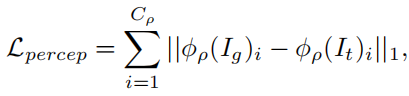
본 논문은 단순화된 계단식(cascaded) 블록이 적용된 생성적 적대 네트워크(GAN)를 사용하여 새로운 사람의 포즈 전송 방법을 제안하고, 각 블록에서 전송할 이미지 특징의 더 중요한 영역을 선택하기 위해 long-range dependency 방식을 사용하는 PoNA 메커니즘을 제안합니다.
논문 : https://arxiv.org/abs/2012.07049
Github : https://github.com/Zhangjinso/PoNA
1. Introduction
Domain/Fields
- 새로운 포즈에 대한 사람 이미지를 합성하는 Human Pose Transfer는 re-identification을 위한 데이터 증강, 이미지 처리, 비디오 생성과 같은 많은 응용 분야에서 매우 중요한 작업임.
- 사람의 condition image와 임의의 포즈가 주어지면 지정된 포즈에서 동일한 사람의 이미지를 사실적으로 생성.
Issue
- Human Pose Transfer의 이슈는 옷의 스타일과 사람의 외모를 포함한 condition iamge의 정보를 condition pose에서 targer pose로 전달하는 것.
Problem
- Person pose transfer는 자체 폐색과 pose의 높은 분산으로 인해 더욱 복잡하며, 이는 관찰되지 않은 픽셀을 추론할 때 모호성을 유발.
- 일부 방법들은 이 문제에 대처하기 위해 더 깊은 네트워크를 사용하거나 3D 사전 지식을 사용하지만, 많은 계산이 필요하고 특히 pose 간의 큰 차이로 인해 추론해야 할 영역이 많은 경우 흐릿한 이미지를 생성할 가능성이 있음.
- 기존 인코더-디코더 프레임워크를 적용한 방법들은 guide를 위한 pose 정보를 활용하지 않고 단순한 attention mechanism을 통해 pose와 image 정보를 융합하여 흐릿하고 엉뚱한 결과를 생성함.
The Proposed Method(briefly)
Image 정보를 학생과 비교하고 pose 정보를 선생님에게 비교하여 학생은 선생님의 지도하에 학습해야 하며 선생님도 학생의 적성과 피드백에 따라 지도법을 변경해야 합니다. 한편으로 선생님의 지도 아래 학생은 점점 더 똑똑해질 것입니다. 한편, 선생님은 학생의 피드백을 받아 학생의 상태에 따라 지도 방법을 조정하여 학생을 더 잘 지도하게 될 것입니다.
즉, 좋은 pose feature는 좋은 iamge 정보를 생성하는데 도움이 되는 반면, 좋은 image feature는 관련 있고 중요한 포즈 특징을 추출하는데 기여합니다.
- 이러한 문제로 인하여 pre-posed image-guided pose feature update 및 post-posed pose-guided image feature update를 사용하여 PoNA(Pose-guided Non-local Attention) 블록이라는 cascaded cross-modal 블록을 제안.
- Cascaded cross-modal 블록을 사용하여 condition pose에서 target pose로 image feature를 점진적으로 전송.
- Pre-posed image-guided pose feature update : self-attention 모듈을 사용하여 pose faeture과 image feature를 결합.
- Post-posed pose-guided image feature update : 관찰되지 않은 픽셀을 추론할 때 모호성을 완화하기 위해 Non-local attnetion mechanism을 제안하며, 이는 필요한 블록 수를 줄이는 데도 도움이 됨.
- Non-local Attention mechanism을 사용하면 image feature에서 더 중요한 영역을 선택하고 변형할 수 있음.
Contribution
- 더 적은 매개변수로 쉽게 훈련할 수 있는 단순화된 계단식 블록(cascaded block)을 사용하여 간단하면서도 효과적인 Generator를 제안.
- 이 방법은 condition image와 target image 간의 높은 편차에 잘 대처하는데 그 이유는 Pre-posed image-guided pose feature가 모델 기반 애니메이션을 위한 리깅 효과와 유사한 image-based transfer를 위한 더 나은 초기화를 제공하기 때문.
- 정보 누락 및 자체 폐색 문제를 잘 처리하는 image feature update에서 중요한 영역을 선택하고 변형하는데 도움이 되는 Pose-guided non-local attention(PoNA) mechanism을 제안.
- 실험을 통해 5가지 최신 방식보다 더 적은 매개변수와 더 빠른 속도로 사진과 같은 결과를 달성한다는 것을 보여주며, re-idntification을 위한 데이터 부족을 완화할 수 있다는 것을 보여줌.
2. Related Work
(생략)
3. The Proposed Method
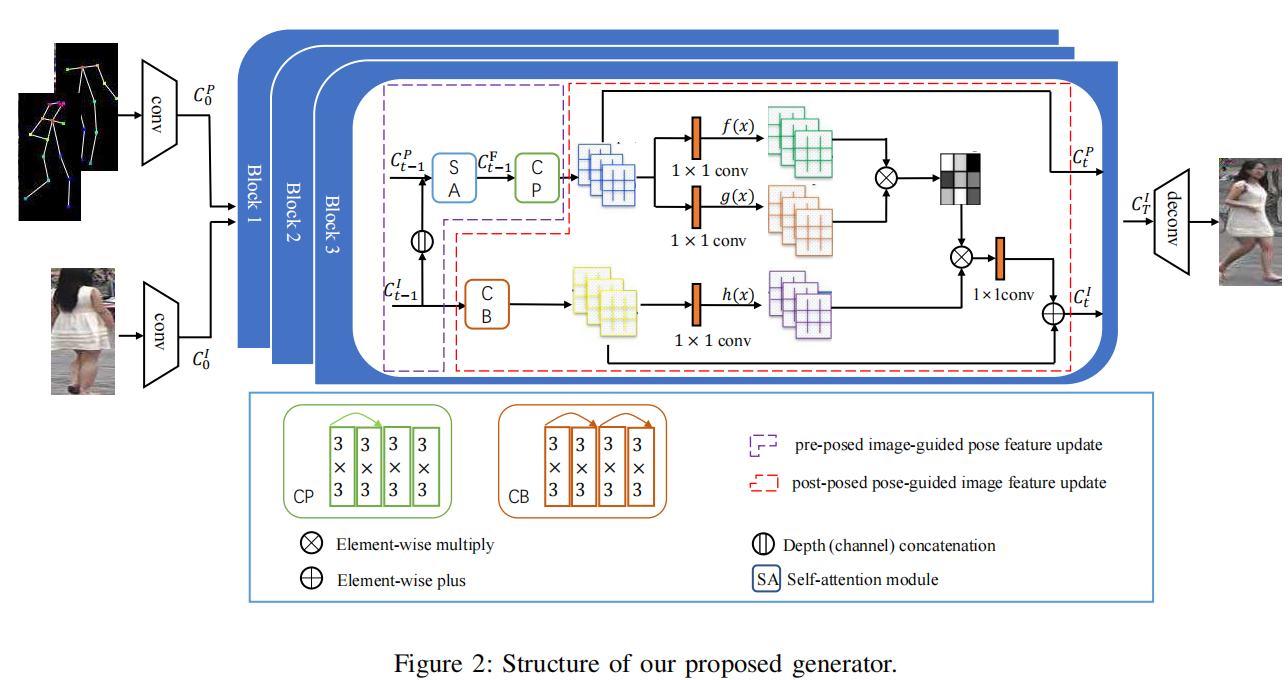
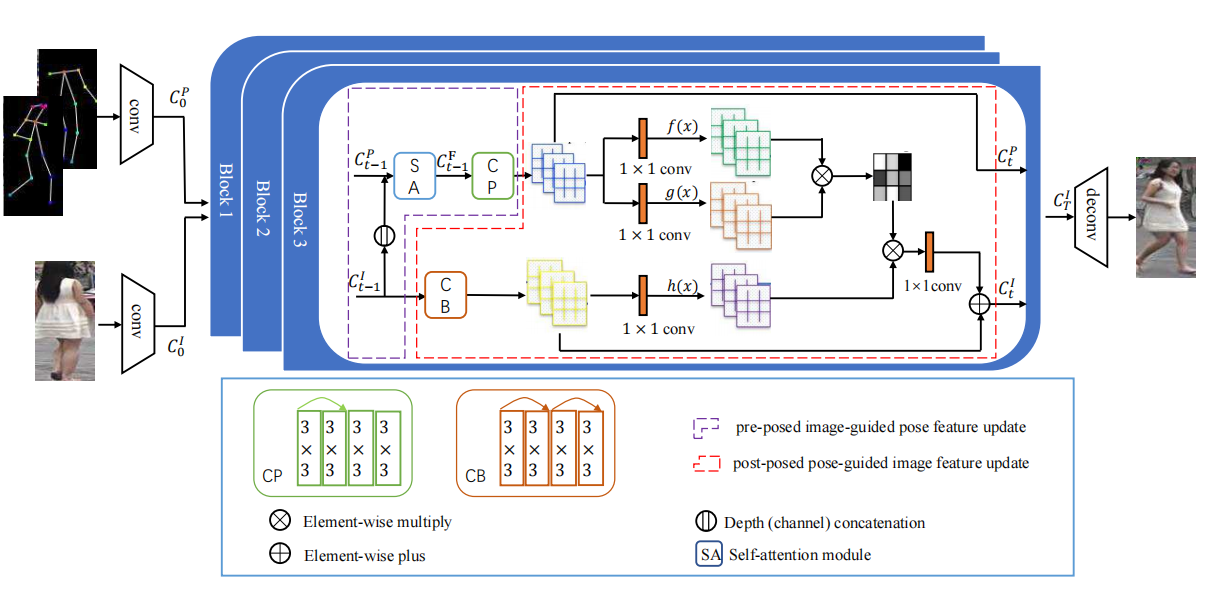
Generator는 두 개의 인코더, 몇개의 블럭, 하나의 디코더로 구성되어 있습니다.
위의 그림과 같이 condition image와 target image를 concat하여 pose feature를 update하기 위해 입력되고 condition image가 image feature를 update하기 위해 입력됩니다. 최종 출력은 target image와 비슷한 이미지가 생성됩니다.
Encoder
- Pose 인코더와 appearance 인코더는 두 개의 down-sampling 컨볼루션 레이어를 가지며 모두 동일한 구조.
- Pose 인코더의 입력으로 condition pose와 target pose를 concat한 값을 받는데, 이렇게 하면 모두의 정보를 보존할 수 있음.
- Appearance 인코더는 condition image를 입력으로 받아 condition image의 정보를 인코딩.
Pose-guided Non-local Attention Block
- 여러 개의 PoNA 블록으로 image feature를 condition pose에서 target pose로 점진적으로 전송할 수 있으며, 각 PoNA 블록은 분리되어 있으며 구조는 동일.
- 여러 PoNA 블록은 디코더에 입력된 최종 image code를 출력하여 최종 이미지를 생성하는 반면, 최종 pose code는 버려지게 됨.
- 앞에서 설명한 것처럼, PoNA 블록은 pose feature가 image feature의 변환을 안내하도록 하는데 사용됨.
- PoNA 블록의 처음 image code와 pose code를 채널에 따라 concatenate하여 image feature와 pose feature를 모두 포함하는 fusion code로 업데이트되고 fusion code를 사용하여 attention map을 계산.
- 또한, 4개의 컨볼루션 레이어를 거쳐 image code가 업데이트되며, 최종 image code를 얻기 위해 pose code에 대한 attention map을 사용하여 image feature의 변환을 수행.
Image-guided Pose Code Update
- 이미지 경로와 포즈 경로를 거치기 전에 pose code와 image code를 채널에 따라 concat하여 pose feature가 image feature 변환에 대한 정보를 알 수 있도록 함.
- 또한, Concat된 fusion code를 사용하여 더 중요한 영역을 선택하기 위해 self-attention 모듈을 사용.
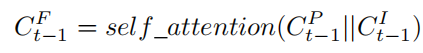
- 포즈 경로의 경우 4개의 컨볼루션 레이어가 있는 블록(CP)을 사용하여 fusion feature 정보를 인코딩하고, 이 4개의 컨볼루션 레이어는 fusion code에서 유용한 feature를 추출할 수 있음. 또한, 이 레이어 중 하나는 채널 수를 절반으로 줄여 출력 크기를 입력과 동일하게 만듦.
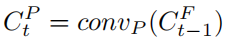
Pose-guided Non-local Attention
- Pose transfer는 condition pose에서 target pose로 패치를 이동시키고 서로 다른 패치 간의 관계를 처리하는 것이며, 이러한 관점에서 pose는 condition 패치에서 추출할 위치와 target 패치로 넣을 위치를 찾는 동시에 패치 간의 관계를 유지하여 전송을 가이드 함.
- PoNA 블록에서 이러한 변환은 업데이트된 pose code의 모든 요소의 중요성과 모델이 한 위치에 주의를 기울이는 정도(집중하는 정도)를 나타내는 attention map (softmax에 의해 계산된 0과 1 사이의 값으로 표시) 에 의해 실현.
- 기존 non-local attention 메커니즘은 동일한 feature의 query, key 및 value를 포함하고 key와 query(가이드 역할) 간의 유사성을 계산하여 attention map을 계산하고 이 값을 업데이트하여 더 중요한 영역을 선택함.
- 그러나 이 논문에서는 pose feature와 image feature가 서로 다른 latent space에 있으며 image feature와 pose feature 간의 유사도를 계산하기가 어렵기 때문에 신뢰할 수 있는 attention map을 얻기 위해 업데이트된 pose feature에서의 key와 query를 가지고 유사도를 구하고, softmax를 적용하여 attention map을 얻음.
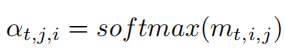
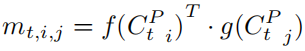
Pose-guided Image Code Update
- Image code는 4개의 컨볼루션 레이어를 거쳐 업데이트되고 1 × 1 컨볼루션 레이어를 거쳐 value 공간에 삽입됨.
- Attention map αt는 image code에서 중요한 영역을 선택하고 image feature를 재배열하여 기존 image code를 변형.
- Attention layer의 출력은 ot = (ot1, ot2, ... , otj, ... , otN)이며, ot는 t번째 region이 전체 region과 얼마만큼의 관계가 있는가 정도로 생각할 수 있음.
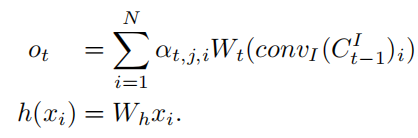
- Wt, Wh는 가중치 행렬이며 1x1 컨볼루션 레이어로 구현되고, h(xi)는 Wt(convI())와 같음.
- 또한, 초기값이 0인 learnable한 매개변수 γ(점차적으로 학습됨)에 의해 attention layer의 출력을 input image code와 결합 (residual connection 사용).
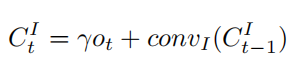
Discriminator
- Target image가 condition image와 동일한 사람을 포함할 가능성 (appearance consistency)과 생성된 이미지가 target pose (pose consistency)와 얼마나 잘 일치하는지 판단하기 위해 appearance discriminator (DA)와 pose discriminator (DP)를 사용.
- DA : (condition image, generated image) ↔ (condition image, target image)
- DP : (target pose, generated image) ↔ (target pose, target image)
- 이러한 입력 값은 down-sampling 후, 컨볼루션 레이어 (정규화 및 ReLU 포함)와 여러 residual block(self-attention module 포함)을 지남.
- 각 discriminator들의 출력은 softmax 레이어에 의해 계산된 appearance consistency score (SA)와 pose consistency score (SP). 따라서, 최종 score는 두 점수를 곱한 값. S = SA x SP
Loss Function
이 논문에서는 CGAN Loss , L1 Loss 및 Perceptual Loss를 조합하여 전체 Loss Function으로 사용합니다.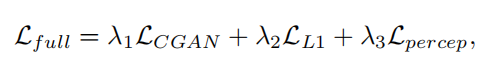
-
Conditional adversarial loss
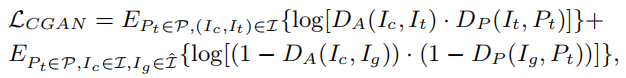
-
L1 loss
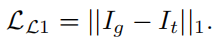
-
Perceptual loss
사전 훈련된 CNN에 의해 추출된 feature map 간의 L1-distance가 생성된 이미지를 더 자연스럽게 보이게 하고 구조적 차이를 줄여 style transfer와 pose transfer를 잘 수행한다는 것이 증명됨.
(VGG-19 사용)