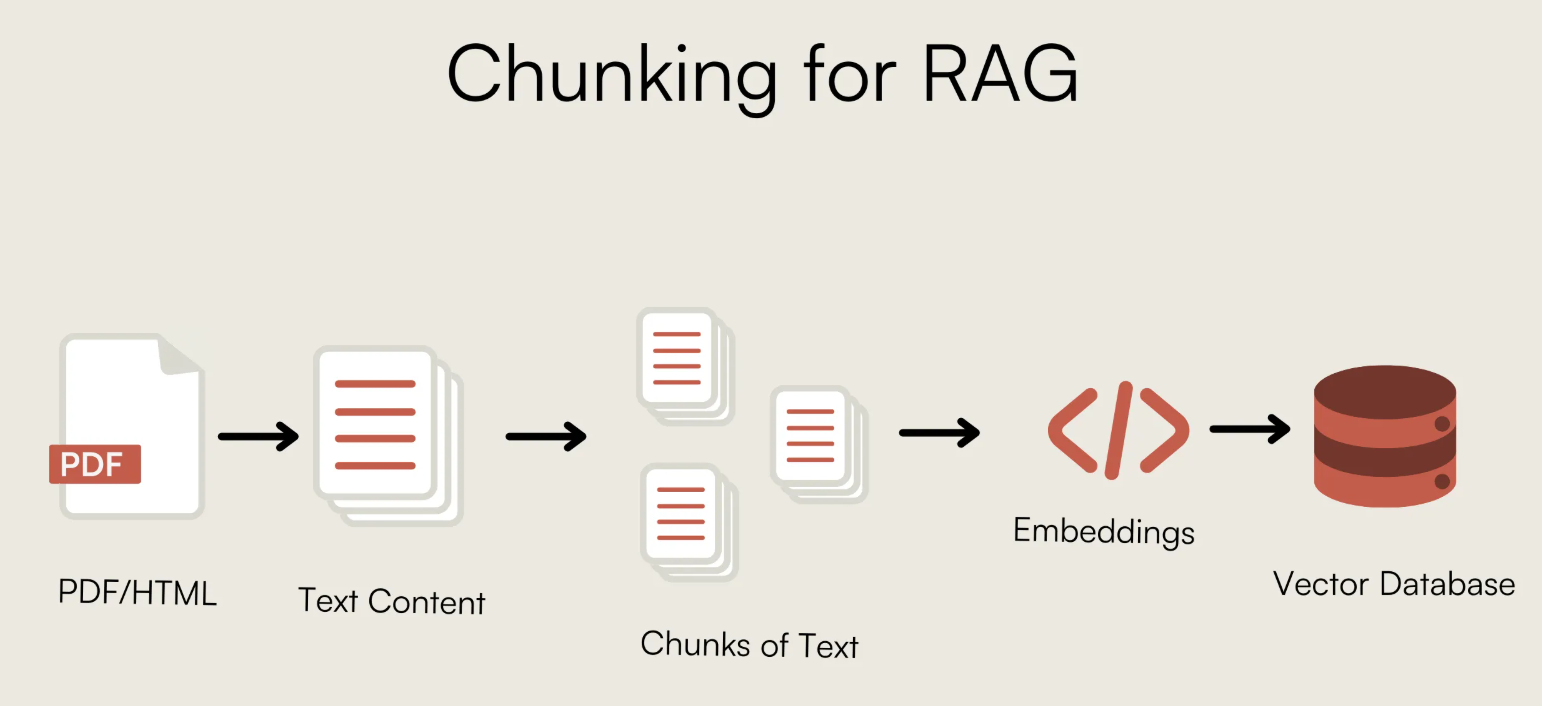
개요
각 방식이 “어디를 기준으로 자르느냐 + 얼마나 똑똑하게 자르느냐”가 포인트라 생각하면 편합니다.
말씀하신 5개를 역할/원리/장단점/추천 사용처 중심으로 정리해볼게요.
주요 개요 사항을 아래와 같이 정리하고자 한다.
1. 문자단위로 분할하기
CharacterTextSplitter
2. 문자단위로 재귀적으로 분할하기
RecursiveCharacterTextSplitter
3. 토큰단위로 분할하기
3-1. LLM/임베딩 "모델토큰" 기준
TokenTextSplitter (tiktoken, OpenAI 등)
SentenceTransformersTokenTextSplitter
HuggingFace tokenizer 직접 사용한 커스텀 splitter(BERT, KoBERT, LLaMA 등)
3-2. NLP 라이브러리의 “언어학적 토큰” 기준
spaCy: 문장, 단어(token) 단위 split
NLTK: sent_tokenize, word_tokenize
KoNLPy: 형태소/어절/단어 단위 (한국어)
4. 의미 단위로 분할하기
SemanticChunker / Embedding 기반
SemanticChunker (LangChain)
직접 sentence-transformers 임베딩을 써서 “토픽이 크게 바뀌는 지점”을 기준으로 자르는 방식 등
5. 기타 (구조/포맷 기반 분할)
5-1. 프로그램코드 분할하기
5-2. Markdown 헤더로 분할하기
5-3. HTML 헤더로 분할하기
5-4. JSON 헤더로 분할하기
1. CharacterTextSplitter
기준: 문자 단위(\n, . 같은 구분자)로 “기계적으로” 잘라냄
from langchain_text_splitters import CharacterTextSplitter
splitter = CharacterTextSplitter(
separator="\n",
chunk_size=1000,
chunk_overlap=0,
length_function=len,
)
docs = splitter.create_documents([text])특징
- 단순함: 구분자 기준으로 문자열 길이만 보고 자름.
- 언어/문장 구조 무시: 문장 중간에서 짤리는 경우 흔함.
- 구현이 단순해서 테스트용/샘플 코드로 많이 씀.
장단점
✅ 매우 빠르고 의존성 없음
✅ 구현/이해가 가장 쉬움
❌ 문단/문장 경계를 전혀 고려 안 함
❌ 긴 문장, 코드, 수식 등이 어색하게 쪼개질 수 있음
추천 사용처
- “일단 대충 쪼개서 돌려보자” 수준의 PoC
- 텍스트 구조가 크게 중요하지 않은 태스크 (예: 키워드 검색용 벡터 인덱스 등)
2. RecursiveCharacterTextSplitter
기준: 큰 단위 → 작은 단위로 “점점 더 잘게” 자르는 방식, 예: ["\n\n", "\n", " ", ""] 순으로 시도
from langchain_text_splitters import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(
separators=["\n\n", "\n", " ", ""], # 문단 → 문장 → 단어/문자
chunk_size=1000,
chunk_overlap=200,
length_function=len,
)
docs = splitter.create_documents([text])특징
- 먼저 큰 단위(문단)에서 chunk를 만들려고 시도하고, 안 맞으면 점점 작은 단위로 쪼갬.
- 구조를 완벽하게 이해하는 건 아니지만, “가능하면 문단/문장 경계를 지키려는” 똑똑한 문자 분할기.
장단점
✅ CharacterTextSplitter보다 문단/문장 보존이 훨씬 좋음
✅ 여전히 의존성 거의 없음
✅ LangChain에서 가장 많이 쓰는 기본 splitter
❌ 여러 단계로 나누기 때문에 Character보다는 약간 느릴 수 있음
❌ 언어/문장 구조를 깊게 이해하는 건 아님
추천 사용처
- 기본값으로 쓰기 좋음: RAG, 문서 QA 대부분의 케이스에 무난한 선택
- PDF/블로그/리포트 등 문단 구조가 있는 일반 문서 chunking
3. TokenTextSplitter
기준: 토큰 개수 기준으로 자름 (tiktoken, OpenAI 토크나이저 등)
from langchain_text_splitters import TokenTextSplitter
splitter = TokenTextSplitter(
chunk_size=256, # 토큰 단위
chunk_overlap=32,
)
docs = splitter.create_documents([text])특징
- LLM이 실제로 보는 단위(토큰)를 기준으로 자르기 때문에
- 프롬프트 길이/컨텍스트 윈도우 관리에 정확함.
- 문자 길이는 비슷해도 토큰 길이가 많이 달라질 수 있기 때문에, “토큰 기준으로 정확히 자르겠다”가 목표일 때 좋음.
장단점
✅ 토큰 제한 대응에 최적화 (예: 4k/8k/32k 제한 맞추기)
✅ 모델별 토크나이저를 쓸 수 있어 실제 환경과 잘 맞음
❌ 문장/문단 경계를 잘 모를 수 있음 (Character 계열과 비슷한 문제)
❌ 토크나이저 의존성 필요, 아주 약간 느릴 수 있음
추천 사용처
- “한 chunk당 512 토큰 이하”처럼 정확한 토큰 관리가 필요한 경우
- 예: OpenAI / GPT / Claude API 호출 전에 프롬프트 분할
- LLM context 사이즈를 꽉 채워서 넣고 싶을 때
4. SpacyTextSplitter
기준: spaCy의 문장 단위(Sentence) 를 기준으로 자름
from langchain_text_splitters import SpacyTextSplitter
splitter = SpacyTextSplitter(
pipeline="ko_core_news_sm", # 예시 (한국어 모델 있다고 가정)
chunk_size=1000,
chunk_overlap=200,
)
docs = splitter.create_documents([text])특징
- spaCy가 제공하는 문장 단위 분절(Sentence segmentation) 사용.
- 문장 단위로 먼저 나눈 뒤, 그 문장들을 모아서 chunk_size에 맞게 묶는 방식.
장단점
✅ 문장 경계를 정확히 맞출 수 있음 (지원 언어 기준)
✅ 한국어/영어 등에서 문장 구조를 존중한 chunk 생성
❌ spaCy 모델 설치 필요 (용량 + 로딩 시간)
❌ 언어별 모델이 필요해서 세팅 번거로울 수 있음
❌ 아주 긴 문장은 결국 중간에서 잘려야 하는 이슈는 동일
추천 사용처
- 문장 단위 의미 유지가 매우 중요한 작업
- 예: 요약, NLG, 감성 분석, 문장 레벨 QA
- RAG에서 “질문-답변” 형태, “문장 레벨 의미 유지”가 핵심일 때
5. SentenceTransformersTokenTextSplitter
기준: sentence-transformers 토큰화/임베딩 기준으로 자름
보통 SentenceTransformersTokenTextSplitter 는
sentence-transformers 기반 임베딩을 사용할 때,
모델이 처리 가능한 max_seq_length 안에 들어가도록 토큰 기준 분할을 해준다.
from langchain_text_splitters import SentenceTransformersTokenTextSplitter
splitter = SentenceTransformersTokenTextSplitter(
chunk_size=256, # 모델 토큰 단위
chunk_overlap=32,
model_name="sentence-transformers/all-MiniLM-L6-v2",
)
docs = splitter.create_documents([text])특징
- sentence-transformers에서 사용하는 토크나이저/모델의 max_seq_length 기준으로 잘라서,
- 임베딩 시 잘리지 않도록 보장하는 게 목적.
- RAG에서 “임베딩 모델 기준으로 정확히 자른다”는 느낌.
장단점
✅ 사용하는 sentence-transformers 모델과 토큰 단위가 완벽히 일치
✅ 임베딩 모델의 최대 길이 초과 문제를 안정적으로 회피
❌ sentence-transformers 의존성 + 토크나이저 호출 필요 → 속도 약간 손해
❌ 문단/문장 구조까지 자동으로 보존해 주지는 않음 (토큰 길이 위주)
추천 사용처
- RAG나 검색 시스템에서 sentence-transformers 임베딩을 확정적으로 쓸 때
- 예: all-MiniLM-L6-v2, bge-* 등
- “임베딩 모델이 허용하는 최대 길이에 맞춰 잘라야 한다”가 가장 중요한 조건일 때
전체 비교 요약 표
Splitter 기준 구조 이해 의존성 대표 사용처 CharacterTextSplitter문자/문자열 길이 거의 없음 없음 간단 PoC, 빠른 테스트 RecursiveCharacterTextSplitter큰 구분자→작은 구분자 약간 없음 RAG 기본, 일반 문서 chunking TokenTextSplitter토큰 수 거의 없음 토크나이저(tiktoken 등) LLM context 길이 정확 관리 SpacyTextSplitter문장 단위 높음 spaCy + 언어 모델 문장 의미 유지 중요할 때 SentenceTransformersTokenTextSplitterST 토큰 수 거의 없음 sentence-transformers 임베딩 모델 max_seq 맞추기
숙제
실험 플랜 예시
실제로 각 splitter를 비교하는 실험을 한다면, 아래처럼 구성해볼 수 있습니다.
1. 같은 원문 텍스트 준비
예: 2~3페이지 분량의 기술 블로그 글, 논문 초록+본문 일부 등
2. 각 splitter로 chunking
동일한 “대략 500~800 토큰 수준”이 되도록 설정
3. 각 splitter 설정:
Character / Recursive: chunk_size = 1000, overlap = 200
Token: chunk_size = 256 tokens
Spacy: 문장 기준, chunk_size = 1000 chars
SentenceTransformersToken: chunk_size = 256 tokens
4. 평가 항목
(정성) 읽었을 때 의미가 자연스럽게 유지되는가?
(정량) chunk 개수, 평균 길이, 길이 분산
5. RAG라면:
같은 질의를 던졌을 때, retrieval 결과 품질 (정성 평가)
BM25 + embedding 조합했을 때 recall/precision 느낌
결론 정리
“RAG + 일반 문서”라면 RecursiveCharacter 기본
“LLM 토큰 관리 중요”라면 TokenTextSplitter
“임베딩 모델 최대 길이 정확히 맞추기”라면 SentenceTransformersTokenTextSplitter
“문장 경계가 매우 중요”하면 SpacyTextSplitter
향후
- 실제 Python 코드로 5개 splitter를 한 텍스트에 적용해서,
- 각 chunk 예시와 통계(개수, 평균 길이 등)를 비교하는 스크립트도 짜 드릴게요.
