1. Background
- 기존의 state of art computer vision 모델은 지도학습 기반으로, generality 와 usablility에 제약이 많음.
- label이 아닌, 자연어 캡션을 통해 학습(natural language supervision)함으로써 much broader source of supervision을 leverage할 수 있음
- "Natural language is able to express, and therefore supervise, a much wider set of visual concepts through its generality."
2. Methodology
- transformer 구조의 text encoder와 image encoder로 구성되고, text encoder가 산출한 text feature와 image encoder가 산출한 image feature 간의 cosine similarity가 높아지도록 pre-training이 이루어진다.(NCE Objective)
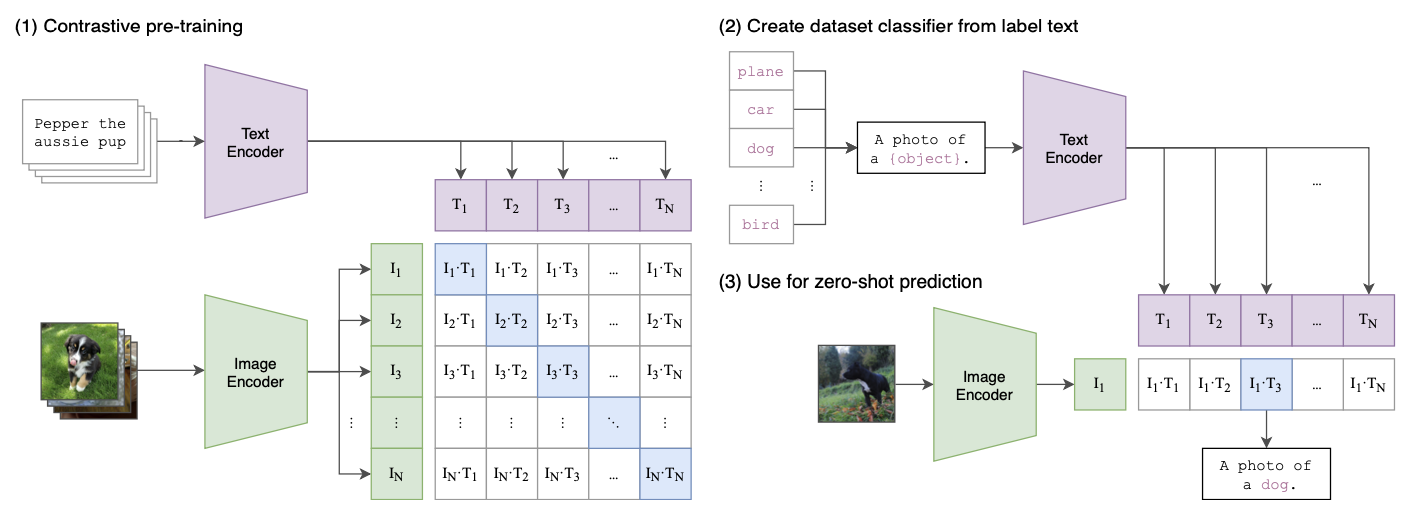
- 매우 큰 batch_size 사용(32768) ← contrastive loss 사용
- Image Encoder에 따른 model variants
- ViT기반 : ViT-B/32, ViT-B/16, ViT-L/14
- CNN기반 : RN50, RN101, RN50x4, RN50x16, RN50x64
- Web Image Text data(a.k.a WIT dataset)을 생성하여 pre-training에 사용함
이렇게 사전학습된 CLIP이라는 모델은, 이미지와 자연어에 대한 유의미한 common feature를 산출할 수 있다. 따라서, prompt engineering을 통해 zero-shot image classification이 가능하며, image classification을 기반으로 하는 다양한 task(ex.Object Detection)에 적용될 수 있다. prompt engineering에 대해서는 이어서 설명하도록 하겠다.
3. Results & Experiments
Zero shot transferability(classification)
-
Prompt Engineering
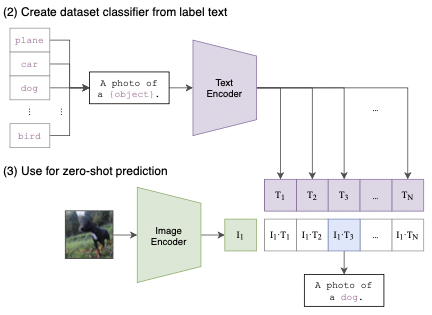 위와 같이, 특정 데이터에 대한 분류를 수행하고자 할 때 label을 text encoder에 넣어 주는 것이 아니라, prompt+label을 통해 만들어진 문장을 text encoder에 넣어 주는 것을 prompt engineering이라고 한다. CLIP text encoder는 하나의 단어가 아닌 자연어 문장으로 학습되었기 때문에, 'A photo of'와 같은 prompt를 통해 contextual information을 주는 것이 중요하다.
위와 같이, 특정 데이터에 대한 분류를 수행하고자 할 때 label을 text encoder에 넣어 주는 것이 아니라, prompt+label을 통해 만들어진 문장을 text encoder에 넣어 주는 것을 prompt engineering이라고 한다. CLIP text encoder는 하나의 단어가 아닌 자연어 문장으로 학습되었기 때문에, 'A photo of'와 같은 prompt를 통해 contextual information을 주는 것이 중요하다. 본 논문에서는, 위와 같은 방식으로 다양한 데이터셋들에 대한 zero-shot classification 성능을 측정했고, 그 결과는 아래와 같다.
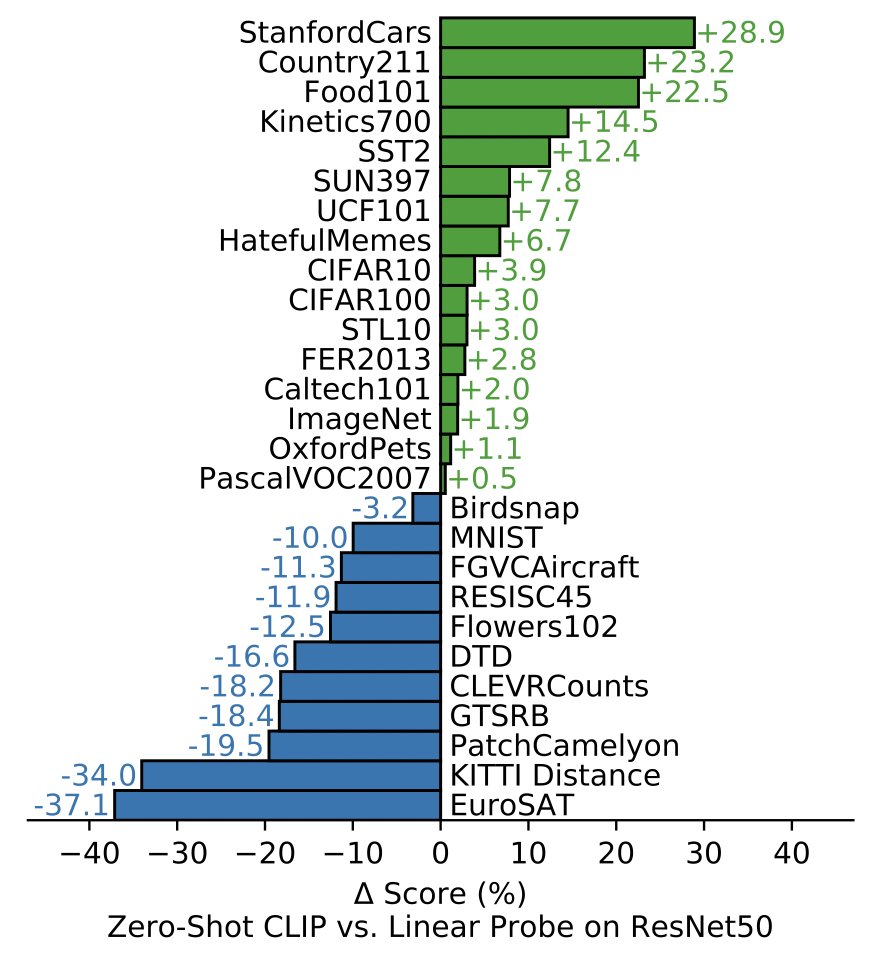
- action recognition task에서 특히 높은 성능(natural language supervision이 noun-centric(label) supervision보다 낫다)
- general한 task(Imagenet등)에서 매우 높은 성능
- satelite image classification, tumor detection, counting objects 등의 다양한 complex task에서 낮은 성능 보여줌
- tumor detection과 같은 전문적인 task는 zero-shot성능이 낮은 것이 당연할 수 있지만, counting object와 같은 task는 비 전문가인 사람도 할 수 있는 task이므로, 아직 개선의 여지는 많음
-
zero-shot vs few shot

- few shot logistic classification성능을 비교했을 때, clip zero shot performance 는 clip에 linear probe를 적용하여 4-shot learning을 수행한 결과와 비슷함
- n(n<4)shot performance가 왜 zeroshot보다 성능이 낮은가?
→ zeroshot은 natural language에 기반하여 visual concepts가 directly specified 되는 것에 반해, few shot의 경우 training example로부터 indirect하게 concept이 학습되기 때문 - zeroshot과 fewshot learning간의 discrepency를 해결하는 방법
→ zero-shot classifier를 prior of few shot classifier로 사용
Representation Learning
- representation의 품질을 측정하는 방법 → linear probe vs fine-tuning
- fine-tuning의 경우 더 나은 성능을 보장함
- linear probe의 경우, backbone이 산출한 representation에 대한 feedback이 더 용이함
- 해당 연구에서는 66개의 모델을 27개의 benchmark에 대해 evaluation
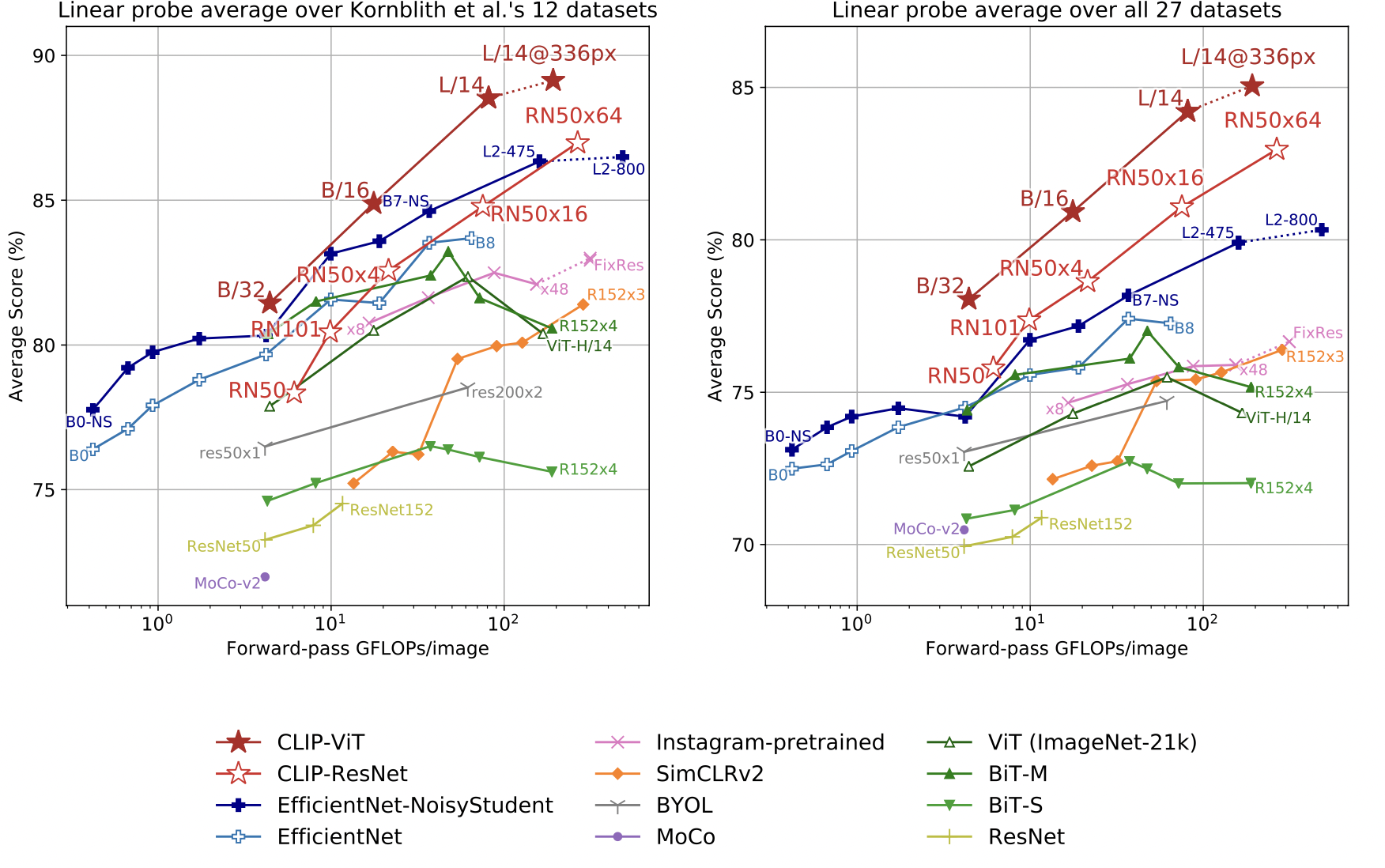
- geo-localization, OCR, facial emotion recognition, action recognition task등에 대해 evaluation
- 모든 clip varients들이 fixed computation expense를 기준으로 가장 높은 성능을 보임
- 특히, OCR관련 task / geo-localization task / scene recognition task / activity recognition task 에서 높은 성능을 보임
- Linear Probe 결과
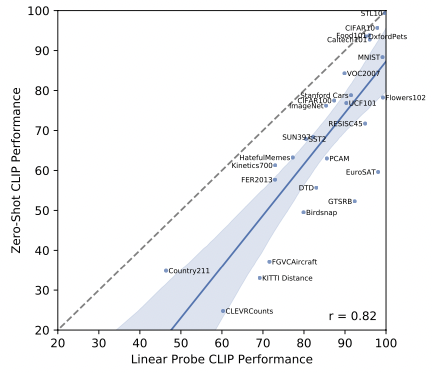
- 대부분의 데이터셋에서 linear probe를 통해 어느 정도의 성능 향상이 생김.
- 아직까지 zero-shot classification이 다소 sub-optimal하다는 것을 보여줌.
- zero-shot classification을 개선하는 것도 중요하지만, 사전학습된 CLIP을 새로운 데이터에 대해 어떻게 transfer learning 하느냐에 대한 고민도 필요함.
Robustness to natural distribution shift
-
distribution shift의 원인
: Imagenet training dataset에만 존재하는 pattern과 correlation에 지나치게 fitting 되었기 때문 -
Taori et al.(2020)
- novel image들로 구성된 7가지 데이터셋을 수집
- natural distribution shift를 가지고 있음
(imagenetv2, imagenet sketch, YouTube-bb, imagenet-vid, objectnet, imagenet adversarial, imagenet rendition)
-
CLIP의 distribution shift에 따른 성능
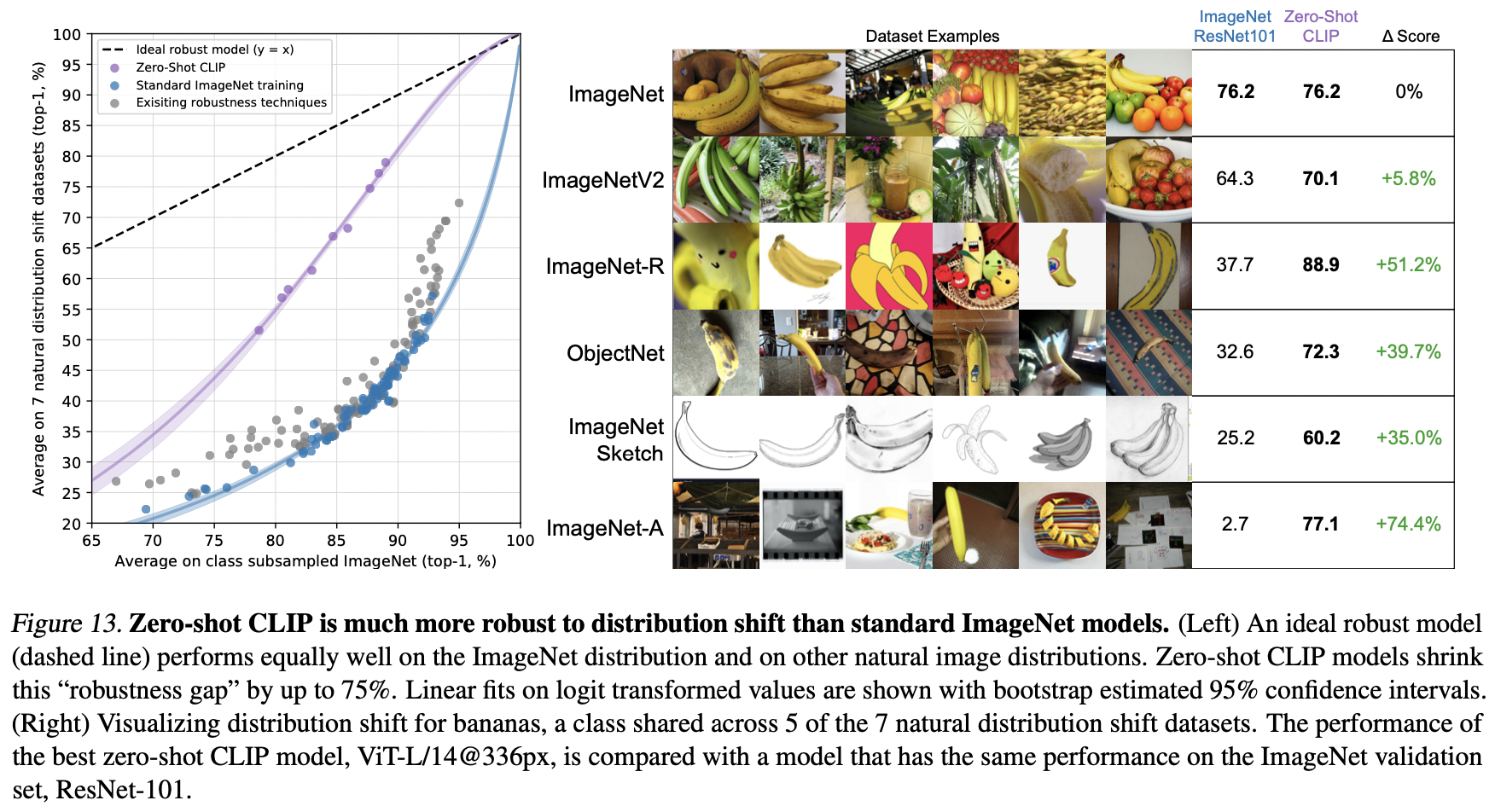
- 다른 모델들에 비해, data distribution shift에 큰 영향을 받지 않음
(ResNet101의 경우, ImageNet-A에서는 2.7%의 accuracy) - 애초에 zero shot performance가 높다는 것은 natural distribution shift에 영향을 크게 받지 않음을 의미함
- Taori et al(2020)에서 제시한 7가지 shifted dataset에 대한 bechmark결과, imagenet 기반 모델에 비해 월등하게 robust한 결과를 보여줌
- 다른 모델들에 비해, data distribution shift에 큰 영향을 받지 않음
-
zero-shot이 아닌 few-shot supervised setting으로 학습할 경우 robustness가 악화
