중요한 단계입니다. 정제된 텍스트를 Google Gemini에게 넘겨 옵시디언에 넣기 좋은 마크다운 포맷으로 변환합니다.
7-1. 프롬프트 엔지니어링
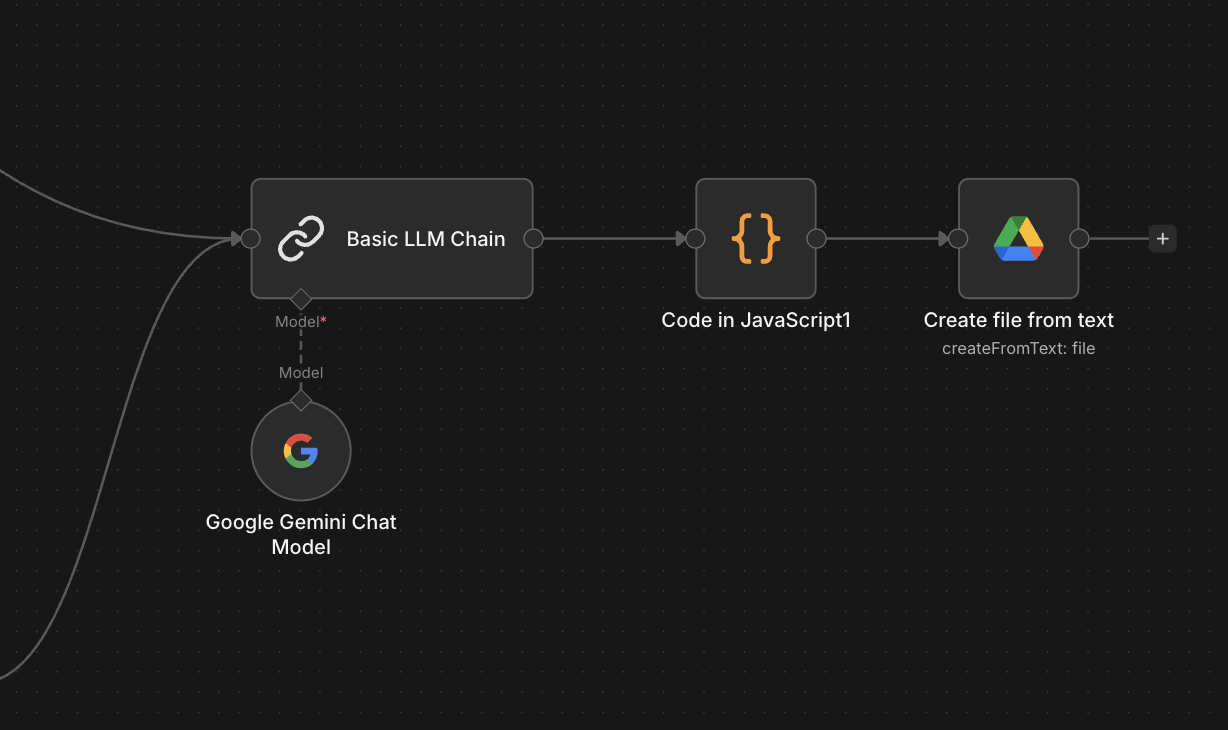
n8n의 Basic LLM Chain 과 Google Gemini Chat Model(Flash 3.0 preview)을 사용했습니다. 프롬프트는 다음과 같이 구성했습니다.
User 프롬프트
다음은 {{ $json["type"] === "youtube" ? "유튜브 영상" : "웹페이지/문서" }}의 전체 내용입니다.
이를 읽고 옵시디언에 저장할 마크다운 노트를 생성해주세요.
요구사항:
- 한국어로 작성
- 코드블록 기호(```) 없이 순수 마크다운 본문만 출력
- 구조:
---
title: "{{ $json["title"] || "Untitled" }}"
source: "{{ $json["url"] }}"
created: {{ $now }}
type: {{ $json["type"] }}
tags: [reading, summary]
---
# 핵심 요약
- 3~5개의 핵심 포인트
# 상세 내용
- 중요한 개념, 정의, 설명을 bullet point로 정리
# 인사이트 / 할 일
- 내가 실행할 액션이나 느낀 점 정리
본문 텍스트:
{{ $json["content"] }}System 프롬프트
당신은 사용자의 지식 자산화를 돕는 비서이다. 긴 텍스트를 받아 한국어로 정리된 마크다운 노트를 만들어라. 7-2. 파일명 생성
생성된 마크다운 내용 중 title: "..." 부분을 정규식으로 다시 추출하여, 파일명으로 사용할 safeTitle (특수문자 제거, 슬러그화)을 만듭니다.
const items = $input.all();
function slugify(str) {
return (str || "untitled")
.toLowerCase()
.replace(/[^a-z0-9가-힣]+/g, "-")
.replace(/(^-|-$)+/g, "")
.slice(0, 80);
}
return items.map(item => {
// LLM 출력이 통째로 들어있는 필드 이름(예: text, result 등)에 맞춰서 바꾸세요.
const md = item.json.text || item.json.result || "";
// --- 블록 안에서 title 라인 찾기
let title = "Untitled";
const match = md.match(/title:\s*"([^"]+)"/);
if (match && match[1]) {
title = match[1];
}
return {
json: {
...item.json,
markdown: md, // 나중에 파일 내용으로 쓸 필드
title, // 파싱한 제목
safeTitle: slugify(title),
},
};
});
8. Google Drive에 저장 (옵시디언 Sync)
마지막으로 파일을 저장할 차례입니다. 저는 옵시디언 볼트를 Google Drive로 동기화해서 쓰고 있습니다.
- 인증: 개인 OAuth 대신 Service Account를 사용하여 인증 만료 걱정 없이 연결했습니다.
- 파일 생성: Google Drive 노드의 Create file from text 액션을 사용합니다.
- File Name:
{{ $json["safeTitle"] }}.md - Content: Gemini가 뱉어준 마크다운 전체
- File Name:
- 완료: n8n이 성공하면, 잠시 후 제 옵시디언에 정리한 파일이 생성됩니다.

9. 마치며: 정보 소비 패턴의 변화
이 워크플로우를 구축한 뒤로, 정보를 대하는 방식이 완전히 달라졌습니다.
- "언젠가 봐야지"가 아니라 "지금 요약해서 저장해두자"가 되었습니다.
- 긴 영상이나 글을 다시 처음부터 볼 필요 없이, 요약된 핵심과 내 인사이트를 먼저 훑어볼 수 있습니다.
- 모든 외부 지식이 동일한 템플릿으로 저장되니 검색과 관리가 훨씬 수월합니다.
처음 구축할 땐 n8n 설정이 조금 복잡해 보일 수 있지만, 한 번 만들어두면 매일매일의 생산성이 달라집니다. 여러분도 자신만의 '지식 파이프라인'을 한번 구축해 보시길 추천합니다.

6개의 댓글

좋은 정보 감사합니다! 단축어로 트리거시키는게 신선하네요.
어디서 영감 받았는지도 적어주셔서 재미있게 읽었습니다.
n8n을 상시 사용하지 않으신다면,
n8n cloud 비용대신 Lambda가 비교적 더 저렴하니
Lambda를 호출해 n8n CLI command로 workflow를 실행하도록 하는 방법도 있습니다!
(만약, Lambda로 n8n을 사용하실려면 n8n은 용량이 커서 이미지로 빌드한 다음 사용해야 합니다.)
참고용)
- n8n CLI : https://docs.n8n.io/hosting/cli-commands/#start-a-workflow
- n8n CLI + Lambda 조합 Dockerfile : https://github.com/dst03106/issue-collector/blob/main/lambda/Dockerfile

너무 좋은 아이디어네요! 영감 받아서 저도 여기서 자잘하게 옵시디언을 노션으로 바꾼다던지, 저만의 개인 마크다운 문서 저장소로 이동시키도록 설정해서 사용해보고 있습니다 :) 무엇보다 활용성이 굳이 프로그래밍에 국한되지 않아도 된다는 점이 너무 좋네요 ㅎㅎ 한가지 걱정되는 게 저 URL에 인증을 걸어두셨나요? 아무나 사용할 수 있을 거 같아 걱정되네요
요즘 저도 자잘한 지식들 생기면 항상 어디에 저장해두어야지 하고 매번 안하게 되는데... (쓰던 메모앱을 키기 귀찮다던가... 정리하기 귀찮다던가...)
생산성 높이는 데에 너무 좋은 아이디어인 것 같아요.
저도 옵시디언 즐겨쓰는데 한 번 연동 시도해보아야할 것 같습니다 :)
인사이트 공유 감사합니다 !