Autoencoder 정의
오토인코더를 한마디로 정의하자면 딥러닝 기반의 비지도학습 방법이다.
Input 데이터의 차원을 축소하는 Encoder와 이를 다시 복원하는 Decoder로 이루어져있다. 입력과 출력이 똑같은 구조로 무엇을 하나 싶을 수 있지만 활용범위가 굉장히 넓다.
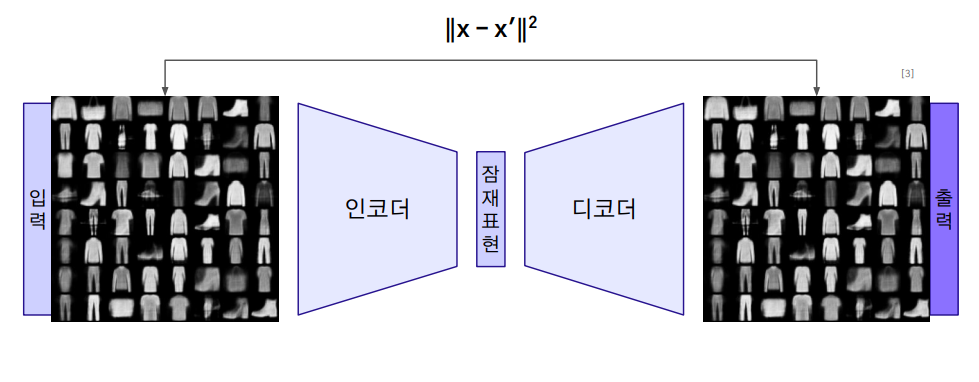
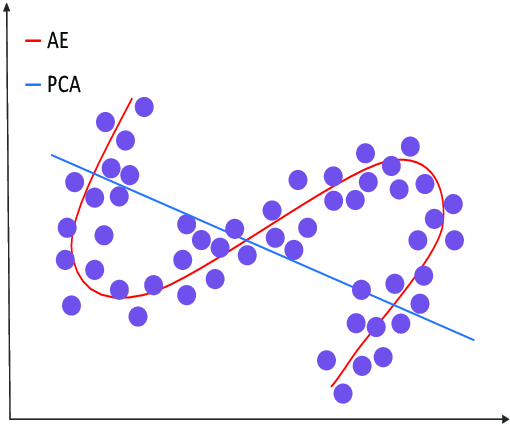
주로 사용되는 것은 PCA와 같은 차원축소 방법인데, 비선형적인 데이터를 차원축소 할 수 있다는 차이점이 있다. 그래서 이미지와 같은 비정형 데이터를 차원축소 하는데 사용한다.
Autoencoder 활용
이러한 오토인코더는 2가지로 주로 사용된다.
첫번째는 위에서 말했듯이 비선형 데이터의 차원축소이고 다른 하나는 생성형 모델이다.
생성형 인공지능 시대에서 stable diffusion, Style GAN 등 실생활에 사용할 만큼 좋은 이미지 생성 모델이 나왔는데, 그러한 생성 모델 중 하나인 VAE(Variational AutoEncoder, 변분인코더)는 오토인코더와 동일한 구조를 가진다.
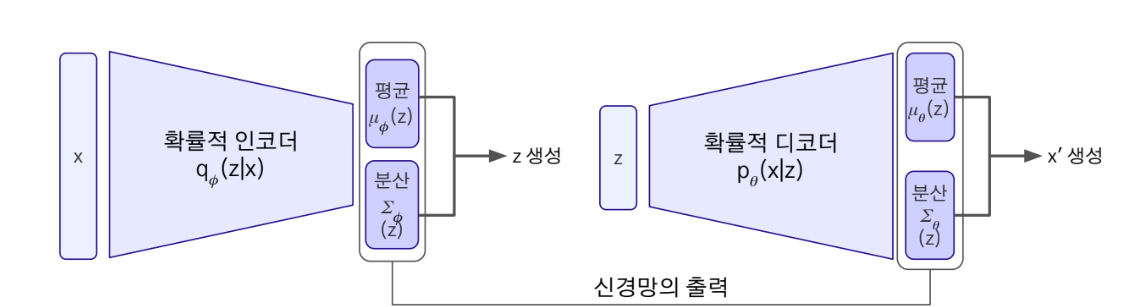
잠재벡터는 정규분포를 따른다. 즉, 잠재벡터를 정규분포에서 추출할 수 있다는 의미이다. Autoencoder에서는 축소한 잠재벡터의 분포를 다루지는 않았는데 VAE는 이를 정규분포를 따르게 만든다.
VAE의 loss function으로 ELBO(Evidence of Lower Bound)를 사용하는데, 현재 모델이 우리가 가지는 데이터를 가장 잘 설명하는지를 나타내는 함수이다.
VAE의 구조 자체는 Autoencoder와 같지만 그 내용은 사실 많이 다르다. Autoencoder는 기존의 데이터의 특징을 잘 나타내는 잠재벡터를 추출하지만 VAE는 특징을 나타내는 잠재벡터가 아니라 output이 기존의 이미지와 유사한 분포가 되도록 하는 잠재벡터를 뽑아낸다. Input과 가장 유사하게 생성할 데이터 분포의 sampling 한 것이 z이며 이를 통해 Output이 Input과 유사한 데이터를 내뱉도록 한 생성형 모델이다.
마무리
Autoencder는 신경망 구조의 비지도 학습으로 인풋과 아웃풋이 같도록 encoder,decoder 구조를 가지고 있다. 인풋과 아웃풋이 같기에 인풋의 고차원 데이터를 저차원으로 축소하여 사용할 수 있어 비선형적인 데이터의 차원축소로 사용된다. 여러가지 변형된 형태가 있는데 그 중 변분인코더는 생성 모델로도 사용된다.
