이 논문은 포즈 전달을 위한 새로운 GAN 네트워크를 제안합니다. 즉, 주어진 사람의 포즈를 타겟 포즈로 전달하는 것입니다. Generator는 pose-attentional transfer 블럭으로 구성되어 특정 관심 영역을 전송하여 사람 이미지를 점진적으로 생성합니다.
19년도 CVPR에서 발표되었습니다.
논문 : https://arxiv.org/abs/1904.03349
Github : : https://github.com/tengteng95/Pose-Transfer.git
1. Introduction
Domain/Fields
Generator와 Discriminator로 구성된 적대적 생성 신경망(GANs of Generative Adversarial Networks)은 일반적으로 포즈 전달(pose transfer)에 사용되며 적대적으로 훈련됩니다.
Issues
포즈 전송은 일련의 포즈로 비디오 생성 및 사람의 re-identification을 위한 데이터 증강과 같은 많은 작업에서 가치가 있습니다.
Problem
- 최근의 방법은 서로 다른 뷰에서의 서로 다른 포즈 이미지가 appearance가 크게 다를 수 있기 때문에 robust 결과를 생성하지 못하는 경우가 많습니다.
- 또한, 기존 방법은 생성 프로세스에서의 controllability가 향상되었지만, 생성된 이미지의 품질이 저하되었고, 상대적으로 큰 계산과 복잡한 훈련 절차가 필요하므로 일부 독특한 포즈에서의 성능이 저하됩니다.
The Proposed Method(briefly)
- 이 논문에서는 목표 포즈에 도달하기 전, 중간 포즈 표현인 Progrssive Pose Transfer Network를 제안하여 포즈 전송이라는 과제를 해결합니다. (큰 변형을 한번에 처리하는 것보다 작은 변형을 점차적으로 늘려나가 큰 변형을 처리하는것이 더 효과적이기 때문)
- 이 방법은 포즈와 외형의 feature를 효과적으로 활용하여 포즈 전송 과정을 원활하게 안내할 수 있는 새로운 계단식 PATB(Pose-Attentional Transfer Blocks)를 활용합니다.
- PATB(Pose-Attentional Transfer Block) 내부에는 외형을 위한 이미지 경로와 포즈를 위한 포즈 경로로 구성되어 있습니다.
- 이 방식을 사용하면 각 블록이 매니폴드에서 local transfer를 수행할 수 있으므로 global 매니폴드의 복잡한 구조를 캡처하는 문제를 피할 수 있습니다.
Contribution
- 이 네트워크는 계산 효율성을 높이고 모델 복잡성을 크게 줄입니다. 또한, re-identification을 위한 불충분한 훈련 데이터 문제를 실질적으로 완화하는데 사용될 수 있습니다.
- Progressive Pose-Attentional Transfer Network는 사람 이미지를 생성하는 데에만 국한되지 않고 다른 non-grid object를 생성하는데 적용될 수 있습니다.
2. Related Work
(생략)
3. The Proposed Method
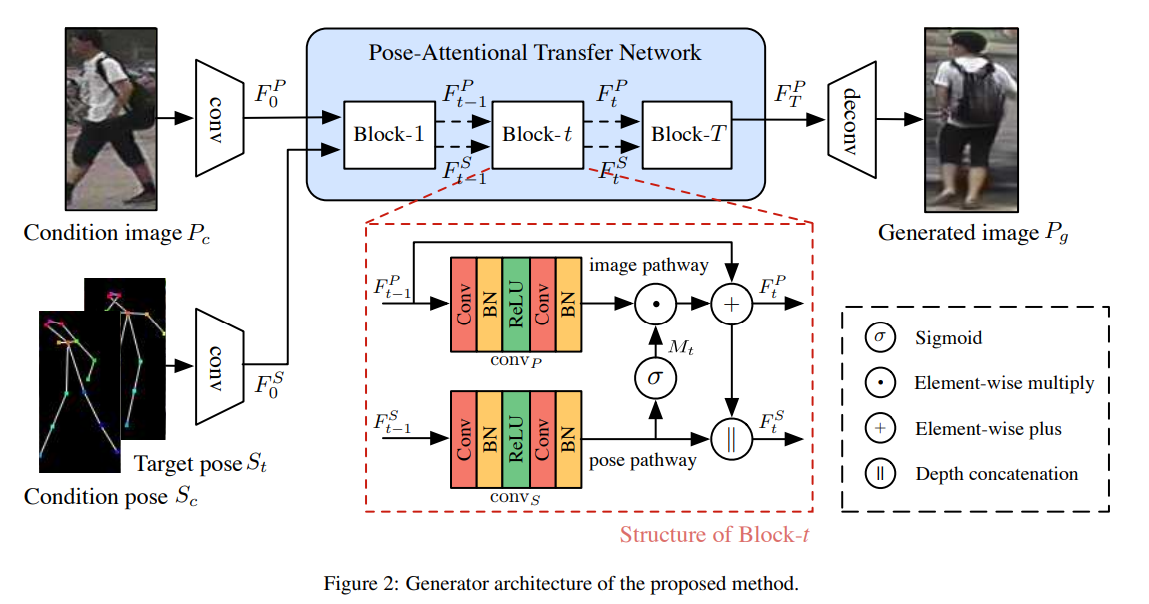
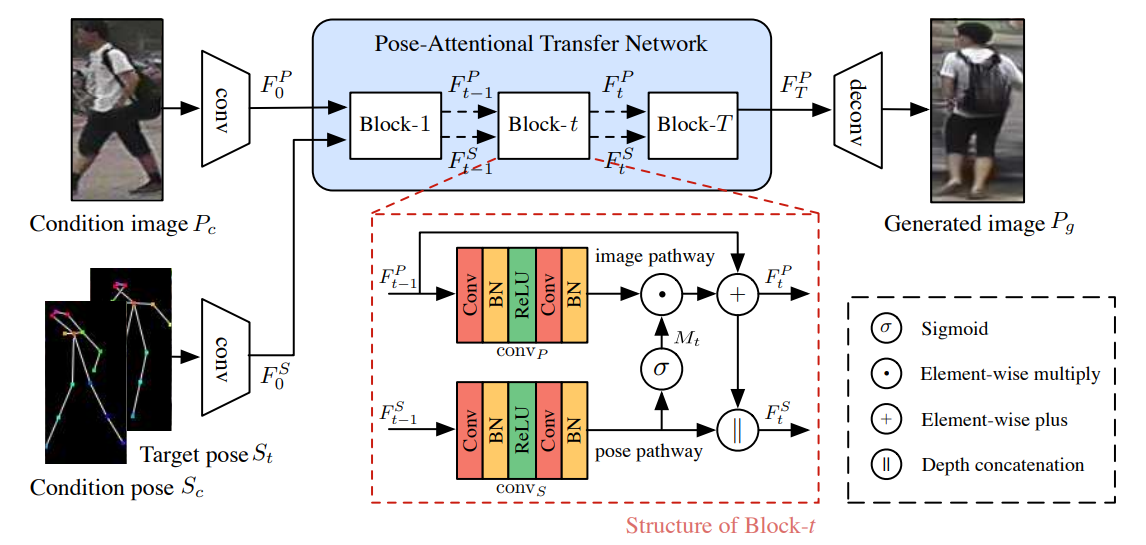
Generator는 condition pose 𝑺𝒄에서 target pose 𝑺𝒕로 인물의 포즈를 전송하여 조건 이미지 𝑷𝒄를 사실적인 인물 이미지 𝑃𝑔를 생성하는 것을 목표로 합니다. Condition 및 target pose는 신체의 18개 관절의 위치를 인코딩하는 18-channel heatmap으로 구성되며, Human Pose Estimator(OpenPose)를 사용했습니다.
Encoder
- 입력에서 조건 이미지는 2개의 down-sampling 컨볼루션 레이어에 의해 인코딩되고 condition pose 𝑆𝑐 및 target pose 𝑆𝑡는 인코딩되기 전에 depth 축을 따라 스택(concat)됩니다.
인코더의 구조는 같습니다. - condition pose 𝑆𝑐 및 target pose 𝑆𝑡의 인코딩 프로세스는 두 포즈를 혼합(concat)하여 정보를 보존하고 종속성을 캡처하는데 이렇게 하면 더 적은 계산이 듭니다.
Pose Attentional Transfer Network
- Generator의 핵심은 여러 개의 계단식 PATB(Pose-Attentional Transfer Block)로 구성된 PATN(Pose-Attentional Transfer Network) 입니다.
- 초기에 조건 이미지 feature 및 혼합된 포즈 feature에서 시작하여 PATN은 PATB의 순서를 통해 이 두 가지 feature를 점진적으로 업데이트합니다.
- 블록은 각각 이미지 경로와 포즈 경로라는 두 개의 경로로 구성됩니다.
Pose Attention Mask
- Pose transfer는 condition pose의 특정 위치에서 target pose의 특정 위치로 패치를 이동하는 시키는 것입니다. 즉, 포즈는 condition 패치를 샘플링할 위치와 target 패치를 배치할 위치를 알려주며 전송을 guide 합니다.
- 이 네트워크에서 이러한 힌트는 𝑴𝒕로 표시된 attention mask (시그모이드 함수에 의해 0과 1 사이의 값) 에 의해 실현되며, 이는 이미지 feature에서 특정 요소의 중요성을 나타냅니다.
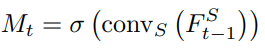
- Pose attention transfer 프로세스는 명확하고 해석 가능합니다. 여기서 attention mask는 항상 점진적으로 조정해야 하는 영역에 주의를 기울입니다.
- 초기 몇 개의 마스크는 condition pose와 target pose가 혼합되어 있습니다. Condition pose가 target pose로 이동함에 따라 조정해야 할 영역이 축소되고 흩어집니다. 결국 마지막 두 개의 마스크는 전경에서 배경으로 주의를 기울이는 것을 보여줍니다.

Image Code Update
- 변환된 이미지 feature는 2개의 컨볼루션 층을 거치고 포즈 경로에서 구해진 attention mask 𝑀𝑡와 곱해집니다.
- Element-wise product의 출력은 residual connection에 의해 더해집니다. 이러한 residual connection은 포즈 전송에서 원본 이미지에서 중요한 feature를 유지하는 데 도움이 됩니다.
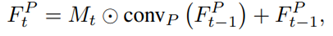
Pose Code Update
- 이미지 feature가 PATB를 통해 업데이트되면 포즈 feature도 업데이트하여 변경 사항을 동기화해야 합니다. 따라서 포즈 feature는 새로운 이미지 feature와 통합해야 합니다.
- 먼저, 이전 포즈 code가 두 개의 컨볼루션 층(정규화 레이어와 ReLU 사이에 있음)를 거칩니다.
- t>1 일 때, 첫 번째 컨볼루션 레이어는 feature map의 depth를 절반으로 줄여 포즈 경로에 있는 후속 레이어의 feature map의 depth를 이미지 경로의 feature map의 depth와 동일하게 만듭니다. 그런 다음 변환된 pose code와 업데이트된 이미지 code를 concat합니다.
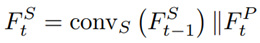
Decoder
- PATN의 업데이트로 최종 이미지 feature와 최종 포즈 feature가 생성됩니다. 최종 이미지 feature는 출력 이미지를 디코딩하는 데 사용되며 최종 포즈 feature는 버려집니다.
- 디코더는 Deconvolution layer를 통해 출력 이미지 𝑃𝑔를 생성합니다.
Discriminators
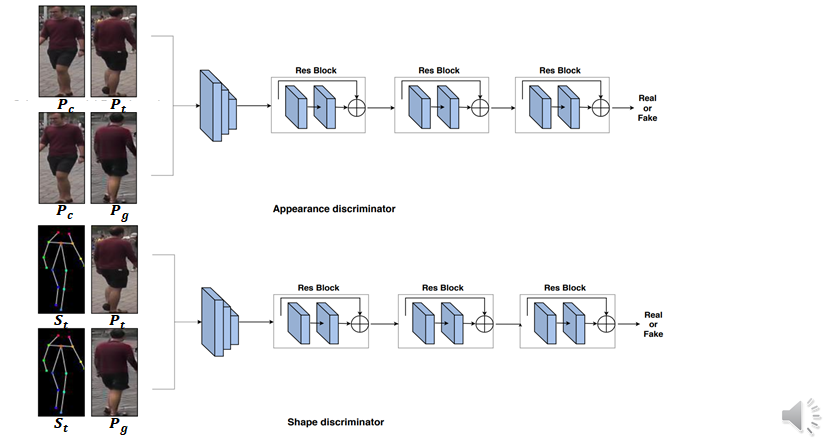 * 위 이미지는 Zhen Zhu et al. "PMAN: Progressive Multi-Attention Network for Human Pose Transfer"에서 가져왔으며 설명을 돕기 위해 재구성 했습니다.
* 위 이미지는 Zhen Zhu et al. "PMAN: Progressive Multi-Attention Network for Human Pose Transfer"에서 가져왔으며 설명을 돕기 위해 재구성 했습니다.
- 이 논문에서는 생성된 이미지 𝑷𝒈가 조건 이미지 𝑷𝒄와 동일한 사람일 가능성(appearance consistency)과 타겟 포즈 𝑺𝒕와 얼마나 잘 일치하는지(shape consistency) 판단하기 위해 외형 판별기(𝑫𝑨) 및 모양 판별기(𝑫𝑺)라고 하는 두 가지 판별기를 설계합니다.
- 𝐷𝐴 = (𝑃𝑐, 𝑃𝑡) ↔ (𝑃𝑐, 𝑃𝑔), 𝐷𝑆 = (𝑆𝑡,𝑃𝑡) ↔ (𝑆𝑡, 𝑃𝑔)
- 각 판별기의 출력은 각각 RA와 RS, 즉 appearance consistency score (RA)와 shape consistency score (RS)입니다. 각 score는 확률로, CNN의 softmax 레이어를 통해 출력.
- 훈련이 진행됨에 따라 성능이 가벼운 판별자가 실제 데이터와 가짜 데이터를 구별하기에 불충분해지는 것을 관찰했기에 2개의 다운샘플링 컨볼루션 후에 3개의 잔차 블록을 추가하여 판별기를 구축하여 능력을 향상시켰다고 합니다.
Objective Functions
전체 손실함수 adversarial loss와 perceptual loss와 L1 loss를 합쳐서 사용합니다. 식은 다음과 같습니다.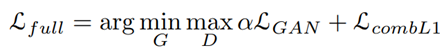
- 𝑳_𝑮𝑨𝑵 : Adversarial loss를 나타내고, DA와 DS에 의해 계산되며 P, P ̂ 및 PS는 각각 실제 인물 이미지, 가짜 인물 이미지 및 인물 포즈의 분포를 나타냅니다.
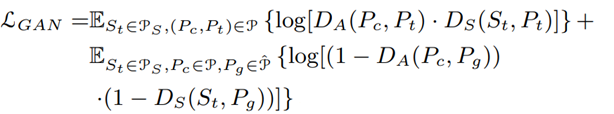
- 𝑳𝒄𝒐𝒎𝒃-𝑳𝟏 : Perceptual loss와 L1 loss를 결합한 것을 나타냅니다.
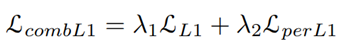 L1 loss는 다음과 같이 생성된 이미지와 타겟 이미지 사이에서 계산된 픽셀의 L1 distance를 나타냅니다.
L1 loss는 다음과 같이 생성된 이미지와 타겟 이미지 사이에서 계산된 픽셀의 L1 distance를 나타냅니다.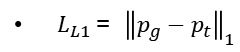
또한, 포즈 왜곡을 줄이고 생성된 이미지를 보다 자연스럽고 매끄럽게 만들기 위해 Perceptual L1 loss 𝐿𝑝𝑒𝑟𝐿1을 사용합니다. high frequency(edge 같은 것들), 스타일 전송 및 포즈 전송 작업에 효과적.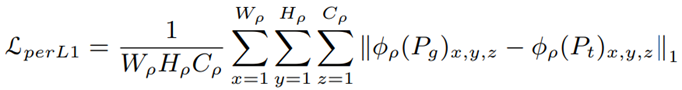
ImageNet에서 사전 훈련된 VGG-19 모델의 두 번째 컨볼루션 레이어를 사용하여 feature map에서의 distance를 계산합니다. 이 방법은 각 픽셀의 값보다 perceptual similarity에 초점을 맞추기 때문에 보다 디테일한 부분을 잘 포착할 수 있습니다.
