1. Background
CLIP은 이미지-캡션 pair로 학습되어, 이미지 전체와 문장 전체를 matching하는 역할을 한다. 하지만, zero shot object detection이나 open vocabulary object detection과 같은 방법론에서는, 이미지 전체가 아닌 이미지의 sub-region에 대한 image recognition을 필요로 한다. 하지만, CLIP은 image subregion에 대한 분류에서는 좋지 않은 성능을 보인다.
 위 figure의 (b)를 보면, CLIP을 imageNet classification에 적용하면 59.6%의 정확도를 보이지만 object detection dataset인 LVIS의 region들에 대한 classification에서는 19.1%의 정확도를 보인다. 따라서, 본 논문에서는 image region - region description 으로 CLIP을 pre train하는 방법을 제안한다.
위 figure의 (b)를 보면, CLIP을 imageNet classification에 적용하면 59.6%의 정확도를 보이지만 object detection dataset인 LVIS의 region들에 대한 classification에서는 19.1%의 정확도를 보인다. 따라서, 본 논문에서는 image region - region description 으로 CLIP을 pre train하는 방법을 제안한다.
Contributions
- manual annotation없이, image region과 description을 얻고 이들을 align 하는 방법을 제안
- (region-region decription) pair를 scalable하게 생성하는 방법 제안
- 학습된 RegionCLIP을 open vocabulary object detection에 적용하여, ViLD에 비해 성능 향상을 이룸
2. Methodology
2.1. Scalable way to generate (region-region description) pair
RegionCLIP을 학습하기 위해서는 region(image-subregion)과 region description이 매핑된 데이터가 필요하다. 하지만 아쉽게도 그런 데이터는 not available하다. 그렇다고 manual하게 annotation을 추가하는 것은 scalable한 접근 방법이 아니다. 따라서 저자는 다소 새로운 방법을 제안한다.
- Concept Pool
대량의 text corpus에 parsing을 해서, 다양한 개념이 포함된 concept pool을 만든다. concept pool은 {cat, dog, car, kite, person, ....}와 같이 다양한 개념을 포함하는 어휘들의 set 정도로 이해하면 된다.이렇게 개의 concept들로 이루어진 concept pool을 형성하고, 각 원소들에 대해 prompt engineering을 수행하여 'A photo of [concept]'의 형태로 만들어 준다. 이렇게 만들어진 개의 template을 CLIP text encoder로 인코딩하여 개의 concept embedding 으로 만들어준다.
-
Extracting image regions
두 번째 문제는, image region이 필요하다는 것이다. 이를 위해, 저자는 이미 학습되어 있는 region proposal network를 사용한다. 이미지-캡션 데이터셋의 이미지들에 대해 사전학습된 CLIP+feature pooling(RoIAlign)을 적용하여 개의 region image feature들()을 추출한다. 또한 동시에 RPN을 적용하여 개의 region image()들도 추출한다. -
Align image regions and concept
마지막 문제는, 이렇게 추출된 image region과 concept를 align해 주어야 한다는 것이다. 저자는 생각보다 직관적인 방법을 제안한다. zero-shot CLIP classification과 유사한 방식으로, 각 region image feature ()들에 대해, 가장 유사한 concept embedding ()을 찾아서 맵핑해주는 것이다.
 위에서 설명하듯 image region과 region description을 매핑해주는 척도는 cosine similarity이다.
위에서 설명하듯 image region과 region description을 매핑해주는 척도는 cosine similarity이다.
2.2. Pre-training
이제 region-region description 데이터셋도 준비되었고, image-caption데이터셋도 준비되었으므로, regionCLIP을 학습할 수 있다. 해당 저자는 세 가지 training objective를 동시에 사용하여 regionCLIP모델을 학습한다.
- Region Level Contrastive Loss
region-region description데이터가 사용 가능하므로, 이 데이터를 통해 기존의 CLIP과 같이 contrastive learning이 가능하다. region-region description 데이터로 모델을 사전학습함으로써, image region에 대해서도 유의미한 feature를 산출할 수 있도록 학습된다.
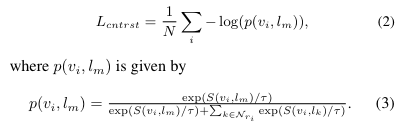
- Image Level Contrastive Loss
이 부분은 기존의 CLIP pretraining objective와 같으므로, 설명을 생략하도록 하겠다. 위 contrastive loss를 image-caption dataset에 대해 산출한다고 생각하면 된다.
- Distillation Loss
Distillation loss는 teacher model(CLIP)의 image recognition capacity를 student model(regionCLIP)에 distill 하기 위한 목적을 가진다.
어떤 이미지 가 주어졌을 때, 이 이미지에 대해 teacher model(CLIP)이 산출하는 개의 concept pool에 대한 probability distribution을 라 하고, student model(regionCLIP)이 산출하는 개의 concept pool에 대한 probability distribution을 라 하자. Distillation loss는 두 이산 확률분포 간의 KL-Divergence로 이루어진다.
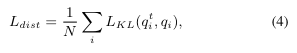 에 대한 정의 :
에 대한 정의 :
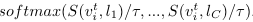 에 대한 정의 :
에 대한 정의 :
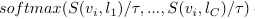
2.3. Applying to (Open Vocabulary) Object detection
이렇게 학습된 regionCLIP을 ViLD와 같은 open vocabulary object detection에 적용하여 open vocabulary object detection을 수행할 수 있다. 이 논문에서는, object detection을 위주로 실험을 진행하는데, 다음 섹션에서 살펴보도록 하겠다.
3. Experiment
Datasets
- Pre-training : Conceptual Captions(CC3M) or CoCo dataset
- Transfer Learning for Open Vocabulary object detection : LVIS dataset or Coco detection dataset
Implementational Details
- Pre-training
- student model과 teacher model모두 pretrained CLIP(ResNet50기반)
- pretrained RPN의 경우, LVIS의 base class 데이터를 통해 학습됨
- batch size = 96
- default model의 경우, CC3M데이터셋 + Coco caption으로부터 추출된 concept pool로 학습됨
- Transfer learning for OVOD(open vocabulary object detection)
- Faster-RCNN(ResNet50-C4 as backbone)을 사용
- batch size = 16
- weight of background category = 0.2/0.8 for Coco/LVIS
- Focal scaling applied with
3.1. Open Vocabulary Object Detection
- Result on CoCo object detection dataset
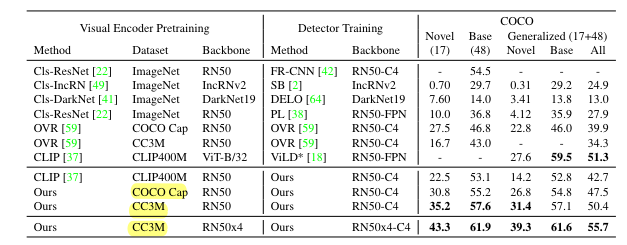
- pretrained RegionCLIP으로 학습된 모델의 경우, OVR에 비해 novel class에 대한 AP가 월등히 높음
- pretrained CLIP을 leverage한 ViLD와 비교했을 때에도, Novel class에 대한 AP가 22.5 -> 30.8로 크게 상승함
- Result on LVIS object detection dataset
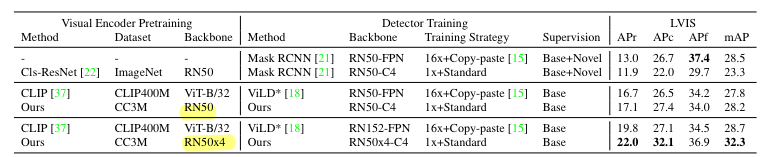
- 비슷한 수용력을 가지는 detector backbone을 기준으로 ViLD와 regionCLIP을 비교했을 때, 공통적으로 성능 향상이 이루어짐
- regionCLIP이 image region과 concept간의 alignment를 더 잘 학습한다는 것을 알 수 있음
3.2. Ablation Study
ablation에서는 regionCLIP의 여러 구성요소들의 변화에 따른 Coco detection dataset에서의 open vocabulary object detection 및 zero shot detection성능의 차이를 살펴본다.
1. Pretraining supervision
첫번째로 살펴볼 내용은, pretraining과정에서 image-text pair 데이터를 포함시키는지의 여부이다. 해당 여부에 따른 성능은 아래와 같다.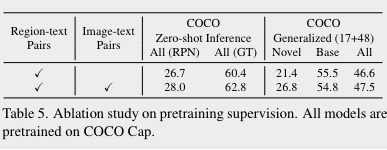 image-text pair이 pretraining에 사용된 경우 성능이 더 좋다. 특히, open vocabulary object detection에서 novel class에 대한 성능 향상 폭이 상당히 크다. 본 논문에서는 image-text pair가 contextual information을 학습하는 데 도움을 주었을 것이라고 이야기한다.
image-text pair이 pretraining에 사용된 경우 성능이 더 좋다. 특히, open vocabulary object detection에서 novel class에 대한 성능 향상 폭이 상당히 크다. 본 논문에서는 image-text pair가 contextual information을 학습하는 데 도움을 주었을 것이라고 이야기한다.
2. Types of image regions
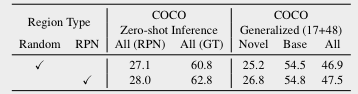
두번째로 살펴볼 내용은 image region-region description 데이터셋을 만들 때, image region을 어떻게 추출할 것인가에 대한 것이다. default모델은 사전학습된 RPN을 통해 image region과 region feature를 뽑아냈다. 하지만, 이렇게 하지 않고 그냥 random crop을 통해 region을 뽑아낼 수도 있다. 그리고 예상 외로 random crop을 통해 얻은 region으로 데이터셋을 구성하여 pretraining을 해도, 최종 성능이 나쁘지 않다. 본 논문에서는, regionCLIP이 그만큼 robust한 region represnetaion을 학습할 수 있기 때문이라고 이야기한다.
3. Pretraining dataset & concept pool
세번째로, pre-training에 사용된 데이터셋과 concept pool을 구성하는 데 사용된 데이터셋에 따라 최종 성능이 어떻게 변화하는지 살펴본다.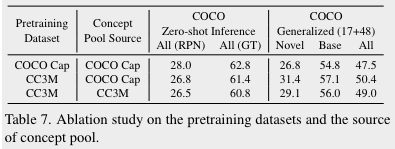 CC3M은 매우 큰 규모의 데이터셋이고, Coco는 100,000여 개의 샘플들로 구성된 비교적 작은 규모의 데이터셋이다. 하지만, zero-shot object detection의 경우 Coco data로 pre training한 결과가 가장 우수하다. 하지만 이는 test dataset이 coco detection dataset이기 때문인 것으로 보인다. zero-shot이 아닌 open vocabulary object detection결과를 보면, pretraining에는 CC3M 데이터셋을 / concept pool에는 coco caption을 사용한 모델의 결과가 가장 우수하다. 이는 모델이 큰 규모의 데이터셋을 통해 더욱 generic한 visual representation을 학습했기 때문이라고 볼 수 있다.
CC3M은 매우 큰 규모의 데이터셋이고, Coco는 100,000여 개의 샘플들로 구성된 비교적 작은 규모의 데이터셋이다. 하지만, zero-shot object detection의 경우 Coco data로 pre training한 결과가 가장 우수하다. 하지만 이는 test dataset이 coco detection dataset이기 때문인 것으로 보인다. zero-shot이 아닌 open vocabulary object detection결과를 보면, pretraining에는 CC3M 데이터셋을 / concept pool에는 coco caption을 사용한 모델의 결과가 가장 우수하다. 이는 모델이 큰 규모의 데이터셋을 통해 더욱 generic한 visual representation을 학습했기 때문이라고 볼 수 있다.
4. Pretraining losses
다음으로 볼 것은 pretraining에 사용되는 손실 함수이다. pretraining과정에서는 contrastive loss와 distillation loss가 동시에 사용된다.
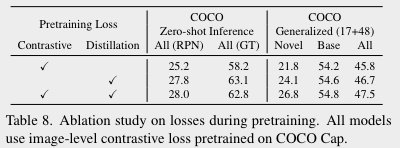 이 결과를 통해 distillation loss는 teacher model인 CLIP의 visual-semantic knowledge를 inherit하는 역할을 하고, contrastive loss는 transfer learning을 위한 더 discriminative한 feature를 학습하는 역할을 한다고 추정해볼 수 있다.
이 결과를 통해 distillation loss는 teacher model인 CLIP의 visual-semantic knowledge를 inherit하는 역할을 하고, contrastive loss는 transfer learning을 위한 더 discriminative한 feature를 학습하는 역할을 한다고 추정해볼 수 있다.
5. Teacher model & Student Model
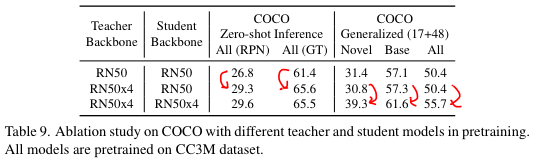
다섯 번째로 볼 것은, teacher model과 student model의 모델 구조에 따라 성능이 어떻게 변화하는가에 대한 것이다.
우선 zero shot object detection의 경우, teacher model을 개선시킬 때 최종 성능이 많이 개선된다. 하지만 student model의 개선은 그다지 큰 성능 향상에 기여하지 못한다.
반면 transfer learning이 가능한 open vocabulary object detection의 경우, teacher model의 개선은 최종 성능에 큰 영향을 주지 않으나 student model을 개선할 경우, 최종성능이 큰 폭으로 향상된다.
zero-shot inference는 teacher model에 영향을 많이 받고, transfer learning의 경우 student model의 capacity에 영향을 크게 받는다는 것을 추정해볼 수 있다.
6. Focal Scaling
본 논문에서는 open vocabulary object detection을 위해, coco detection이나 LVIS와 같은 객체 탐지 데이터셋의 base class로 transfer learning을 수행한다. 이때 base class들에 대한 overfitting을 막기 위한 목적으로, transfer learning에서 cross entropy loss를 적용할 때 focal scaling을 적용한다. 
- focal loss : https://gaussian37.github.io/dl-concept-focal_loss/
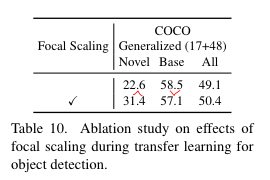
위 table을 확인해보면, focal scaling을 적용하지 않았을 때 base class에 대한 overfitting이 발생함을 확인할 수 있다.
