이 논문은 포즈와 이미지의 상관관계를 포착하여 새로운 포즈의 따른 이미지 생성을 정확하게 하는 새로운 방법을 설명합니다.
논문
https://www.ecva.net/papers/eccv_2020/papers_ECCV/papers/123700715.pdf
Github
https://github.com/Ha0Tang/XingGAN
1. Introduction
Domain/Fields
- 사람의 이미지를 생성하는 것은 입력된 인물 이미지와 원하는 여러 포즈를 조건으로 하여 사실적인 인물 이미지를 생성하는 것을 목표로 함.
- 이러한 방법은 사람 이미지를 생성하는 것 뿐만 아니라, 비디오 생성, re-identification에서도 사용.
Problem
- 기존 방법과 가장 비슷한 "Progressive pose attentiontransfer for person image generation" 논문에서는 shape feature의 attention map을 만들기 위해 여러 컨볼루션 층을 사용하지만, 컨볼루션 연산은 한 번에 하나의 local 영역을 처리하는 블록이기 때문에 shape과 appearace feature 간의 joint influence(서로 영향을 미치는 것)을 캡처할 수 없음을 의미.
- 또한, attention map은 pose(shape) 부분에서만 생성되기 때문에 포즈와 이미지(shape과 appearance)에 대한 정확하지 않은 상관 관계를 초래하여 이미지를 잘못 생성 할 수 있음.
The Proposed Method(briefly)
이러한 문제를 해결하기 위해, 이 논문에서는 Shaped-Guided Appearance-based(SA) Generation Branch, Appearance-Guided Shaep-based(AS) Branch, Co-Attention Fusion(CAF) Module로 이루어진 XingGenerator와 shape-guided discriminator, appearnace-guided discrimnator로 이루어진 XingGAN(=CrossingGAN)을 소개합니다.
- SA Branch : shape기반으로 appearance 생성하는 여러개의 블록으로 구성.
- AS Branch : appearance기반 shape 생성하는 여러개의 블록으로 구성.
- 두 Branch에 의해 공동으로 생성된 attention map을 생성하여 이미지와 포즈간의 joint influence를 포착하기 위해 SA 및 AS 블록 모두에서 교차 작업 진행.
- CAF Module : 최종 appearance와 shape feature를 더 잘 융합하여 원하는 인물 이미지를 생성하기 위해 사용.
- Discriminator는 appearance-guided discriminator와 shape-guided discriminator 두 개로 구성. 생성된 이미지의 모습이 target image와 얼마나 비슷한지, target pose와 얼마나 align 되어 있는지 각각 비교.
Contribution
- 두 개의 다른 생성 branch (AS 및 SA branch)를 사용하여 appearance 및 shape feature 모두에서 보다 디테일한 결과를 점진적으로 생성하는 것을 목표로 함.
- SA 및 AS 블록을 제안하여 사람의 appearance와 shape feature를 교차 방식으로 효과적으로 전달하고 업데이트하여 서로의 블록을 개선하고 최종 출력 결과의 품질을 크게 높임.
- 기존 방법들과 비교했을 때, 시각적 뿐만 아니라, target pose의 alignment에서도 SOTA 결과 도출
2. Experiments (생략)
3. The Proposed Method
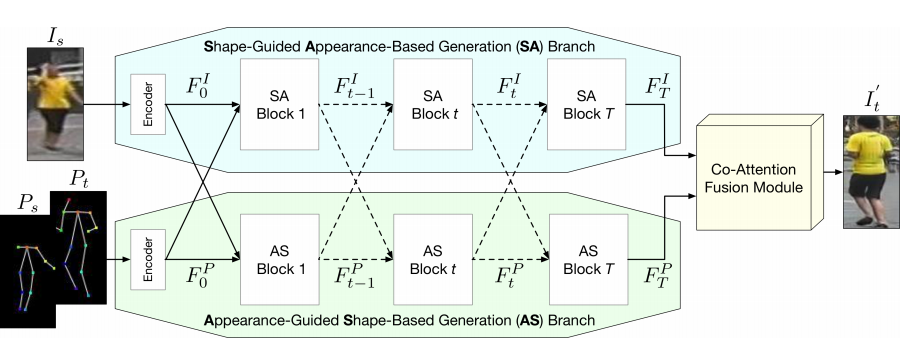
 그림과 같이 source image(외형 정보)는 SA branch의 입력으로, source pose, target pose(모양 정보)는 concat되어 AS branch의 입력으로 들어갑니다. 그리고 마지막 image feature와 pose feature가 CAF Module의 입력으로 들어가 이미지가 생성됩니다.
그림과 같이 source image(외형 정보)는 SA branch의 입력으로, source pose, target pose(모양 정보)는 concat되어 AS branch의 입력으로 들어갑니다. 그리고 마지막 image feature와 pose feature가 CAF Module의 입력으로 들어가 이미지가 생성됩니다.
Shape-Guided Appearance-Based Generation(SA)
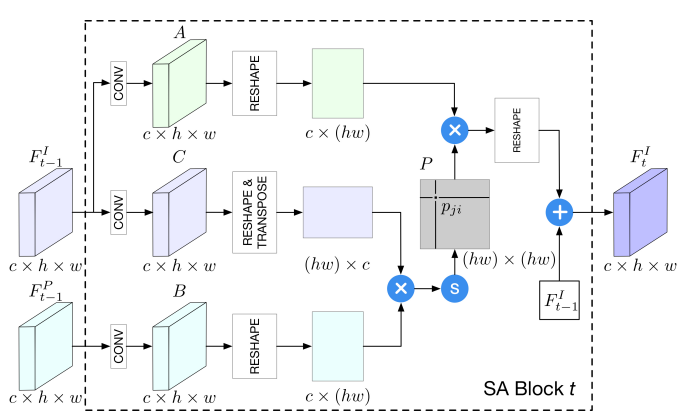
SA branch는 Fig.1 에서와 같이 하나의 Encoder와 여러개의 SA block들로 이루어져 있습니다. 이 Encoder는 두개의 컨볼루션 층으로 이루어져 있고, 각 SA block들은 AS block들의 도움을 받아 점진적으로 업데이트 해나갑니다.
- C : 먼저, Encoder를 통과하고 컨볼루션 층을 지나 Reshape과 Transpose를 거침.
- B : 동시에, SA block은 AS branch로 부터 shape feature를 받고, 컨볼루션 층을 거쳐 Reshape하게 됨.
- 그리고 두 feature의 상관관계를 도출하기 위해 B와 C를 곱하여 Softmax layer를 적용(B가 C에 미치는 영향을 측정). 이 부분은 Non-local block 적용. 기존 Non-local block과 차이점은 동일한 feature 내에서 적용하는 것이 아니라, 서로 다른 feature사이에서 적용한다는 것.
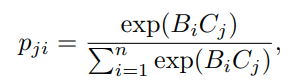
- 이런 교차 방식은 appearace와 shape사이의 joint influence를 높여 SA branch의 결과를 높임.
- A : C 처럼 Encoder를 거치고 컨볼루션 층을 거쳐 A를 만들고 Reshape을 해서 P와 곱하게 됨. (여기서 P는 B와 C Softmax layer 결과 값이며, 어느 부분이 부각되어야 하는지 알려줌)
- 마지막으로, scale parameter α(0부터 시작하여 계속 업데이트 됨)와 residual connection(+)을 적용하여 최종적인 block의 feature가 결과 값으로 나오게 됨.
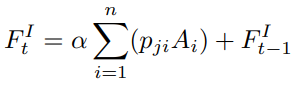
결국, appearance와 shape feature 사이의 local이 아닌 Global contextual view를 가지고, 어느부분이 부각되어야 하는지를 attention map(score) P 따라 그 중요도를 높이거나 낮출 수 있습니다.
Appearance-Guided Shape-Based Generation(AS)
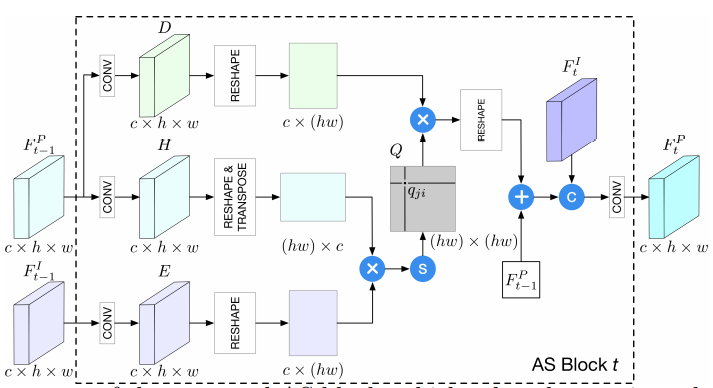
AS branch는 Fig. 1과 같이 Encoder와 연속적인 AS block으로 구성됩니다.
먼저, Source pose(Ps)와 target pose(Pt)는 채널에 따라 Concatenate된 다음, 초기값을 위해 Encoder의 입력으로 들어갑니다. Encoder는 SA branch의 Encoder와 동일한 네트워크 구조를 가지고 있습니다(두개의 컨볼루션 층). Encoder를 하나만 사용하는 이유는 두 포즈 간의 종속성을 캡처하기 위함 입니다.
마찬가지로 AS block들은 SA block들의 도움을 받아 점진적으로 업데이트 해나갑니다.
- H : 먼저, Ecoder를 통과하고 나서, 컨볼루션 층을 지나 Reshape과 Transpose 진행.
- E : 동시에 AS block에서 받은 feature를 컨볼루션 층을 거쳐 Reshape 진행.
- 그리고 두 feature의 상관관계를 도출하기 위해 E와 H를 곱하고 (내적이므로 similarity) Softmax layer(확률)를 적용하여 상관행렬 Q 생성(E와 H의 상관정도=attention map). 이 부분은 Non-local block 적용. 기존 Non-local block과 차이점은 동일한 feature 내에서 적용하는 것이 아니라, 서로 다른 feature사이에서 적용한다는 것.
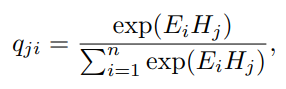
- D : H와 같이 컨볼루션 층을 거쳐 Reshape을 하고, Q와 곱하여 어느 부분이 부각되어야 하는지를 attention 정도를 곱해주어 그 중요도를 높이거나 낮추는 작업을 진행.
- 마지막으로 scale parameter β와 residual connection을 적용.
또한, appearance feature가 업데이트되면 shape feature도 업데이트하여 변경 사항을 동기화 해야 하기 때문에 shape feature는 새 appearance feature와 통합해야 함.
 여기서 알 수 있는 점은 SA branch가 먼저 업데이트 된다는 것이다.
여기서 알 수 있는 점은 SA branch가 먼저 업데이트 된다는 것이다.
Co-Attention Fusion Module(CAF)
CAF(Co-Attention Fusion) 모듈은 중간 결과 생성 및 co-attention map으로 구성되며, Decoder의 역할을 합니다. Co-attention map들은 중간 결과와 입력 이미지에서 공간적으로 어디가 부각되어야 하는지 사용되며, 최종 결과를 위해 결합됩니다. 이러한 아이디어는 SelectionGAN의 multi-channel attention selection module에서 가져왔다고 합니다.
기존 방법과의 차이점은 총 세가지 입니다.
- 1) 중간 결과는 SA branch와 SA branch의 결과로 총 2개를 사용.(원래는 feature 한개만 입력으로 사용)
- 2) Shape feature와 appearance feature의 결합으로 attention maps이 만들어지기 때문에 두 feature 사이의 상관관계 학습 가능.
- 3) 최종 이미지를 생성하기 위해 입력 이미지에서 유용한 콘텐츠를 선택하는 input attention map 생성.
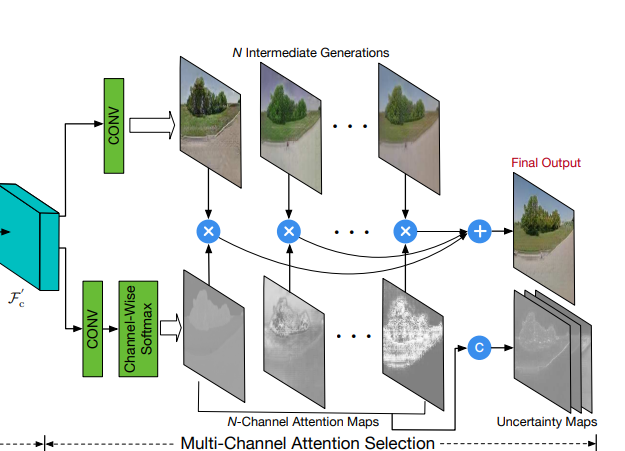 * 본 이미지는 SelectionGAN의 multi-channel attention selection module 입니다.
* 본 이미지는 SelectionGAN의 multi-channel attention selection module 입니다.
-
SA branch의 결과와 AS branch의 결과를 N개의 중간 결과를 만들기 위해 총 2N개의 컨볼루션 필터 사용. (본 논문에서는 N=10 으로 지정했다고 합니다.)

궁금증! : 논문에서는 마지막에 2N의 중간 결과와 input image가 candidate image라고 하는데 왜 input image도 중간 결과로 사용하는지는 잘 모르겠습니다...ㅠㅠ 사용하려면 target image를 사용하는게 더 그럴싸하지 않나.. -
Co-attention map을 생성하기 위해 appearace feature와 shape feature를 channel Concat하고, 중간 결과에 따른 attention map을 만들기 위해 2N+1개 만큼 생성. (+1은 위에서 언급한 input image에 따른 attention map으로 생각하시면 됩니다.)
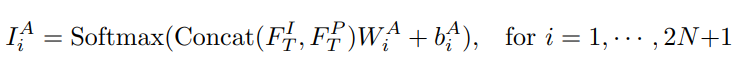
-
마지막으로, 중간 결과들과 co-attention map들을 이용해 최종 결과 이미지를 출력.
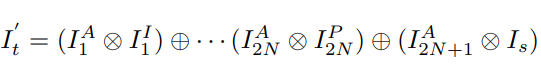
OPtimization Objective
이 논문에서는 Adversarial Loss, Pixel Loss, Perceptual Loss 총 3가지 Loss Function을 사용합니다.
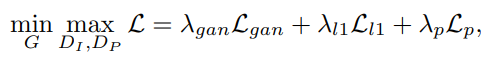
- Adversarial Loss : appearace-guided discriminator와 shape-guided discriminator를 반영한 Loss. (여기서는 아무리 봐도 CGAN loss를 써야할거같은데...)
- Pixel Loss(L1) : Generated image와 target image 사이에 pixel 값의 차에 대한 Loss.
- Perceptual Loss : VGG-19 network의 layer들을 이용하여 generated image와 target image가 시각적으로 얼마나 비슷한지 비교하는 Loss.
4. Experiments
- DataSets : Market-1501, DeepFashion
- Human Pose : OpenPose
- Evaluation Metrics : SSIM, IS, Mask-SSIM, Mask-IS, PCKh score(shape)
- Quantitative Comarisons : PG2, DPIG, VUNet, PoseGAN, Pose-Warp, CMA, C2GAN, BTF, Pose-Transfer
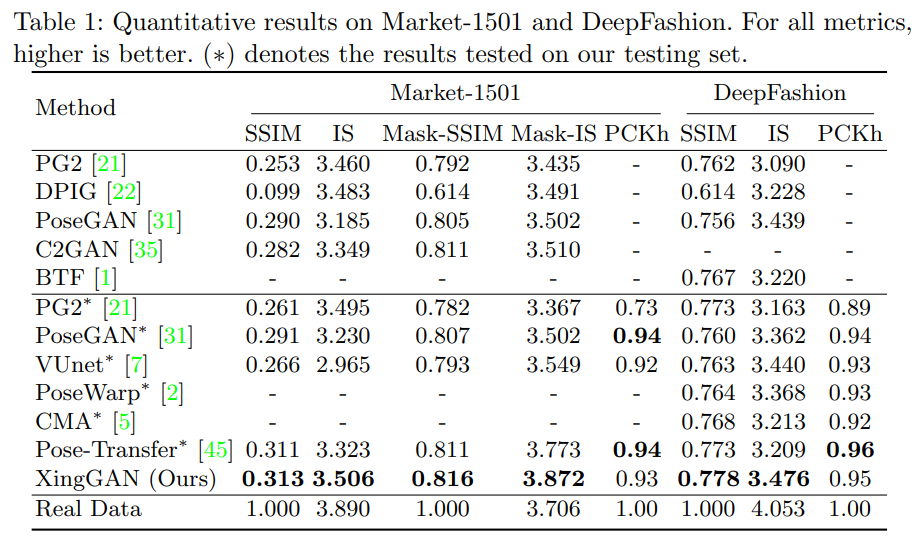
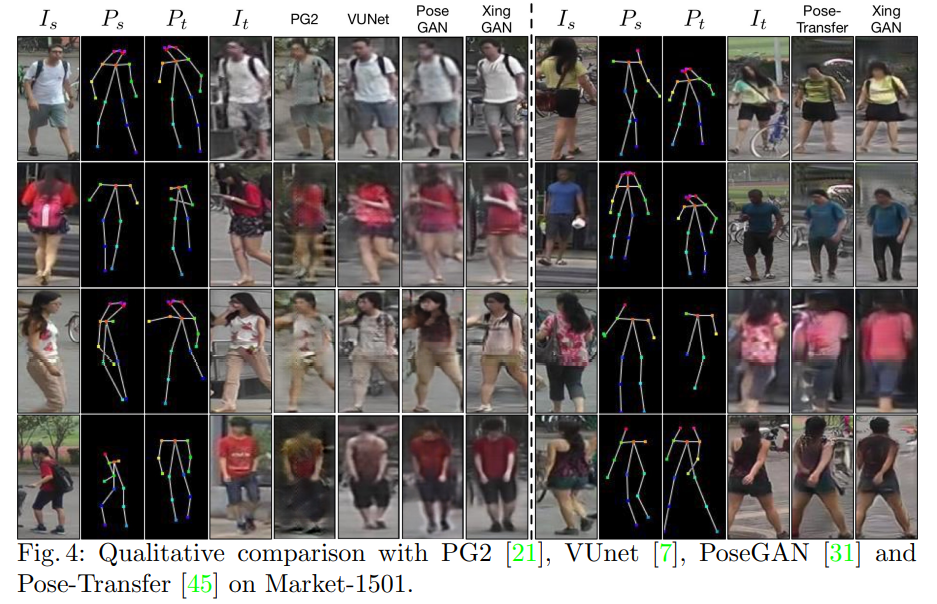
위의 표를 보면, 더 Realistic하고, 시각적으로 artifact가 덜 보인다는 것을 알 수 있습니다. 또한, 그림을 보더라도 결과가 더 좋다는 것을 알 수 있습니다.

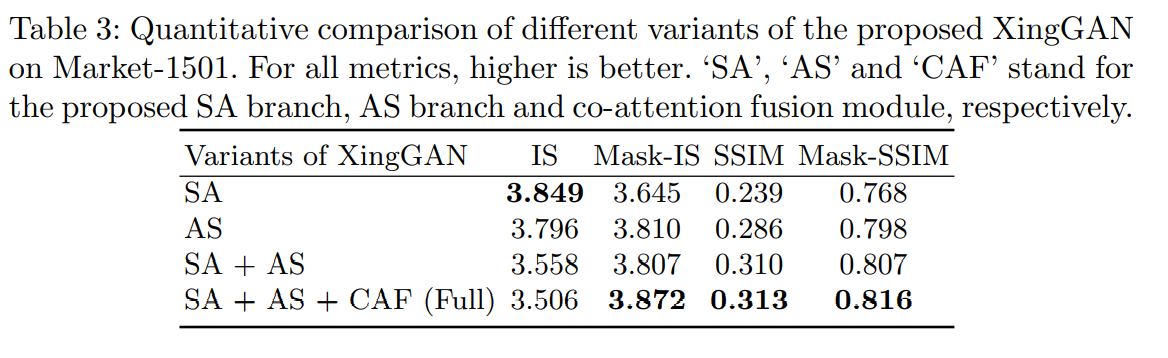
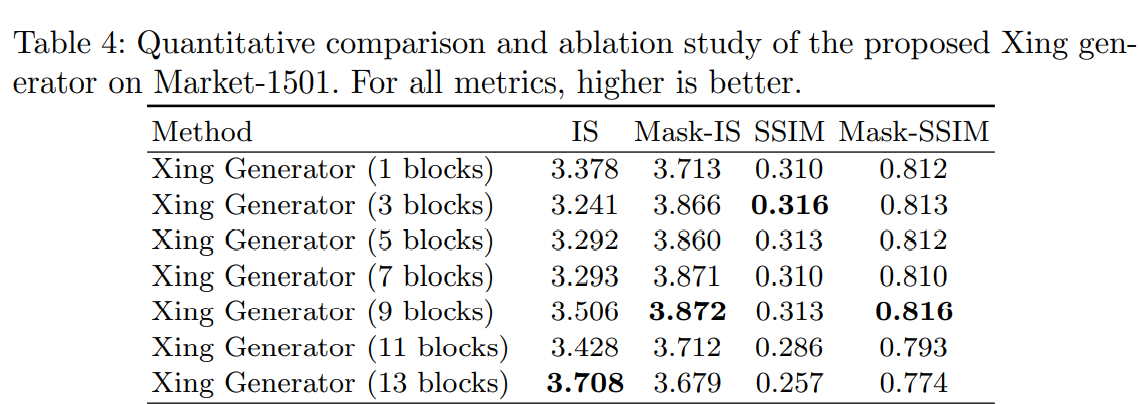
위의 그림과 표는 SA branch, AS branch, CAF Module을 각각 적용한 결과를 보여줍니다. 다음 결과에서 알 수 있는 것은 appearance을 배우는 것이 이미지와 원하는 이미지 사이에 shape의 변형이 있는 shape를 배우는 것보다 훨씬 쉽고 따라서, AS branch가 SA branch보다 더 나은 결과를 보여줍니다.
또한, 각 branch의 block이 너무 많아도 결과가 점점 떨어지는 것을 볼 수 있으며, 9개가 적당하다는 것을 실험결과로 알 수 있습니다.

위의 그림은 학습된 co-attention map과 생성된 중간 결과를 보여줍니다. 최종 인물 이미지를 생성하기 위해 생성된 중간 결과와 입력 이미지가 서로 다른 활성화된 내용을 학습했다고 추론할 수 있습니다.
5. Conclusions
이 논문은 인물 이미지 생성 작업을 위한 새로운 XingGAN을 제안하고, 두 개의 서로 다른 branch가 cascade 방법를 사용하고 교차 방식으로 사람의 appearance와 shape feature를 효과적으로 업데이트하기 위해 두 가지 새로운 블록을 제안합니다. 먼저, 점진적으로 업데이트 해나간다는 점에서 획기적이었고, 거기다가 Non-local block을 적용하여 self-attention으로 attention map을 적용한것도 좋은 아이디어 같았습니다. 하지만, 마지막 Co-attention Module 부분이 살짝 이해가 안가는 것도 있었고 굳이 한번더 attention을 해야 할까 라는 의문점도 있었습니다. 또한 기본적인 Loss Function을 사용하는데도 좋은 결과가 도출되어서 놀랐습니다.
