
- 전체보기(161)
장바구니(cart) 기능 Redis 구현
장바구니 CRD 구현 사용자에게 장바구니 기능 제공하는데 Mysql을 사용할 수도 있다. 하지만 비용임으로 상대적으로 저렴한 Redis 사용하기로 결정했다. 기능은 장바구니 생성, 장바구니 목록 읽기, 장바구니 목록 삭제 구현했다. redisConfig에서는 red
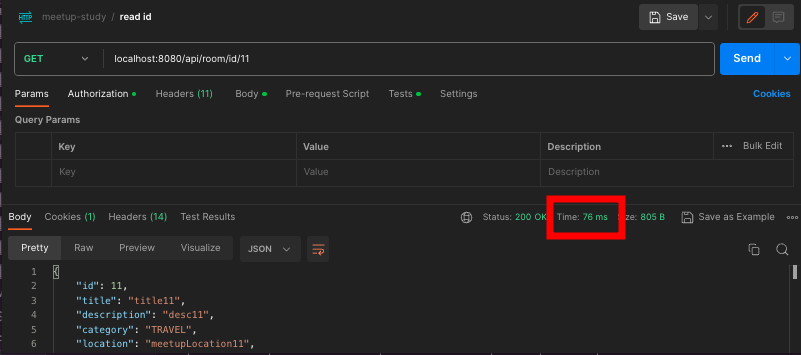
[리팩토링] Query 횟수 줄이기 (Redis @Cacheable)
@Cacheable를 roomController의 Getroom메소드에 적용하니 아래처럼 호출 API 호출 시간이 대략 5배 정도 빨라졌다. 콘솔 확인해보면 처음 요청땐 SQL 요청하고, 그 이후에는 SQL 요청하지 않는다. DB 부하를 분산시킬 수 있게 됐다. pos
[리팩토링] 쿼리 성능 개선 (Fetch Join , PageNation)
현재 코드는 프론트엔드에서 모임 목록 페이지에 접근하면 1번 페이지 열리면서 가장 최근의 Room 데이터 10개 호출해서 렌더링한다.Room 테이블은 HostUser, Category, RoomImage 테이블과 관계 맺고 있는 상태다. Dto 변환시 각 테이블 데이터
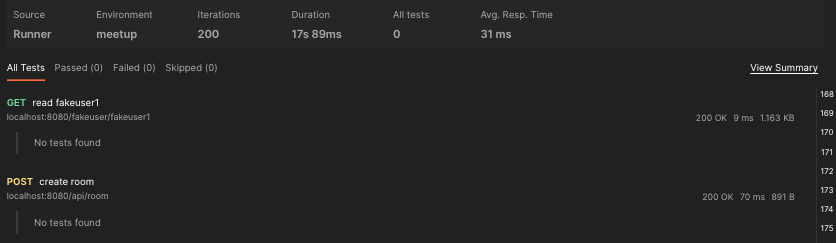
[리팩토링] 쿼리 개선 및 성능 테스트 (Fetch Join , N+1)
Fetch join 전 후 코드 및 쿼리 비교 user 부분 리팩토링 중이다. 상황은 다음과 같다. user entity는 userImage entity와 1:1 관계를 가진다. user는 6명이다. 코드는 아래와 같다. 작동 순서는 user list 가져온 후 U
[리팩토링] 중복 쿼리 제거로 인한 성능향상
컨트롤러 각 메소드에서 요청 유저 토큰 인증 유효성 체크 코드가 중복이었다. 요청 쿼리 중복 제거를 위해 jwt 필터에서 요청시 유저유효성 확인하게 하고 각 컨트롤러에서는 토큰에서 유저 정보 받아와서 사용하도록 중복 코드 제거했다. 또한 예외처리 로직을 전부 서비스 클
[리팩토링] 계획
meetup 프로젝트는 기능 구현에 중점을 두고 개발했다. 기능 작동되니 다음 단계는 코드의 가독성, 중복제거, shell script, 테스트 등 수정 계획이다.한 주동안 어떻게 하면 리팩토링 할 수 있는 안목을 기를 수 있을까 찾아다녔다. 유튜브 둘러보고, 도서관에
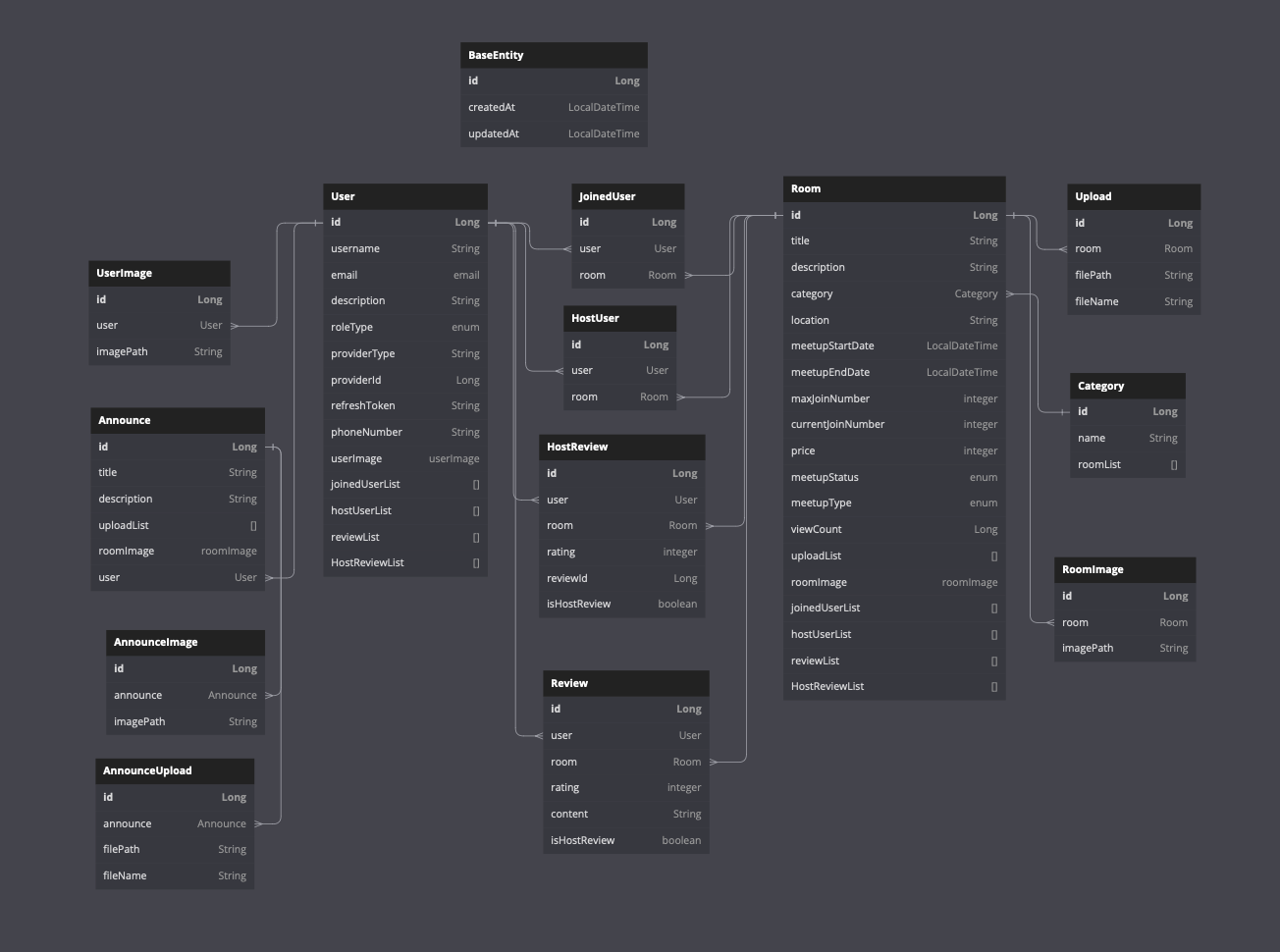
[중간 회고 2] DB 모델링
https://user-images.githubusercontent.com/88143547/242181990-5c620932-8bb1-4c4e-a58d-37413b798494.png!\[](https://velog.velcdn.com/images/do
ARRAY
array• 같은 자료형을 가진 연속된 메모리 공간으로 이루어진 자료구조, 주소값으로 구성• Index를 통한 Random access가 가능하므로 Constant Time O(1)에 접근이 가능하다.static array = 생성될때 고정된 크기, 일반적 방법으로 추
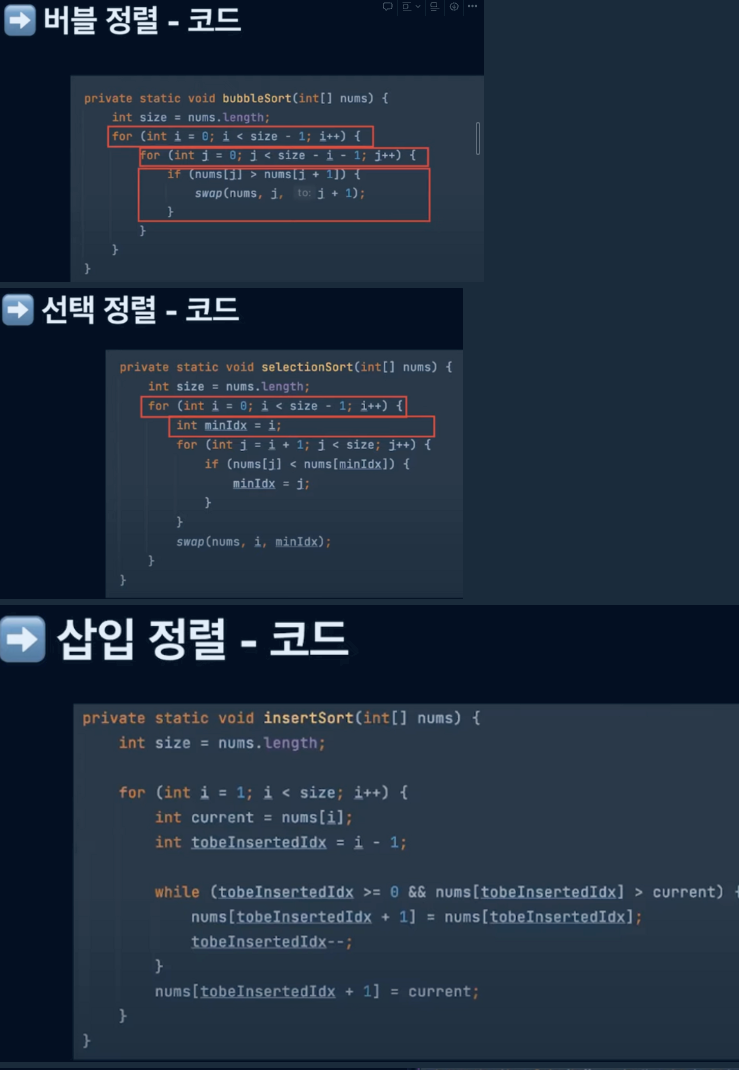
정렬
정렬에 대해 설명해주세요. \- == 정렬알고리즘은 일정 순서대로 열거하는 알고리즘을 말합니다. 버블정렬, 선택정렬, 삽입정렬, 병합정렬, 힙정렬, 퀵정렬이 있습니다. 정렬알고리즘이 중요한 이유는 탐색을 용이하게 합니다. \- 버블정렬 = 인접한 두
DFS, BFS
DFS, BFS에 대해서 설명해주세요.==그래프 탐색하는 방법으로 DFS는 부모로부터 한쪽 방향의 맨 아래지식까지 쭉 탐색후, 그 직전의 부모의 자식탐색하는식으로 지그재그로 탐색하는 방법입니다. BFS는 부모로부터 직계자식을 탐색하고, 그다음 자식의 자식들을 탐색하는
BSP 편향
BST의 최악의 경우의 예와 시간복잡도에 대해서 설명해주세요.== 예를들어 1부터 10까지 순차적으로 BST에 저장했다면, BST의 형태는 리스트와 같아집니다. 이 경우를 최악의 경우라고 하며 시간복잡도는 O(n)이 됩니다.
TREE
Tree, Binary Tree, BST, AVL Tree에 대해서 설명해주세요.==트리는 배열이나 리스트나 스택이나 큐처럼 선형이 아니라 나무처럼 생긴 자료구조, 바이너리 트리는 자식이 무조건 2개인 트리 자료구조, 바이너리서치트리는 부모의 왼쪽은 부모보다작은 오른쪽
스택과 큐
Stack, Queue에 대해서 설명해주세요.==스택은 선형 자료구조의 일종으로 마지막에 저장한 데이터를 가장 먼저 꺼내게 되는 LIFO(Last In First Out)방식의 자료구조 입니다. 스택의 사용 예시로는 웹 브라우저의 방문기록(뒤로가기), 실행 취소(und
리스트와 셋 차이
List와 Set의 차이에 대해서 설명해주세요.==List는 중복된 데이터를 저장하고 순서를 유지하는 선형 자료구조이고, Set은 중복되지 않은 데이터를 저장할 수 있고, 일반적으로 순서를 유지하지 않는 선형 자료구조입니다.
배열과 링크드 리스트 차이
배열과 링크드 리스트의 차이를 설명해주세요.\*\*\*\*==배열은 메모리상에 순서대로 데이터를 저장합니다. 반면 링크드 리스트는 다음 데이터의 위치에 대한 포인터를 가지고 있는 구조입니다. 배열은 데이터를 인덱스로 조회할 수 있기 때문에 인덱스 조회성능이 높고, 데이

시간복잡도 계산방법
시간복잡도 계산 방법== 컴퓨터 마다 성능이 다르기때문에, 실행시간(running time)이란 함수, 알고리즘 수행에 필요한 스탭 수로 계산합니다. 함수의 실행시간을 점근적 분석을 통해 실행시간을 단순하게 표현하며 점근적 표기법으로 표현한다.업로드중..
리스트
리스트 \[]== 순차적으로 중복가능 데이터 저장하는 자료구조 입니다. 순차적으로 데이터 접근할수있고, 다양한 데이터 유형 저장할 수 있습니다. 인덱스를 알지 못하면 검색시 O(n) 성능 떨어집니다.
해시, 해시충돌 회피
해시== 해시는 키 밸류 형태로 데이터 저장하는 자료구조 입니다. 파일 등 데이터를 매개변수로 해시펑션을 통해 해쉬코드 만들고 인덱스로 반환하고 해쉬버킷에 데이터를 저장하는 자료구조 입니다. 해쉬코드로 다이렉트 데이터 접근가능. 하지만 해쉬버킷에 값이 많으면 검색시간
이진탐색트리, 자가균형트리
이진탐색트리==이진탐색트리는 왼쪽자식은 부모보다 작고, 오른쪽 자식은 부모보다 큰 이진트리입니다. 삽입 검색 삭제가 모두 트리 높이인 logN~N만큼의 시간복잡도를 가집니다. 하지만 편향될 위험이 있어서 자가 균형트리를 사용합니다.왼족 자식은 부모보다 작고, 오른쪽 자