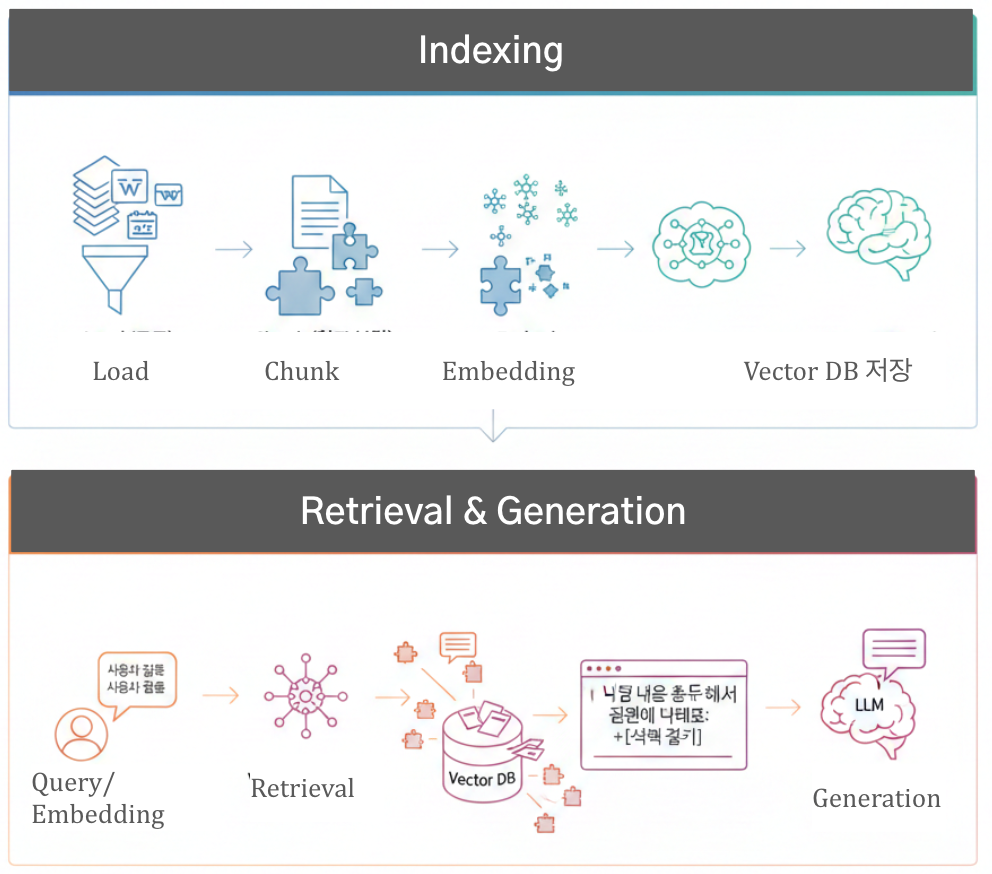
RAG(Retrieval-Augmented Generation) 서비스는 기존 LLM이 구조적으로 가지는 한계를 보완하기 위해 등장했다. 핵심은 “모델 내부 파라미터에만 의존하지 않고, 외부 지식을 동적으로 결합한다”는 점이다. 아래에서 LLM의 단점 → RAG가 어떻게 보완하는지 구조적으로 설명하겠다.
1️⃣ 최신 정보 반영 불가 (Knowledge Cutoff)
LLM의 한계
- LLM은 훈련 시점 이후의 정보를 알 수 없다.
- 모델 재학습 없이 최신 데이터 반영이 불가능
- 실무 서비스에서는 정책, 보고서, 사내 문서, 최신 뉴스 대응이 어렵다.
RAG의 보완
- Vector Store / Search Index에서 실시간 또는 최신 문서를 검색
- 검색된 문서를 프롬프트 컨텍스트로 주입
👉 모델 재학습 없이 최신 정보 활용 가능
2️⃣ 환각(Hallucination) 문제
LLM의 한계
- “모른다”보다 그럴듯한 거짓 답변을 생성
- 특히:
- 숫자
- 계약 조건
- 법률·의료·정책 정보
에서 치명적
RAG의 보완
- 답변의 근거를 실제 문서 스니펫에서 가져옴
- LLM은 창작자가 아니라 요약·추론 엔진 역할
👉 근거 기반 응답 (Grounded Answering)
👉 감사(Audit)·출처 제시 가능
3️⃣ 사내 / 비공개 지식 활용 불가
LLM의 한계
- 학습 데이터에 없는:
- 사내 문서
- 내부 위키
- 고객별 데이터 - 개인정보·보안 이슈로 재학습도 어려움
RAG의 보완
- 사내 문서를:
Load → Chunk → Embed → Vector DB- 질의 시 관련 문서만 검색하여 사용
👉 보안 유지 + 맞춤형 지식 활용
4️⃣ 재학습(Fine-tuning)의 비용과 비효율
LLM의 한계
- Fine-tuning:
-비용 高
-시간 長
-지식 변경 시 반복 필요 - 지식 수정이 “모델 전체”에 영향을 줌
RAG의 보완
- 지식과 추론을 분리
-지식: Vector Store
-추론: LLM - 문서 수정 = 인덱스 재생성만 필요
👉 운영 비용 절감 + 유지보수 용이
5️⃣ 긴 문맥 처리의 한계 (Context Window)
LLM의 한계
- 전체 문서를 통째로 넣을 수 없음
- 길어질수록:
- 비용 증가
- 성능 저하
RAG의 보완
- 질의와 가장 관련 있는 Chunk만 선택
- Top-K 검색 + 재정렬(Re-ranking)
👉 짧고 정밀한 컨텍스트로 성능 극대화
6️⃣ 신뢰성·설명 가능성 부족
LLM의 한계
- “왜 이 답이 나왔는가?” 설명 어려움
- 기업·공공 서비스에 부적합
RAG의 보완
- 응답 근거 문서:
- 문서명
- 페이지
- 섹션 - Explainable AI 구성 가능
👉 엔터프라이즈/공공 서비스 적합
🔍 정리 한 장 요약
| LLM 단점 | RAG 보완 |
|---|---|
| 최신 정보 불가 | 실시간 문서 검색 |
| 환각 | 근거 문서 기반 응답 |
| 사내 지식 미활용 | Private 데이터 연동 |
| 재학습 비용 | 지식-추론 분리 |
| Context 한계 | 관련 Chunk만 사용 |
| 설명 불가 | 출처 제시 가능 |
🎯 한 문장 정의
RAG는 “기억력이 없는 천재”인 LLM에게
외부 지식 저장소와 검색 능력을 붙여
신뢰 가능한 실무형 AI로 만드는 아키텍처다.

천천히 고민하면서 걷는 개발자