Validation을 선택할 때, 똑같은 데이터로만 split 할 경우 성능을 측정하는 일반화 성능이 떨어진다. 왜냐하면 train 데이터를 랜덤으로 추출한 80%의 데이터로 정할 때와 다른 데이터 80%를 학습할 때의 성능이 다를 수 있기 때문이다. 마찬가지로 validation 을 랜덤으로 추출한 20%의 데이터로 정할 때, 똑같은 데이터로만 검증하면 나머지 80%의 데이터로는 검증할 수 없어서 성능이 validation 데이터에 따라 많이 다를 수 있다
K-fold cross validation
이를 위해 K-fold cross validation을 사용한다. K=5라면, validation을 겹치지 않도록 다른 validation data로 나누어서 5번 학습을 시켜보는 것이다. 학습된 모델을 또 학습하는 것이 아니라, 초기화한 모델을 5번 학습하는 실험을 하는 것이다. 이 5번의 실험 중에서 가장 높은 성능이 나온 모델들을 앙상블하거나, Top1의 모델만을 선택할 수도 있다.

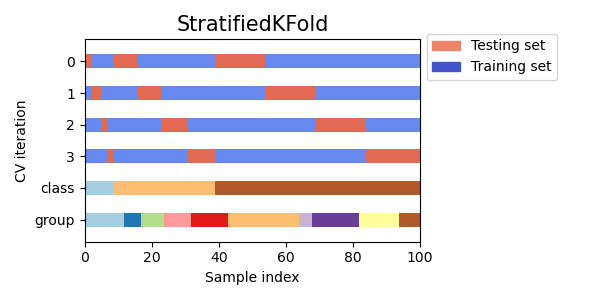
이 그림에서 처럼 0,1,2,3 을 K=4 인 kfold validation 이고
class는 3개의 분포가 랜덤으로 추출 된다. group 또한 여러 group들이 같은 folder안에 들어가게 된다.
import matplotlib.pyplot as plt
import numpy as np
from matplotlib.patches import Patch
from sklearn.model_selection import (
GroupKFold,
GroupShuffleSplit,
KFold,
ShuffleSplit,
StratifiedGroupKFold,
StratifiedKFold,
StratifiedShuffleSplit,
TimeSeriesSplit,
)
kf = KFold(n_splits=5)
for train_index, test_index in kf.split(X):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
model.fit(X_train, y_train)
model.score(X_test, y_test)K-fold stratified
이를 변형한 여러가지 방법들이 있다. K-fold stratifed cross validation은 정답 label 혹은 target의 분포가 전체 데이테셋과 동일하도록 하는 방법이다.
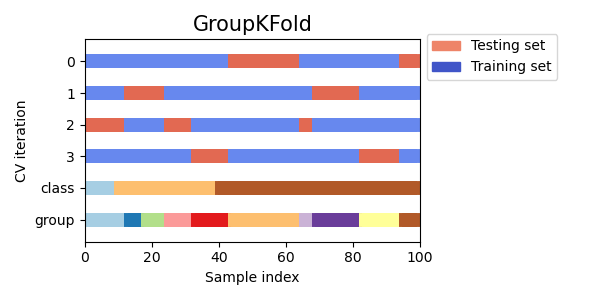
Group K-fold
같은 그룹이 같은 fold에 들어가도록 학습한다 하지만 검정을 할 때는 다른 그룹의 데이터로 검증을 하게 된다. 일반화 성능을 올리도록 하는 검증 방법이다.
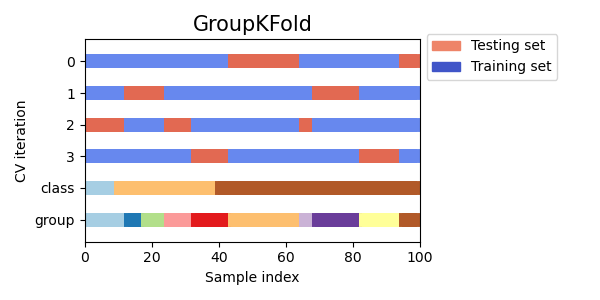
Startified Group K-fold
Class별로 그룹화 한 뒤, Class별로 일정한 비율로 train set을 구축한다.
따라서 모든 Class의 분포가 전체 dataset과 같도록 학습하는 방식이다.
비율이 같다는 것이지 Class 개수가 동일하다는 것은 아니다 예를 들어, class1이 전체의 80% class2가 전체의 15% class3가 전체의 5%인 불균형한 데이터라고 하면 train 데이터와 vlidation 데이터도 이와 같은 비율이 동일하게 되는 것이다.
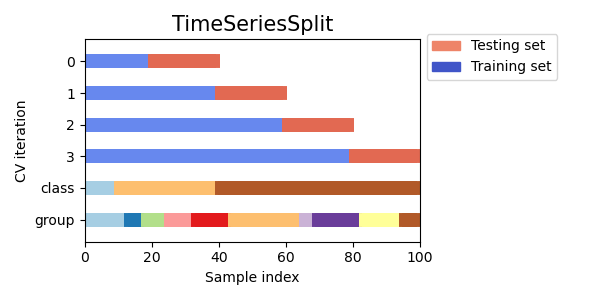
Time Series Split
시계열 데이터의 경우 시간에 따라 데이터가 달라지므로, 랜덤으로 split 하면 안된다 시계열 데이터를 위해 데이터를 누적해가면서 혹은 일정 시간 간격으로 split을 하여 train, validation 을 나눈다.