😃[7주차 - Day1]😃

기계학습으로의 전환
초창기 - 지식기반 방식이 주류가 되는 학습이었습니다.
하지만 이 방식에는 한계가 있고, 모든 규칙을 나열하기란 불가능합니다.
이러한 한계를 깨닫고, 기계학습으로의 전환이 시작되었습니다.
인공지능의 주도권이 지식기반에서 기계학습, 심층 학습 순서로 발전되어 왔습니다. 이는 데이터 중심의 접근방식으로 전환이 된 것입니다.
간단한 기계 학습의 예시를 보겠습니다.
예측의 문제가 있다고 하고, 4개의 점이 관측되었을 때 임의의 시간이 주어지면 그 점의 위치를 예측한다고 합시다.
저번주부터 이어져온 것 처럼 이러한 예측은 회귀 문제와 분류 문제로 나뉩니다.
회귀는 목표치가 실수이고 분류는 부류 혹은 종류의 값으로 관측됩니다.
목적함수
어떤 목적 함수의 값을 최적화시키는 파라미터의 조합을 찾는 문제.
이때 목적 함수가 하나의 변수로 이루어져 있다면 일변수 함수에 대한 최적화 문제이고 여러 변수로 이루어져 있다면 다변수 함수에 대한 최적화 문제라고 함
손실함수(loss function), 비용 함수 (cost function), 목적 함수 (objective function): 머신러닝을 통한 예측값이 실제값과 차이(오차)와 관련한 식(equation)
-
이 함수의 값을 최소화 하거나 최대화 하는 목적의 식을 목적 함수라 함.
-
예측값과 실제값의 오차를 최소화하려 하면 비용함수 혹은 손실함수라 함. 즉, 비용함수는 예측값의 오차를 최소화하기 위해 최적화된 식이어야 함.
MSE(Mean Squared Error)
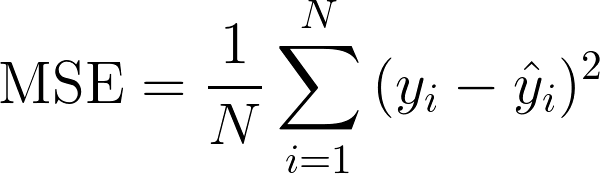
기계학습?
규칙을 모르는 경우에 인풋과 아웃풋을 가지고
규칙을 유추하는 문제 해결법
오버피팅과 언더피팅을 주의하며 모델 선택하는 작업을 반복해야 합니다
오버피팅은 bias는 작지만 variance가 큽니다. 언더피팅은 vice versa 이구요. bias-편향과 variance-분산은 trade-off 관계 - 상충되는 관계입니다.
기계학습의 목표는 낮은 편향과 낮은 분산을 가진 예측 모델을 만드는 것이 목표!!!
크로스 밸리데이션 - 데이터가 적을때, 여러번 나눠서 평균값 식으로 9개로 트레인 1개로 벨리데이션, 또 10번 반복하는 방법
부트스트랩 - 복원 추출 방법, 데이터에 치우침이 있을 때 샘플링 해서 훈련
현대 딥러닝은 용량-capacity가 충분히 큰 모델을 선택한 다음,
규제화를 통해서 정확하게 맞추는 식으로 진행하는 것이 추세입니다.
데이터확대 - data augmentation - 데이터를 확대시켜서 일반화 능력을 향상시키는 것 - 회전이나 왜곡을 살짝 시켜서 변형시키고 사용하는 것 - 약간 재활용?
규제 방법 중 하나에 가중치 감쇠 방식이 있는데 모델이 가지고 있는 가중치를 작게 조절하는 규제 기법입니다.
