😃[7주차 - Day2]😃

기계학습에서의 수학
수학은 목적함수를 정의하고, 목적함수의 최저점을 찾아주는 최적화 이론을 제공합니다. 우리가 만든 가설 = 모델이라고 하는 것의 매개변수를 찾는 과정이며, 이 과정을 최적화 이론에 기반하고 있습니다.
선형대수 복습
텐서나 벡터로 결과값을 유추해내는 과정이 선형대수를 배우는 이유
주어진 데이터가 공간안에 존재하고, 공간안에서 연산이 일어났을 때, 어떤 영향을 미치느냐에 대한 설명이 선형대수를 설명할 수 있습니다.
샘플을 특징 벡터로 표현 -> 붓꽃의 데이터의 각각의 특징(eg. 꽃받침의 길이, 너비 등등)을 각각의 벡터의 차원으로 나타내는 것
모든 데이터를 벡터로 표현할 수 있는데, 행렬은 여러개의 벡터입니다.
트레이닝 데이터를 담은 행렬을 설계행렬 - design matrix 라고 부릅니다.
벡터는 소문자, 행렬은 대문자 볼드체로 사용합니다.
벡터의 내적은 유사도를 판단하는 기준인데, 90도를 기준으로 양의 값과 음의 값으로 나뉩니다. 내적이 크면 클수록 유사도가 크다는 것을 알 수 있고 반대도 마찬가지입니다.
변환 - transformation 이란 곱셈을 통해서 다른 공간에 있던 점이 행렬에 의해서 값이 바뀌는 것. 어떤 선형적인 변환으로 바꿀 수도 있고 90도 회전하는 것도 가능합니다.
텐서는 3차원 이상의 구조를 가진 숫자 배열입니다. 0차는 수-scalar값을 가지고 1차는 벡터, 2차는 행렬 등등 3차원 이상의 배열도 가능합니다.
유사도라고 하는 것 자체가 x1이라는 값과 x2라는 값의 x와의 유사도를 비교할 수 있습니다. 유사도가 높으면 높을수록 비슷한 특징을 많이 가질 수 있다고 판단할 수 있습니다.
NORM?
벡터와 행렬의 크기를 놈-norm으로 측정합니다. 벡터가 가지고 있는 거리를 측정하는 것이 1차 norm, 2차 norm 등등으로 표현합니다. 최대놈-max norm 은 각각의 norm의 절대값의 최대값을 말합니다.
1차 놈은 absolute-value norm(manhatten distance)이라고 하고, 2차 놈은 Euclidean norm이라고 합니다.

2차 놈은 아래와 같습니다.
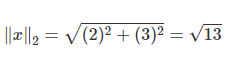
행렬의 크기를 측정하는 것은 프로베니우스 놈이라고 부릅니다.
norm을 사용하는 경우는 예측값과 실제값의 벡터의 형태로 결과값을 낼 때, 유사한지 아닌지 판단하는 경우가 첫째이고, 두번째 경우는 규제를 사용할 경우이다. 주어져 있는 손실함수를 낮추는 파라미터 w 혹은 세타를 찾고 싶을 경우에 사용합니다. 오버피팅을 방지하기 위해서 바운더리 안에서 이동하게 하고 싶을 때 L2-norm을 사용해서 원의 형태로 규제를 겁니다.
퍼셉트론?
분류기 모델입니다. 입력이 벡터로 들어왔을 때 요소를 얼마만큼 더 받을지 뉴런의 모델과 비슷합니다. 더 받아들이면 증폭을 시키고 덜 받으면 감쇠를 시킵니다. 각각의 요소들을 곱하고 다 더하는 것 == 내적입니다.
내적을 했을 때의 결과값은 scalar 값인데 활성함수 -> 계단함수를 사용했을 때 선형대수 측면에서 봤을 때 내적에 의해 표현이 됩니다.
필터링!
요거를 다층으로 만들 수도 있습니다. 여러 개의 퍼셉트론으로 기존과 같은 입력벡터로 출력을 여러개 만들 수 있고, 퍼셉트론 하나마다 d개의 가중치가 c개만큼 존재합니다.
필터를 여러개 쓴 것과 같은 개념입니다.
다중 퍼셉트론을 계산하는 것은 유사도 계산하는 것과 유사합니다. 이래서 선형대수가 필요하다는 것입니다.
행렬식 - determinant 가 존재해야 역행렬이 존재하는데, 이는 ad-bc와 같이 알고 있는 식입니다.
기하학적으로 봤을 때 행렬식은 주어진 행렬의 곱에 의한 공간의 확장 또는 축소 해석입니다.
원 공간에 대한 부피의 변화를 측정하는 것이 deterministic입니다.
정부호행렬이면 역행렬이 존재!
행렬을 분해하면 뭔가 유용성이 있겠다 특성을 알 수 있겠다 하여 행렬분해를 하는 것이고, 주어져있는 행렬의 고유 벡터, 고유값을 찾는게 고유값 분해입니다.
A라는 애가 공간변환을 하는데 v에다가 람다라는 스케일만 변화시킨 것. 축은 변환이 안되고 크기만 변화하기 때문에 고유한 값을 가짐
방향이 바뀌지 않고, 크기만 변환하는 것이 고유값의 행렬 분해에 의해서 이루어지는 방식 - 추후에 PCA라는 방식을 사용
고유 분해라고 하는 것 자체가 주어진 행렬을 분해해보자고 하는 것.
고유 분해는 고유값과 고유벡터가 존재하는 정사각행렬에만 적용 가능합니다. 이는 한계를 가지기 때문에 그래서 나온것이 SVD - 특잇값 분해 라는 것으로 발전되었습니다. 이는 정사각행렬이 아닌 행렬의 역행렬 계산에 유용하게 사용됩니다.
확률 기초
확률변수와 확률분포
윷놀이에서 {도, 개, 걸, 윷, 모}는 확률변수입니다.
확률분포에서
- 확률질량함수-probability mass function: 이산확률변수-discrete
- 확률밀도함수-probability density function: 연속확률변수-continuous
두 가지로 존재합니다.
확률벡터는 확률변수를 요소로 가지는데 예를 들어, 붓꽃 데이터에서 4차원의 확률벡터로 꽃받침 길이, 너비 등이 있는데 이것들이 다 다르기 때문에 각각을 확률변수라고 할 수 있습니다.
베이즈 정리 -> 사후확률을 추정할 수 있는 문제로 정의됨
최대우도 - 우리가 관심있는 대상에 대해 조금 더 나은 estimation을 하겠다. 매개변수를 모르는 상황에서 매개변수를 추정하는 문제
가우시안 분포 - 평균값과 분산 두가지로만 주어져있는 확률분포를 설명할 수 있습니다. 차원의 확장도 가능. 평균값은 벡터가 되고, 분산은 공분산행렬의 형태로 바뀜
로지스틱 시그모이드 함수는 활성함수로 많이 사용되는 비선형 함수이고, 값을 0-1 사이의 값으로 변환시켜주는 함수입니다.
혼합 분포 - 다양한 분포들을 여러개 사용하여 분포를 설명하겠다라는 방법 (eg. 가우시안 분포 3개를 가져다가 모델을 만듬)
정보이론
사건이 지닌 정보를 얼만큼 정량화 할 수 있나? - 불확실성을 통해 정량화 합니다.
아침에 해가 뜬다와 아침에 일식이 있었다라는 두 사건 중 어느 것이 더 많은 정보를 가지는가?
-> 확률이 작을수록 많은 정보를 가지고 있다.
잘 일어나지 않는 사건의 정보량이 더 많음
-
자기정보 - self information
하나의 사건의 정보량, 정보라는 측면에서 봤을 때 동전에서 앞면이 나오는 사건의 정보량(-log2(1/2))보다 주사위에서 1이 나오는 사건의 정보량(-log2(1/6))이 더 크다. -
엔트로피 - entropy
확률변수 전체 - 이벤트 전체에서 가질 수 있는 사건을 전부 정량화 시키는 것. 모든 사건의 정보량의 기대 값으로 표현합니다.
해당하는 확률변수가 얼마만큼의 정보량을 가질 수 있는지에 대한 지표
교차 엔트로피?
기존의 엔트로피는 하나의 랜덤 베리어블에 대해서 불확실성을 정량화 시킨 것. 두개의 확률분포(P, Q)가 얼마만큼의 정보를 공유하고 있는지에 대한 척도를 교차 엔트로피라고 합니다.
딥러닝의 손실함수로 많이 사용됩니다.
내가만든 모델에 의해서 나오는 예측값과 실제값의 확률분포가 얼마만큼 매치가 되는지 확인하는 요소가 손실함수를 교차엔트로피로 사용하는 경우입니다.
