
- 전체보기(13)
- transformer(5)
- 데이터 분석(3)
- 딥러닝(3)
- 데이터 전처리(2)
- LLM(2)
- Generative AI(1)
- Anomaly Detection(1)
- 데이터 시각화(1)

TranAD
TranAD (Transformer-based Anomaly Detection)는 다변량 시계열 데이터(Multivariate Time Series Data)의 이상 탐지 성능을 혁신적으로 개선한 모델트랜스포머의 강력한 어텐션(Attention) 메커니즘을 오토인코더(
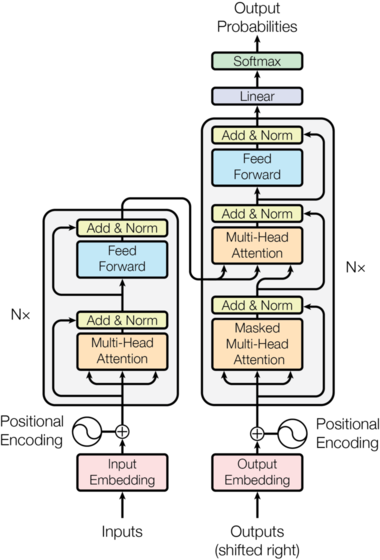
Transformer의 기본 구조
트랜스포머의 기본 구조는 인코더(Encoder)와 디코더(Decoder)라는 두 가지 핵심 블록을 여러 개 쌓아 올린 형태입력 계층인코더와 디코더에 데이터가 들어가기 전에, 두 가지 중요한 전처리 과정이 수행입력 임베딩 (Input Embedding): 단어(토큰)를
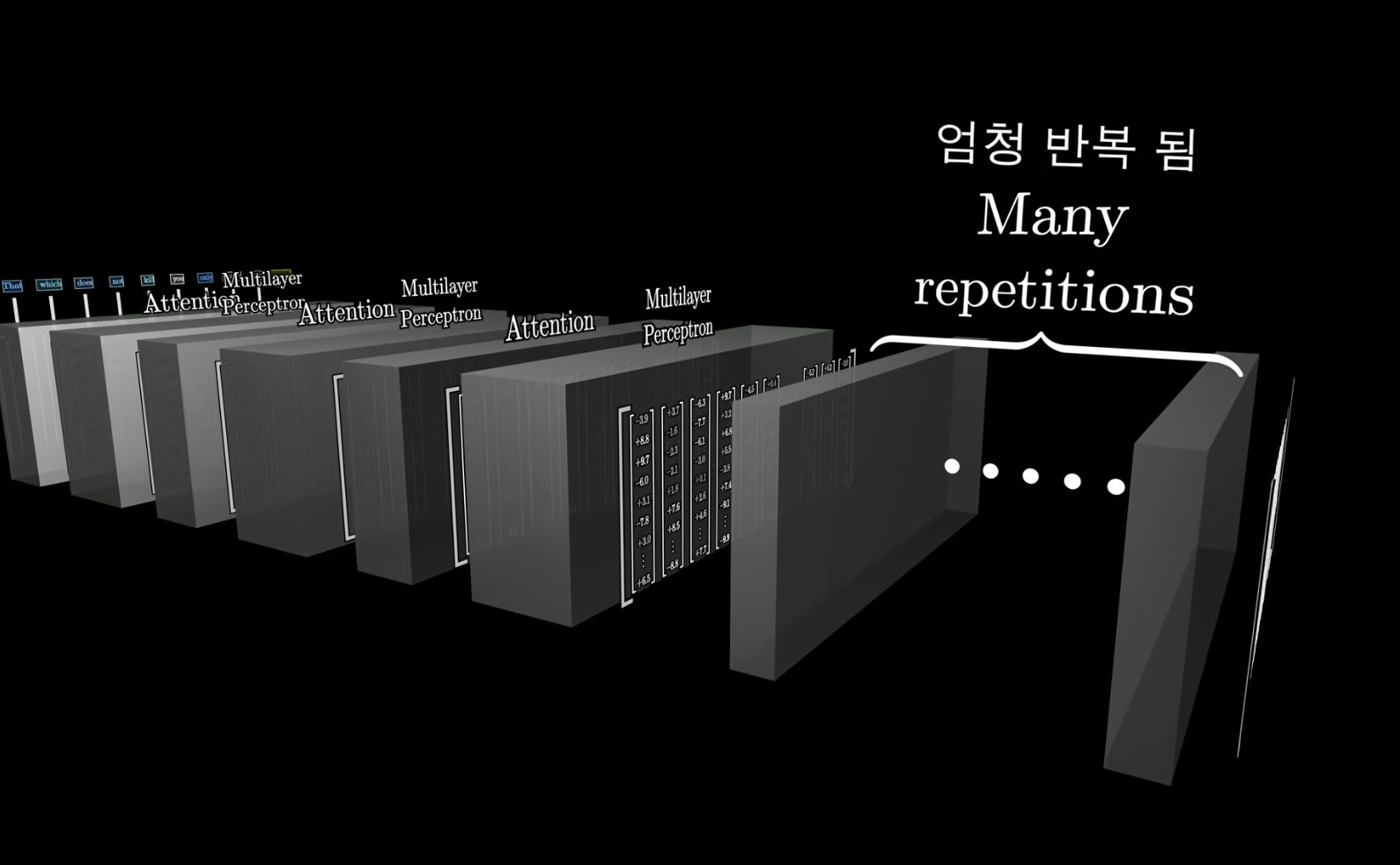
Transformer - Multilayer Perceptron(MLP)
Attention block모든 단어는 고차원 공간에 임베딩 되어 있음 ! 각 단어들은 Attention 블록을 거치면서 다양한 문맥을 가질 수 있도록 업데이트 됨MLP어떤 사실 정보를 저장하기에는 MLP쪽이 더 많은 정보를 가지고 있음각 임베딩 데이터들이 MLP 블록
Transformer - Attention
attention 메커니즘 문맥에 따라 단어는 각각 다른 의미를 가지게 됨 각 단어를 임베딩 스페이스로 보냄 (각 단어는 각각 문맥적인 의미는 갖지 않음) 임베딩 스페이스로 옮긴 뒤, 각각의 문맥적인 의미를 파악하게 됨 문맥을 통해 단어 A를 실제 의미로 어디로 얼마
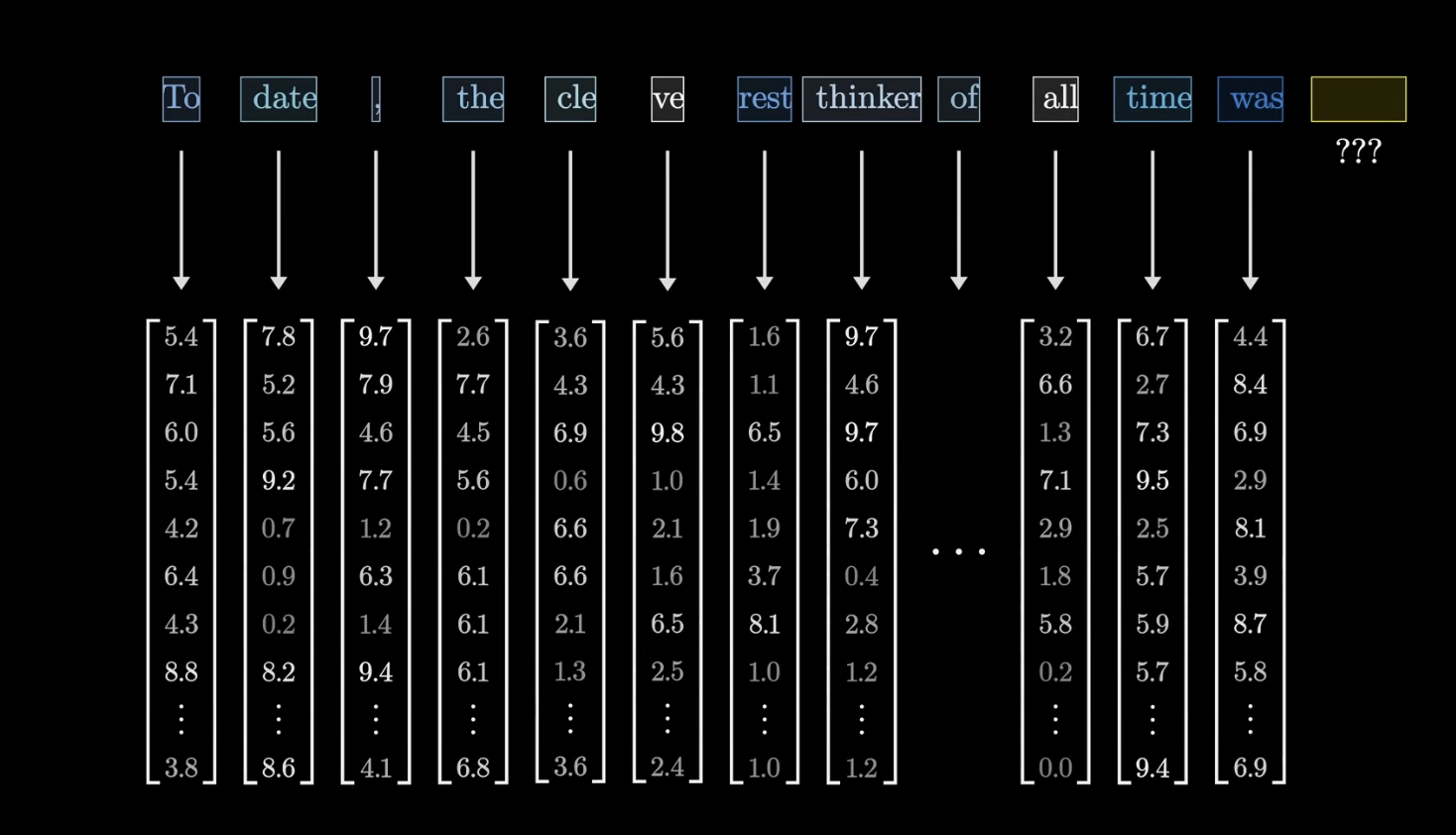
GPT - Transformer 로직 흐름
데이터의 가장 작은 단위를 벡터화 한 것으로 이해하면 쉬움의미가 비슷한 단어들은 상대적으로 비슷한 위치에 있을 수 있음학습 가능한 매개변수 (Weight)로 단어 벡터간의 연산을 진행해 output을 도출한다.이때 비슷한 단어끼리는 양수, 서로 다른 의미를 가진 단어끼
데이터 먼징 : 문자열 다루기, 정규표현식, 데이터 정리
상태가 안좋은 데이터? 데이터 형식 문제 영어 대소문자가 엉망 무의미한 공백이 있는 데이터 실제 데이터에 문제가 있는 경우 중복 특수하거나 예외적인 값이 존재 데이터를 전처리 하기 전에 > 문자열 데이터를 사용한다면 데이터를 열어 직접 확인하라 설
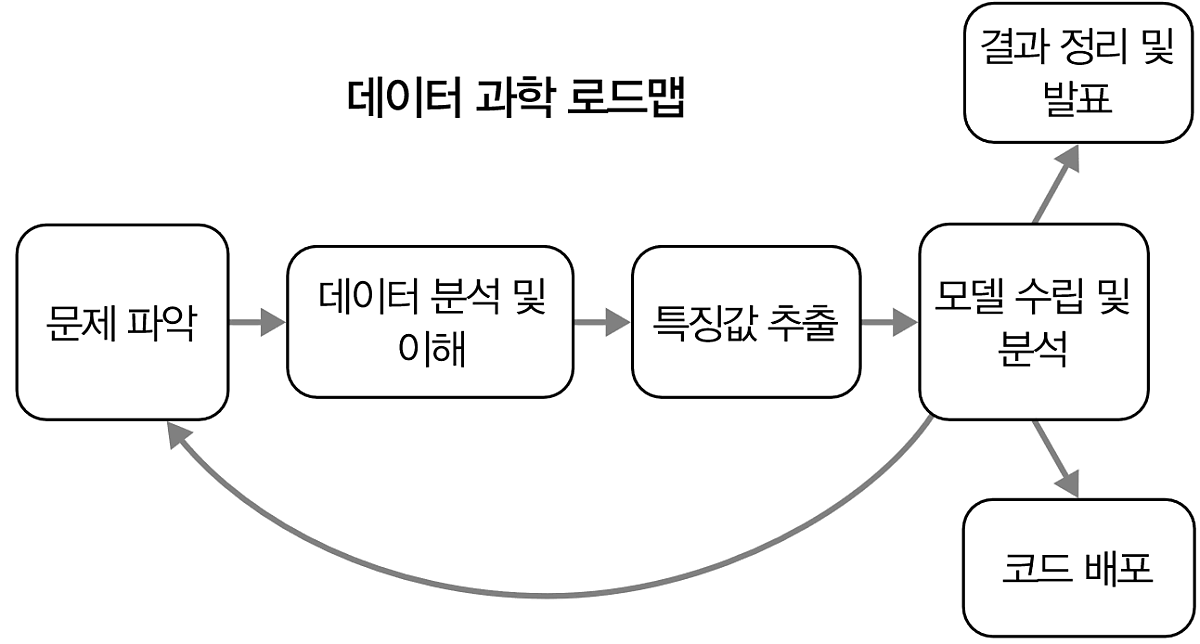
Data Science 큰 그림
데이터 과학의 로드맵은 다음과 같다.모델 수립 및 분석 단계에 있다가도 문제 파악 단계로 옮겨갈 수 있다.지금 푸는 문제가 잘 정의된 실제로 의미있는 문제인지 계속 고민해야 한다.결과정리 및 발표와 코드 배포 두가지 방법으로 나뉠 수 있다.둘다 하는 경우도 있다!최종
[Streamlit] 기본 문법
프로젝트를 진행할 때, 만든 모델을 다른 사람에게 공유하고, 보여주고 싶은 경우 사용할 수 있는 대시보드 간단하게 실행 가능한 도구 = streamlit python으로 web 구현하기 특정 버튼 누를 때 데이터 불러오기 -> 데이터 반복으로 불러오기 X -> 중간에
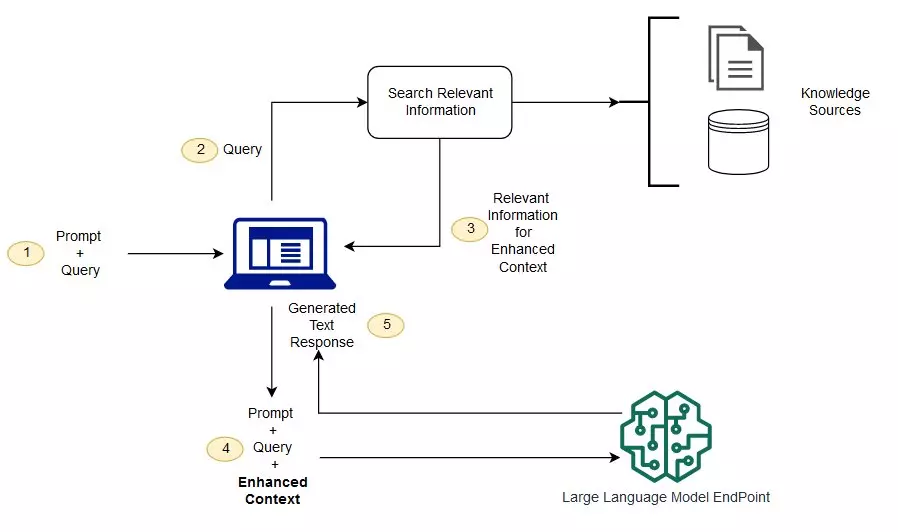
LLM이란?
LM (언어 모델, Language Model) 이란, 인간의 언어를 이해하고 생성하도록 훈련된 일종의 인공지능 모델이다. 언어 모델의 품질은 크기나 훈련된 데이터의 양 및 다양성, 훈련 중에 사용된 학습 알고리즘의 복잡성에 따라 달라진다.LLM (거대 언어 모델, L
Artificial Neural Networks with Keras
적어도 입력이 둘은 있어야 출력 1개가 나온다. (뉴런이 활성화 된다)TLU(Threshold Logi unit), LTU(linear threshold unit)TLU가중합을 계산한다 (input은 이진이 아니라 숫자)step function으로 분류한다.heavis
Feature Demention
: 샘플 차원이 커지면 커질수록 해당 데이터를 잘 대변하지 못함을 말한다. (샘플 밀도가 너무 낮아짐)새로운 인스턴스 넣었을 때 주변 인스턴스가 넘 떨어져있어 그 인스턴스 설명 불가능오차 커질 수 있음데이터가 주변에 너무 없어서 과도하게 다른 인스턴스와 연결해 설명이
데이터 정규화
데이터 정규화는 데이터의 스케일을 조정하여 모델의 학습을 개선하고 예측 성능을 향상시키는 과정이다. 주로 머신러닝 모델에서 사용된다. 데이터를 특정 범위로 스케일링합니다. 일반적으로 0과 1 사이의 범위로 변환된다.$$X{norm} = \\frac {X-X{min}}{
Feature Selection
Feature selection은 모델의 성능을 향상시키고 모델의 복잡도를 줄이기 위해 중요한 특성만을 선택하는 과정이다. Feature selection에는 여러가지 알고리즘이 있다. Filter Methods에서는 특성과 타겟 간의 통계적인 관계를 기반으로 특성을