본 논문은 기존의 Person Generation이 Iconic한 View에서만 성능이 좋은 것을 보고, Non Iconic한 상황의 이미지에서도 성능을 높이기 위해 제안되었습니다.
논문
https://ieeexplore.ieee.org/document/9200521
Github
https://github.com/loadder/MR-Net
1. Introduction
Domain/Issue :
- 원하는 포즈로 사람 이미지를 합성하는 것은 최근에 컴퓨터 비전, 멀티미디어 및 그래픽 커뮤니티에서의 많은 연구 관심을 끌었습니다.
- 최근 이러한 광범위한 연구들은 iconic한 사람의 이미지만을 합성합니다.
- Iconic view/Non-iconic view

(a) Iconic view : 단순한 장면에서 깔끔하게 구성되어 있고, 사진의 중앙 근처에서 걷거나, 서있는 포즈가있는 인물 인스턴스 입니다. ex) Market-1501, Deep Fashion
(b) Non-iconic view : 어수선한 장면에서 임의의 포즈를 취하는 인물 인스턴스 입니다. ex) Penn Action, BBC-Pose
Problems :
- 이전 모델들은 시중에서 판매되는 디지털 카메라에 사람 이미지가 Non-iconic view로 찍히는것과 같은 복잡한 작업을 처리할 수 없습니다.
- 기존 연구에서 사용되던 데이터 세트는 어수선한 장면과 같은 Non-iconic view가 캡쳐될 수 있는 실생활의 데이터 세트가 아닙니다.
- 이전 모델들에 non-iconic view 데이터 세트를 사용하면 불안정한 훈련이 발생하고 품질이 낮은 결과가 생성됩니다.

즉, 기존 연구들은 Iconic view에만 중점이 맞춰져 있습니다. 하지만 실생활에서는 Iconic View보다 Non-iconic view가 더 많기 때문에 범용성이 떨어집니다.
The Proposed Method (Briefly) :
- Non-iconic view에서 사람을 합성하기 위해 이 논문에서는 타겟 포즈, foreground인 사람의 신체 및 파싱된 장면 이미지(background)를 포함한 여러 시각적 단서를 활용하는 Multi-branch Refinement Network(MR-Net)을 제안합니다.
- 본 논문에서는 MR-Net을 효율적으로 최적화하여 Non-iconic한 사람을 더 잘 합성하는데 도움이 될 수 있는 관심 영역 지각 손실(RoI perceptual loss)을 제안합니다.
- Refinement 전략을 채택하여 MR-Net으로 인해 합성된 이미지를 반복적으로 개선하여 결과를 업데이트하고 background를 더욱 일관되게 만듭니다.
Contribution :
- 이 논문은 처음으로 Non-iconic view에서 포즈를 기반으로 한, 사람 합성을 다루는 방법입니다.
- 이 모델은 장면(scene)과 배경(background)의 표현을 명시적으로 학습할 뿐만 아니라 더 잘 학습하기 위해 새로운 손실 함수를 사용합니다.
- Refinement 전략을 사용하여 출력 이미지를 업데이트하고 훈련 프로세스를 가속화합니다.
2. Related Works
(생략)
3. The Proposed Method
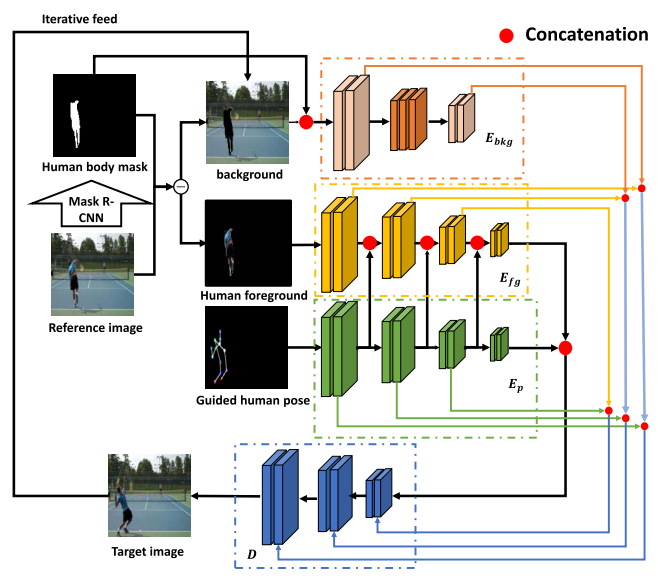
이 논문의 목표는 복잡한 배경과 함께 지정된 포즈로 새로운 사람의 이미지를 합성하는 것입니다. 이 모델은 사전 훈련된 이미지 분할 모델인 Mask-RCNN을 사용하여 참조 이미지에서 전경 인물의 몸과 배경을 분리합니다. 다중 분기 인코더(The multi-branch encoders)는 배경 이미지, 타겟 포즈 및 전경 인물 이미지를 인코딩하는데 사용됩니다. 추출된 모든 정보는 디코더를 통해 결합됩니다. 이 모델의 기능을 향상시키기 위해 skip connection, dilated-convolution 및 non local blcok이 사용됩니다.
Pose-Guided Multi-Branch Encoders
- 이 방법은 전경인 신체와 배경 장면의 정보를 구문 분석하고 인코딩하는데 다중 분기 인코더(Multi-branch encoder) 구조를 다르게 사용할 것을 제안합니다.
- 여기서 사람 인스턴스는 대상 포즈에 따라 극적으로 변경되어야 하며, 배경 장면에 필요한 업데이트는 상대적으로 미묘합니다.
- 따라서, 메인 아이디어는 (1) background encoder의 배경 이미지 및 배경 인코더가 있는 인체 마스크와 (2) 포즈 기반 인코더의 타겟 포즈 및 사람의 전경으로 분리하는 것입니다.
Background Encoder
- 이 모델은 background encoder 𝑬𝒃𝒌𝒈를 학습하여 배경 이미지를 해당 마스크 𝑴과 함께 인코딩합니다.
- 특히, 최근 inpainting에 대한 연구에서 영감을 받아 "Dilated copnvolution"을 활용하여 수용 영역을 증가시킵니다.
- Dilated convolution은 풀링 레이어를 수행하지 않고 큰 수용 영역을 가질 수 있으므로 공간 차원의 손실이 적고 대부분의 가중치가 0이므로 실시간 효율성이 좋습니다.
Pose-Guided Encoder
- 전경 인코더 𝐸𝑓𝑔는 전경 인물 이미지를 처리하고 타겟 포즈 인코더 𝐸𝑝는 타겟 포즈에서 특징을 추출하는 방법을 학습합니다.
- 특히 순방향 학습에서 𝑬𝒑의 레이어의 intermediate feature는 𝑬𝒇𝒈의 학습 과정을 안내하는데(guide) 사용됩니다.
- 𝐸𝑝의 feature는 𝐸𝑓𝑔에 있는 동일한 레이어의 해당 출력 feature와 채널 별로 concatenate 됩니다.
Decoder
- 세 가지 인코더의 출력은 합쳐져서 디코더 𝐷를 통과하게 됩니다. 𝐸𝑓𝑔 및 𝐸𝑝의 출력은 concat되어 𝐷의 입력으로 사용됩니다.
- 이미지 품질을 향상시키기 위해 이 모델은 디코더에서 non local block을 사용합니다.
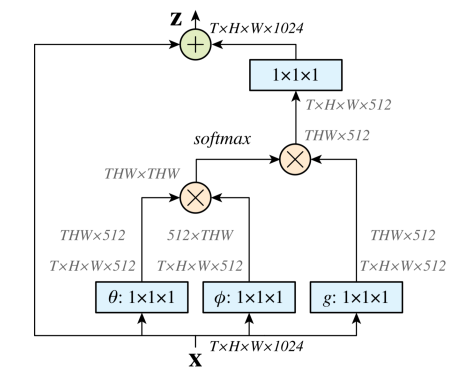
- Non-local block :
- 컨볼루션 및 풀링은 local operation 입니다. local operator를 stack하거나 이미지를 down-sampling 하면 수용 영역의 크기는 커질 수 있지만, 많은 local operator가 stack 되어 있어도 한 번에 global 영역을 보는 것과는 다릅니다.
- 따라서, non local block을 추가함으로써 네트워크는 이전에 보지 못했던 새로운 feature들을 학습할 수 있습니다. 아래의 사진의 Non-local block의 구조입니다.
Refinement Strategy
- 이 모델을 업데이트 하기 위한 반복적으로 개선하는 전략을 도입합니다.
- 특히 생성된 이미지 𝑰𝒔 ̂를 새로운 배경 이미지로 취급하고 배경 인코더 𝑬𝒃𝒌𝒈를 반복적으로 업데이트 합니다.
- 원칙적으로 이 전략은 모델이 배경 이미지의 누락된 영역을 점진적으로 채우는 데 도움이 될 수 있으므로 출력 이미지를 개선하고 훈련 프로세스를 가속화 할 수 있습니다.
Loss Functions
-
Reconstruction Loss의 목적은 생성된 이미지의 픽셀이 타겟 이미지, 특히 참조 및 타겟 이미지에 사람 인스턴스가 어디에 있는지 위치를 일치하도록 하는 것입니다. 각각 이미지 전체의 loss, 포즈만을 강조한 loss를 나타냅니다.
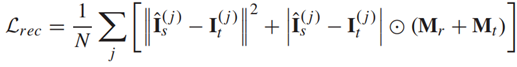
-
𝑴𝒓 및 𝑴𝒕는 참조 및 타겟 이미지의 이진 마스크를 나타내며, 값 1은 경계 상자 내의 픽셀을 나타냅니다.
-
Perceptual Loss는 생성된 이미지의 High-level feature를 타겟 이미지로 밀어 넣기 위해 도입되었으며, 이미지 간 콘텐츠 및 스타일의 지각적인 차이를 측정합니다.
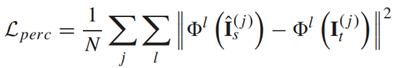
-
Perceptual Loss는 많은 생성 모델에 의해 사실적인 이미지를 합성하는데 널리 사용된다는 사실에도 불구하고, perceptual loss 만으로는 합성된 사람의 신체 부위의 시각적 품질이 충분하지 않다는 것입니다.
-
이를 위해 본 논문에서는 "RoI perceptual loss"를 제안합니다. 특히, 특정 이미지 영역, 즉 사람의 신체 영역을 최적화합니다.
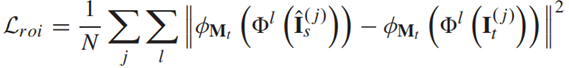
-
여기서 𝜙𝑀𝑡는 바운딩 박스가 타겟 포즈 마스크 𝑀𝑡인 Faster R-CNN의 RoI Pooling Layer이며, 관심 영역을 지역화하는 데 도움되는 것 이외에도 RoI pooling Layer 𝝓는 모든 샘플에서 출력 feature 크기를 동일하게 유지합니다. 즉, 크기가 전부 같다는 말입니다. 따라서 인체의 크기에 관계없이 미니 배치를 통해 Loss를 계산할 수 있습니다.
※ RoI Pooling은 RoI 영역에 해당하는 부분만 max-pooling을 통해 feature map으로 부터 고정된 길이의 저차원 벡터로 축소하는 단계를 의미한다. 그냥 모든 feature map에서의 ROI 영역을 고정된 크기로 줄인다고 보면 될거같다.
- VGG로 feature map 구함
- 타겟 포즈 마스크를 바운딩 박스로 하고 feature map에 투영시킴.
- feature map에 투영된 바운딩 박스(타겟 포즈 마스크)를 ROI Pooling Layer를 통해 고정된 크기로 줄인다.
정리하자면, 타겟 포즈 마스크의 영역에서의 feature map끼리 비교하겠다는 의미이다.
4. Experiments
Dataset : Market-1501, Penn Action, BBC pose
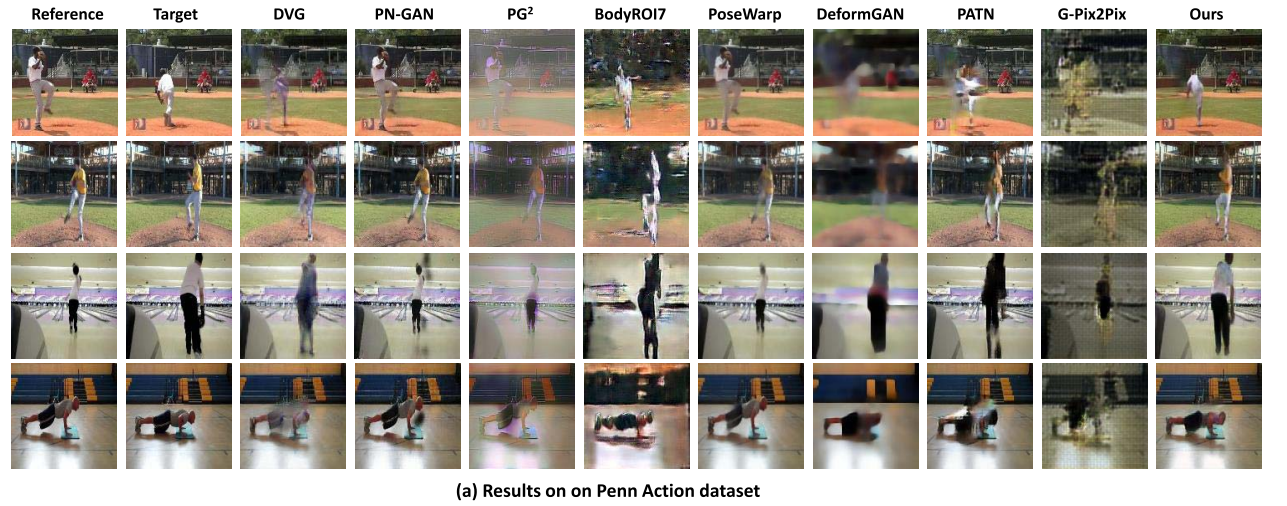

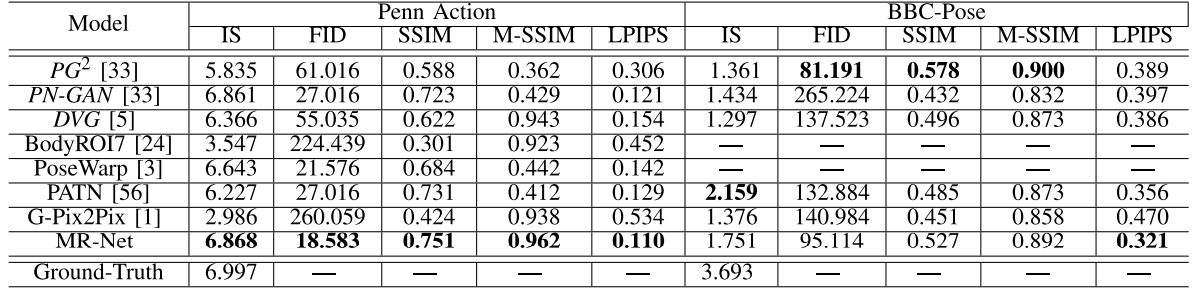

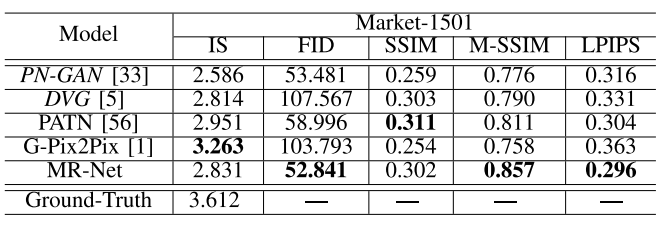
위의 사진과 표를 보면 거의 모든 데이터 세트에서 성능 지표평가나 시각적으로 제안된 방법이 더 좋다는 것을 알 수 있습니다.
그러나 이러한 메트릭은 일반적인 이미지 품질은 반영 할 수 있지만 타겟 이미지의 포즈 변경에 대한 품질은 반영할 수 없습니다. 이를 위해, 우리는 다른 방법들보다 이 모델의 장점을 보여주기 위해 더 질적인 결과와 주관적인 사용자 연구를 제공합니다.
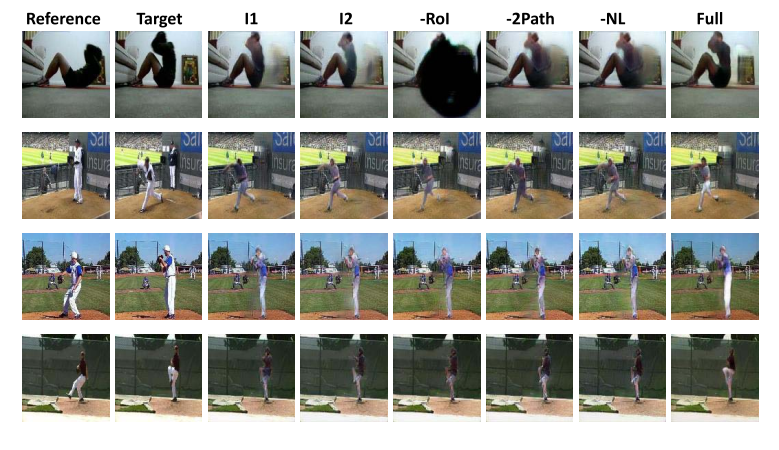

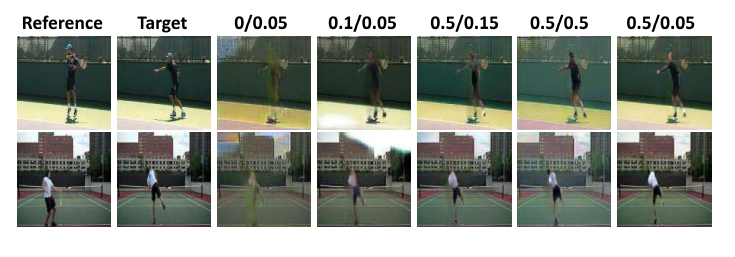
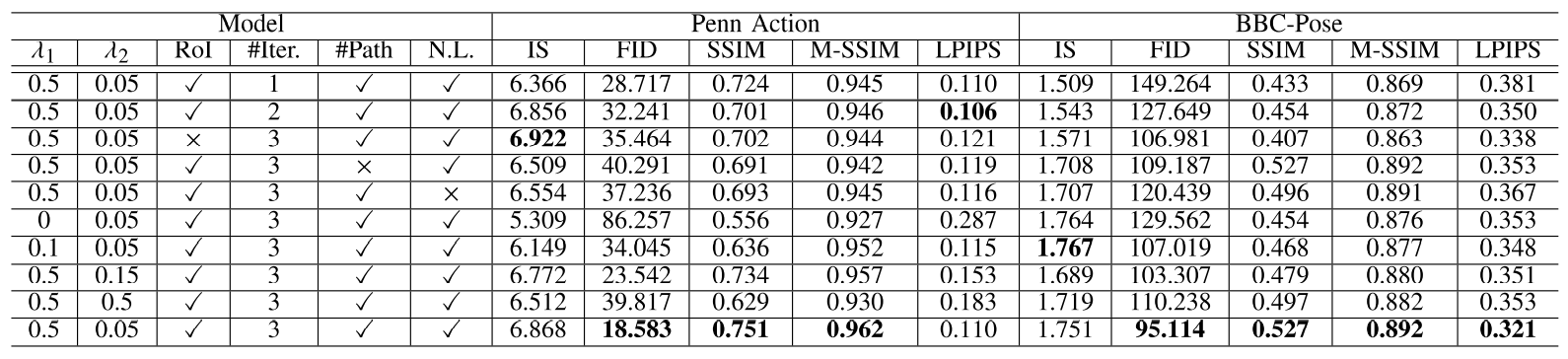
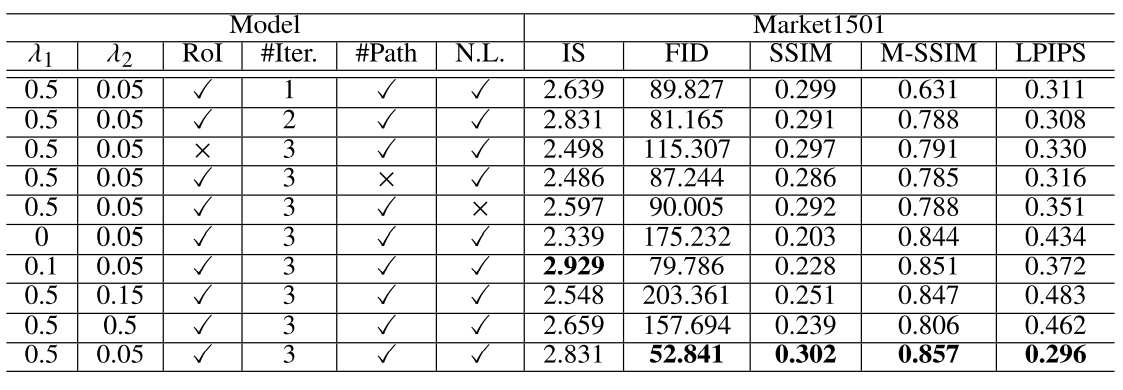
위의 실험 결과로 여러 파라미터 값들과 최적의 반복횟수를 결정합니다.
5. Conclusion
본 논문은 Non-iconic view에서 포즈 기반의 사람 이미지 합성을 목표로 하는 새로운 모델을 제시합니다.
- 전경 인물 신체와 배경 장면의 정보를 별도로 구문 분석하고 인코딩하는 MR-Net을 제안합니다. - RoI perceptual loss와 반복적인 Refinement 전략 또한 제안됩니다.
- 세 개의 데이터 세트에 대한 실험은 다른 방법들에 비해 이 모델이 효과적이라는 것을 보여줍니다.
