Disentangled Person Image Generation
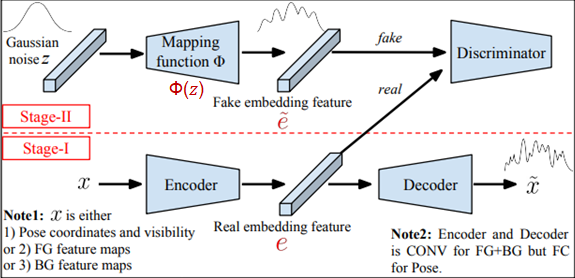
이 논문은 포즈, 전경, 배경을 각각 분리해서 embedding feature를 학습시킨 다음, 같이 디코딩하여 사람 이미지를 생성하는 방법을 소개합니다.
논문
Github
https://github.com/charliememory/Disentangled-Person-Image-Generation
1. Introduction
Domain/Issue
- 사람의 사실적인 이미지를 생성하는 과정에는 이미지 편집, Person re-Identification (re-ID), inpainting 또는 영화 산업에서 쓰입니다.
- 사람들은 기본적인 사람을 생성하는 것을 넘어서 배경, 사람의 외모와 의복, view를 더 많이 제어하기를 원합니다.
Problems
- Generative Adversarial Network(GAN) 또는 Variational Auto Encoder를 사용하여 노이즈 z에 의해 생성된 분포를 실제 데이터 분포에 매핑하는 기존 이미지 생성 방법은 인체에 있어서 최적이 방법이 아닙니다.
- 기존 방법은 훈련을 위해 정렬된 사람의 이미지 pair가 필요한데, 비용이 많이 듭니다.
- 사람의 이미지를 생성하는 것은 전경, 배경 및 포즈 정보와 같은 다양한 이미지 요소 간의 복잡한 상호 작용 때문에 어렵습니다.
The Proposed Method (Briefly)
이 논문의 제안 방법은 이미지 요소를 disentagled한 표현으로 학습하고, person image를 생성하는 과정을 2단계 재구성 파이프라인으로 나누는 것입니다.
- 1단계에서는 사람의 이미지를 입력으로 사용하고 전경, 배경 및 포즈의 세 가지 요소로 분리합니다. 각 분해된 요소는 재구성 네트워크를 통해 feature를 포함하여 모델링됩니다.
- 2단계에서는 가우시안 분포를 feature 임베딩 분포에 매핑하는 매핑 함수를 학습합니다.
Contribution
- 입력을 약한 상관 요소, 즉 전경, 배경 및 포즈로 분리함으로서 자연스러운 이미지를 생성하는 새로운 방법입니다.
- 이 모델은 생성 프로세스를 잘 제어하기 위해 전경, 배경 및 포즈 샘플링을 동시에 활용하여 disentangled한 사람의 이미지 생성 작업을 unpaired인 self-supervised 방식으로 해결하려고 합니다.
- 사람에 대한 re-ID의 학습 데이터를 위해 생성된 데이터가 쓰일 수 있습니다.
2. Related Works
(생략)
3. The Proposed Method
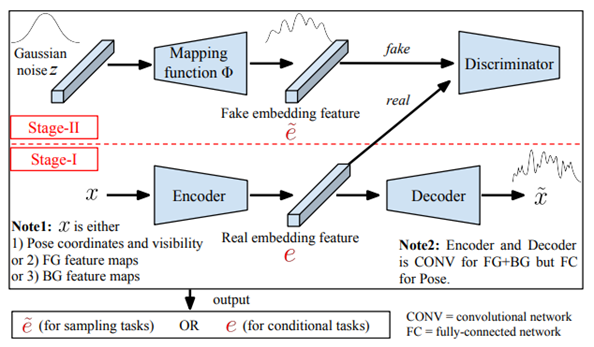
다음과 같이 1단계에서는 재구성 네트워크를 사용하여 각 요소 (전경, 배경 및 포즈)에 대한 real embedding feature 𝒆을 얻습니다. 2단계에서는 가우시안 노이즈 𝒛을 매핑 함수 Φ를 통해 fake embedding feature 𝒆 ̃를 생성한 다음, real embedding feature 𝒆와 적대적으로 학습합니다. 매핑 함수 Φ는 1단계에서 사전 학습된 인코더 및 디코더를 사용합니다.
Stage 1
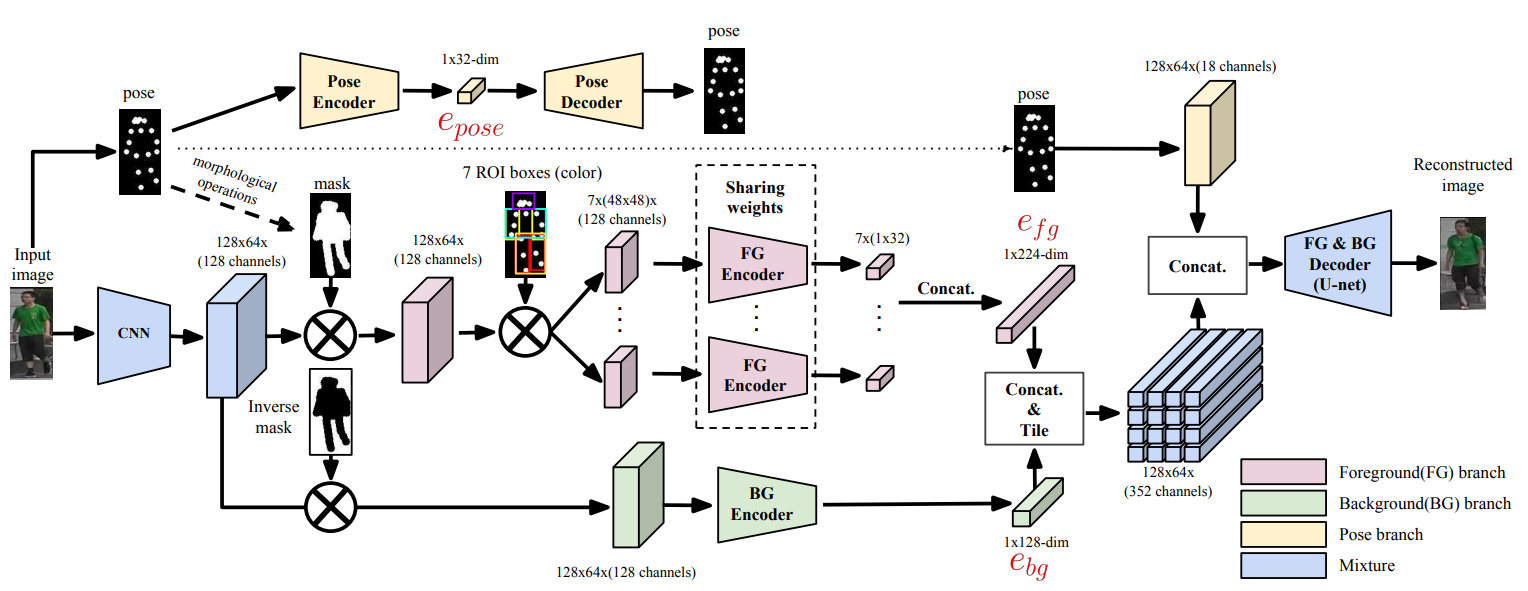
Pose Branch
- 포즈의 히트맵(18-channels)과 대략적인 포즈 마스크를 얻기 위해 OpenPose의 키포인트의 반경을 4픽셀로 채운 마스크와 마스크의 키포인트을 연결한 마스크를 생성합니다.
- 그런 다음, 포즈 키포인트 마스크는U-Net 구조 기반의 아키텍처로 입력됩니다.
- 폐색으로 인해 일부 신체 부위가 보이지 않을 수 있으므로 가시성 변수 𝜶_𝒊∈ {0, 1}, 𝒊 = 1… 18을 사용하여 각 포즈의 키 포인트의 가시성 상태를 나타냅니다.
- 포즈 정보는 54차원 vector (36차원 키포인트 중심 좌표 γ(x,y) 및 18차원 키포인트 가시성 α)로 표현할 수 있습니다.
Foreground Branch
- 전경 정보와 배경 정보를 분리하기 위해 입력 이미지 대신 feature map에 대략적인 포즈 마스크를 적용하여 사용합니다.
- 포즈 정보에서 전경을 더 분리하기 위해(더 확실한 feature를 뽑아낼 수 있음) Spindle Net과 유사한 7개의 ROI (Body Regions-Of-Interest)로 pose invariant feature를 인코딩합니다.
- 그런 다음, 이러한 포즈 키포인트를 활용하여 각 신체 부위에 필요한 appearance feature를 추출하고 전체적인 사람 이미지를 생성합니다.
- 특히 각 ROI에 대해 48x48로 크기가 조정된 feature 맵을 추출하고 가중치를 공유하는 전경 인코더로 전달하여 학습 효율성을 높입니다.
- 마지막으로, 인코딩된 7개의 body ROI embedding feature는 224차원 feature vector로 concatenate됩니다.
Background Branch
- 역 포즈 마스크를 적용하여 배경 feature map을 가져와서 배경 인코더에 전달하여 128 차원 embedding feature를 얻습니다.
- 끝으로, 전경 및 배경 feature는 서로 concatenate되고, 같은 feature가 바둑판 모양으로 배열됩니다(Tiled). 그런 다음, pose feature와 concatenate되고 Decoder를 통해 복원된 이미지가 생성됩니다.
Stage 2
Embedding Feature Mapping
- 이미지는 연속된 feature embedding space에서 low-dimension으로 표현될 수 있습니다.
- Feature embedding space의 분포는 실제 데이터 분포에 비해 더 연속적이고, 쉽고 빠르게 학습할 수 있습니다.
- 가우시안 노이즈를 이미지 공간으로 디코딩하는 방법을 직접 학습하는 대신, 먼저 가우시안 공간 Z를 연속적인 feature embedding space E에 매핑 함수 Φ를 학습하고, 사전에 훈련된 디코더를 사용하여 feature embedding space E를 실제 이미지 공간 X에 매핑 시킵니다.
- 1단계에서 학습된 인코더는 FG, BG 및 포즈 계수 x를 Low-dimensional 실제 embedding feature 𝑒로 인코딩합니다. 그런 다음 가우스 노이즈 𝒛에서 매핑된 feature를 fake embedding feature 𝒆 ̃으로 취급하고 매핑 함수 Φ를 적대적으로 학습합니다.
- 이러한 방식으로 노이즈에서 fake embedding feature를 샘플링 한 다음, 1단계에서 학습된 디코더를 사용하여 다시 이미지를 매핑할 수 있습니다.
Image Sampling
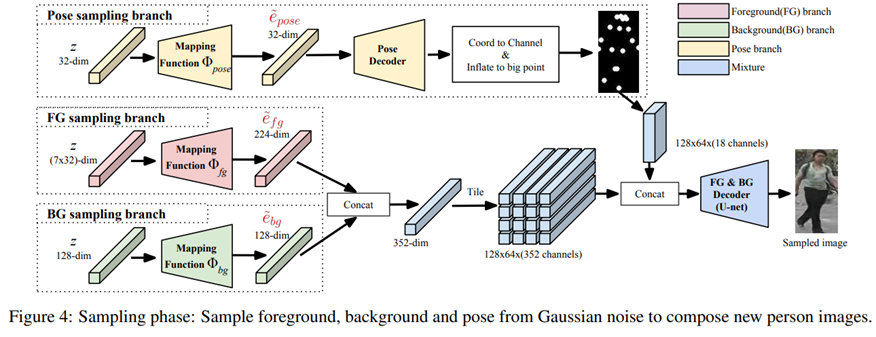
- 각 이미지 요소는 입력 정보를 인코딩 할 수 있을 뿐만 아니라 가우시안 노이즈에서도 샘플링 할 수 있습니다.
- 새로운 전경, 배경 또는 포즈를 샘플링하기 위해 1단계에서 학습된 디코더와 2단계에서 학습 된 mapping function을 결합하여 𝒛 → 𝒆 ̃ → 𝒙 ̃ 와 같은 샘플링 파이프 라인을 구성합니다.
Optimization Strategy
-
1단계에서 L1 Loss 및 Adverserial Loss를 모두 사용하여 Reconstruction network를 최적화합니다. 이렇게 하면, 더 선명하고 사실적인 이미지를 만들 수 있습니다.
-
𝐺1과 𝐷1은 각각 Reconstruction network와 Discriminator를 나타냅니다.
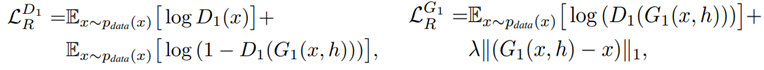
-
𝑥은 input image, ℎ는 pose heatmap, λ는 L1 Loss의 가중치로 이것은 low-freguency에서 reconstruction 이미지가 Input 이미지에 얼마나 비슷하게 보이는지 조절합니다.
-
포즈를 재구성 하기 위해 L2 Loss를 사용하여 pose brnach에서 언급한 키포인트 좌표 γ 및 가시성 α를 포함한 입력 포즈 정보를 재구성합니다.
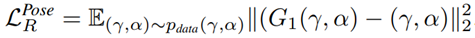
- 1단계에서 Reconstrction Network를 훈련시킨 후, Wasserstein GAN으로 바꿔서 사용합니다. (Valina GAN의 Loss가 2단계의 mapping function에서 mode collapse를 일으킴.)
- Wasserstein GAN은 가짜 및 진짜를 구별하는 것이 아니라, Φ(𝒛)와 𝒆 분포의 차이를 줄이는 것입니다.
- 이 논문에서는 Φ 및 𝐷2를 사용하여 매핑 함수 ( Φ𝑓𝑔, Φ𝑏𝑔 및 Φ𝑝𝑜𝑠𝑒) 및 2단계의 Discriminator를 나타냅니다.
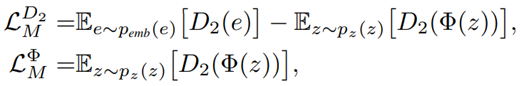
- 𝑒은 1단계의 reconstruction network에서 추출된 embedding feature를 나타내고, 𝑧는 가우스 노이즈를 나타냅니다.
- Adverserial 훈련의 경우 Discriminator와 Generator를 번갈아 최적화합니다.
4. Experiments
Dataset : DeepFashion, Market-1501

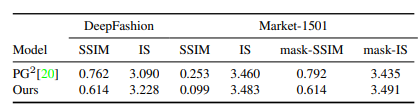
위의 결과를 보시다시피 이전의 방법보다 더 선명해지고 특징들을 잘 잡아낸것을 알 수 있습니다.

그리고 원본 이미지(위)에서 포즈, 전경, 배경 중 랜덤을 바꿔서 나온 결과(아래)를 나타냅니다. 이것을 person Reidentification의 데이터 세트로 사용 가능합니다.
5. Conclusion
이 논문에서는 사람 이미지 생성 작업을 처리하기 위한 새로운 2단계 파이프 라인을 제안합니다.
- Stage-I는 입력 이미지의 세 가지 변형 모드, 즉 전경, 배경 및 포즈를 embedding feature로 분리하고 인코딩 한 다음, 다중 분기 재구성 네트워크를 사용하여 이미지로 다시 디코딩합니다.
- Stage-II는 Stage-1에서 학습한 디코더를 사용하여 feature embedding 분포에 노이즈 분포를 매핑하는 적대적인 방식으로 mapping function을 학습합니다.
- 이 방법을 사용하여 다른 유형의 구조를 가진(얼굴이나 동물과 같은) non-rigid image에도 적용할 수 있습니다.
