LLM + RAG 시스템
1.RAG 시스템 개요
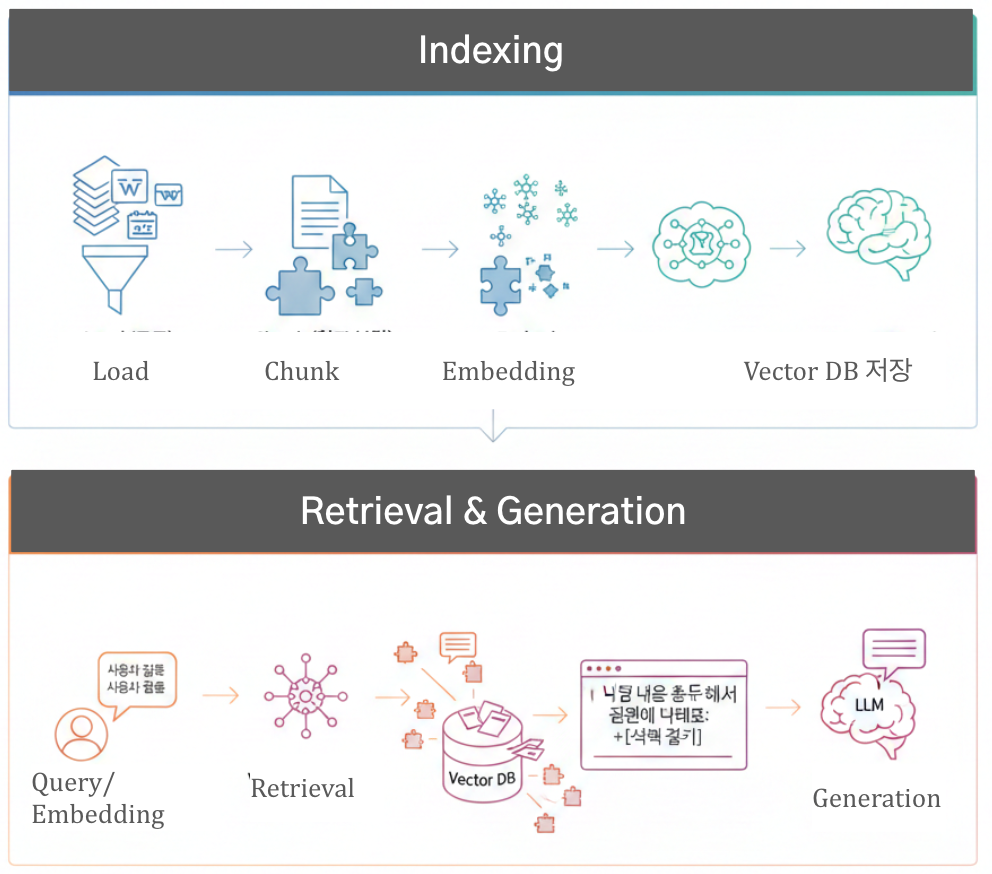
RAG(Retrieval-Augmented Generation) 서비스는 기존 LLM이 구조적으로 가지는 한계를 보완하기 위해 등장했다. 핵심은 “모델 내부 파라미터에만 의존하지 않고, 외부 지식을 동적으로 결합한다”는 점이다.아래에서 LLM의 단점 → RAG가 어떻게
2.로드된 문장을 짤라볼까?

개요 각 방식이 “어디를 기준으로 자르느냐 + 얼마나 똑똑하게 자르느냐”가 포인트라 생각하면 편합니다. 말씀하신 5개를 역할/원리/장단점/추천 사용처 중심으로 정리해볼게요. 주요 개요 사항을 아래와 같이 정리하고자 한다. 1. 문자단위로 분할하기 > Charact
3.잘 만든 Chunking 어떤 개이득을 주는가?
RAG에서 청크를 “어디를 기준으로, 얼마나 똑똑하게 나누느냐”는 단순 전처리가 아니라 전체 RAG 성능을 결정하는 핵심 요소입니다. 청크 품질은 임베딩 → 벡터 검색 → LLM 답변 생성까지 연쇄적으로 영향을 주며, 잘못된 청크는 아무리 좋은 모델을 써도 성능이 떨어
4.Embedding(문자를 숫자로...)
임베딩은 "사람의 언어(문자)" 를 "기계가 거리 계산을 할 수 있는 의미공간(벡터)"으로 변환하는 과정Chunking이 정보를 다루기 좋은 단위로 쪼개는 과정이라면, Embedding은 그 단위들 사이의 의미적 관계를 수학적으로 정의하는 과정문자열은 기계 입장에서 동
5.Embedding을 Python으로 구현
Huggingface, OpenAI 등 Embedding 관련 모듈을 유지보수성과 확장성을 길게 고려한 설계, 구체적인 구현(OpenAI, HuggingFace)에 의존하지 않고 Interface에 의존
6.패키지 변화가 큰 프레임워크 - LangChain
LangChain은 처음부터 완성된 프레임워크로 설계된 것이 아니라,LLM 활용 패턴을 빠르게 실험하기 위한 실험적 도구커뮤니티 주도 빠른 기능 추가에서 출발했습니다.👉 그 결과:초반에는 “일단 되는 코드” 위주설계 일관성보다 속도와 확장성이 우선사용자가 늘면서 구조
7.VectorStore?
LangChain 관점에서 벡터스토어(Vector Store) 는단순히 “벡터를 저장하는 DB”가 아니라, RAG 파이프라인 전체를 연결하는 검색 추상화 계층으로 이해하는 것이 가장 정확합니다.LangChain은 문서 기반 LLM 애플리케이션을 다음과 같은 표준 파이프
8.Vectorstore 구현
어플리케이션이 특정 DB 브랜드에 종속되지 않게 만드는 핵심Vectorstore 캡슐화: 메인코드에서 db = FAISS(...)가 아니라, 설정값에 따라 생성된 VectorStore 객체 자체를 다룹니다.Retriever 인터페이스: LangChain에서 가장 권장하
9.GPT vs Gemini vs Claude를 구조 레벨로 더 깊게 (block diagram + pseudo code) 까지 ...
🔧 Core ideaDense (or partially sparse) TransformerStrong tool + agent orchestration layerIterative reasoning loop (hidden chain-of-thought)⚙️ Pseudo
10.LLM Architecture
최신 LLM 아키텍처는 한마디로 정리하면👉 “Transformer 기반 + MoE + 멀티모달 + 에이전트 구조” 로 진화했다고 보면 정확합니다.Transformer-based architectures in ChatGPT, Claude, and Gemini모든 최신
11.LLM 파인튜닝/훈련 생명 주기
LLM 파인튜닝의 생명주기를 단순한 “단계 나열”로 보면 실제 운영에서 실패하기 쉽습니다. 핵심은 각 단계가 독립이 아니라 피드백 루프를 형성하는 시스템이라는 점입니다. 아래는 실무 기준으로 재구성한 lifecycle과 각 단계에서 흔히 놓치는 포인트입니다.목표: “모