Vision-Language Multimodal
1.[논문 리뷰] CLIP(2021)
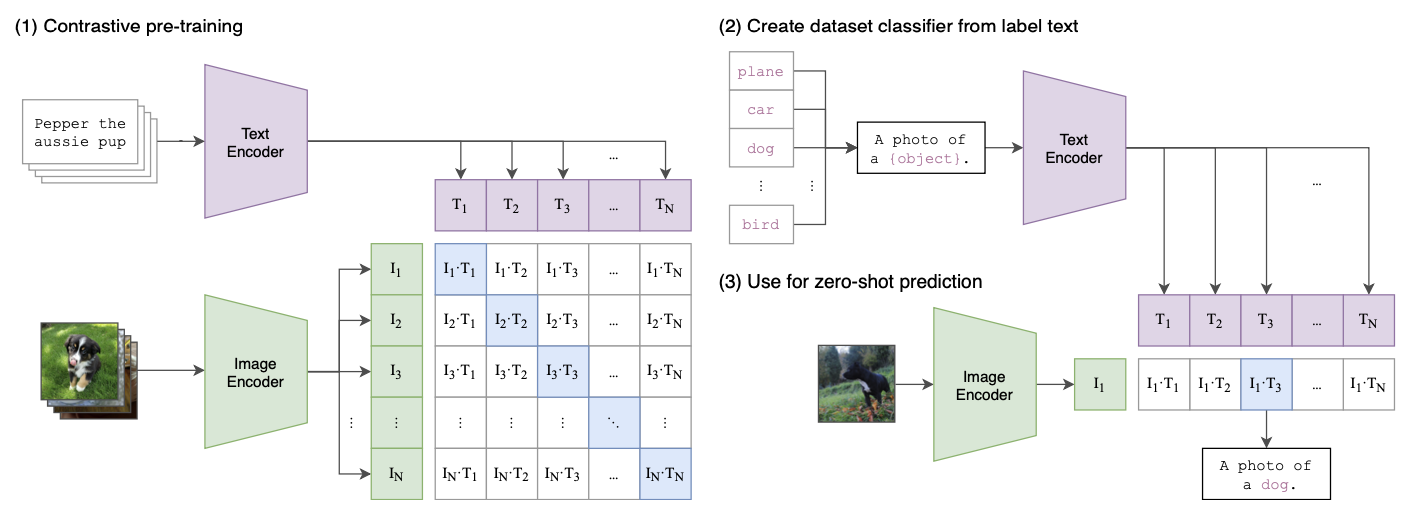
image encoder과 text encoder를 사용하여 representation 산출 후, multimodal space에 projection → NCE loss를 사용하여 paired image-text간의 mutual information을 최대화함(CLIP
2.[논문리뷰]RegionCLIP: Region-based Language-Image Pretraining(2021)

CLIP은 이미지-캡션 pair로 학습되어, 이미지 전체와 문장 전체를 matching하는 역할을 한다. 하지만, open vocabulary object detection과 같은 방법론에서는, 이미지 전체가 아닌 이미지의 sub-region에 대한 image rec
3.[논문리뷰]Unified-IO(2022)
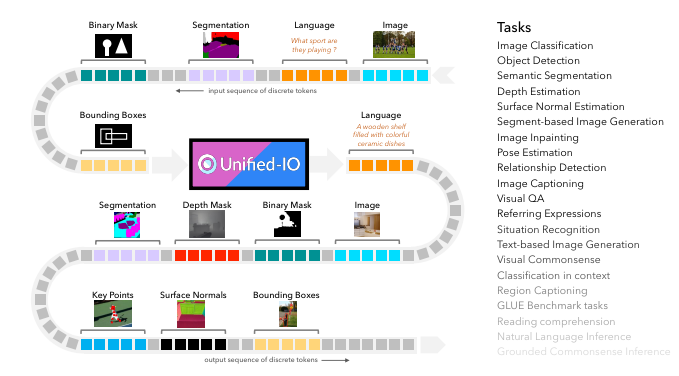
오늘 소개할 논문은 Unified-IO입니다. 최근 computer vision이나 vision language task를 수행하는 모델들은, pretrained backbone에 task-specific module(parameter)를 추가하여 fine-tuning
4.[논문리뷰]DenseCLIP(2021)

요즘 관심을 가지고 있는 분야는, 거대한 규모로 사전학습된(오픈소스로 공개된) vision-language foundation모델(ex. CLIP, ALIGN)을 사용하여 최소한의 튜닝으로 다양한 downstream에 적용하는 것입니다.natural language s
5.[논문리뷰]OV-DETR : Open vocabulary DETR with Conditional Matching(2022)
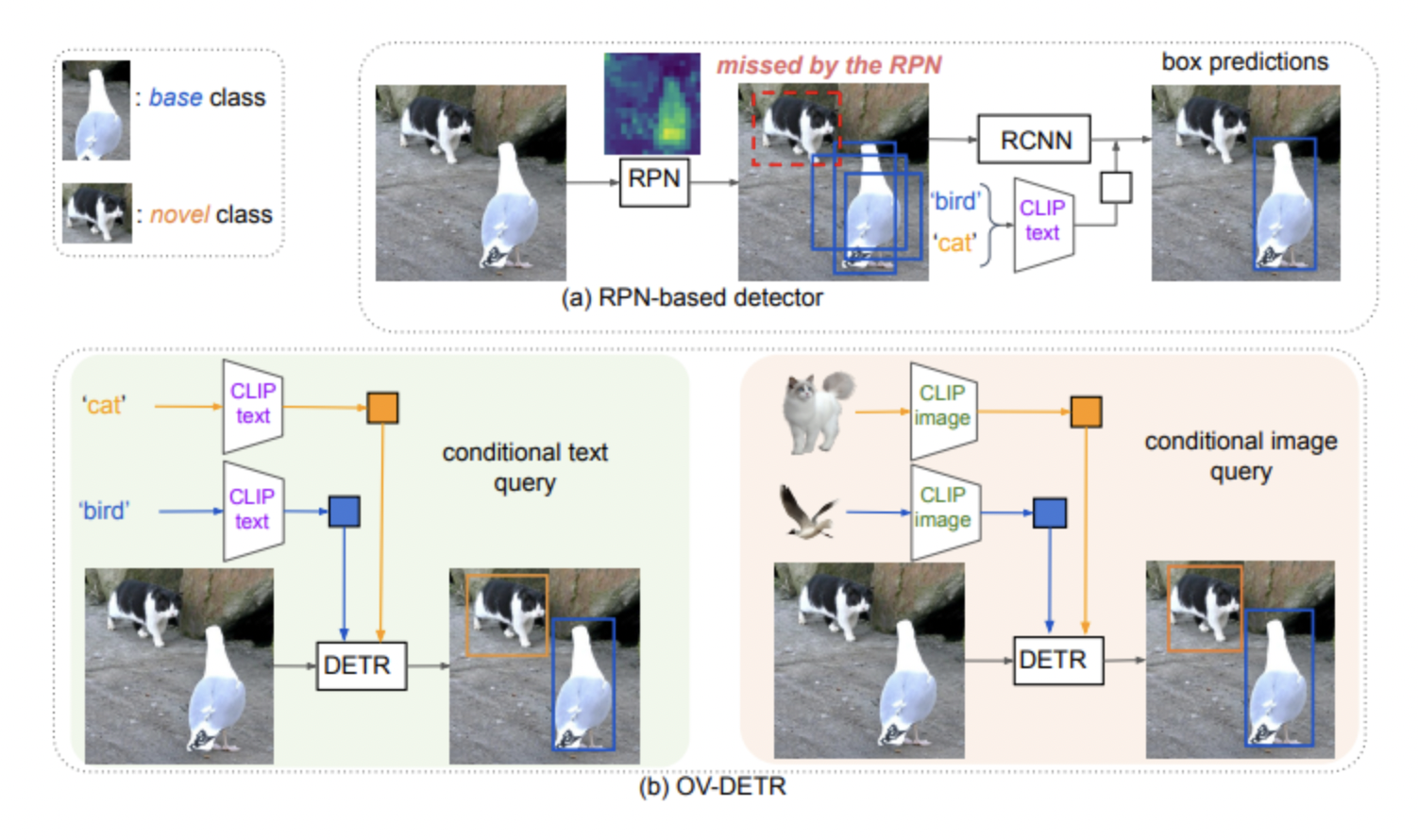
논문 제목 : Open-Vocabulary DETR with Conditional Matching 본 논문에서는, RPN을 통한 Object proposal과 VL-foundation model을 통한 open vocabulary classfication의 결합으로
6.Video Representation Learning
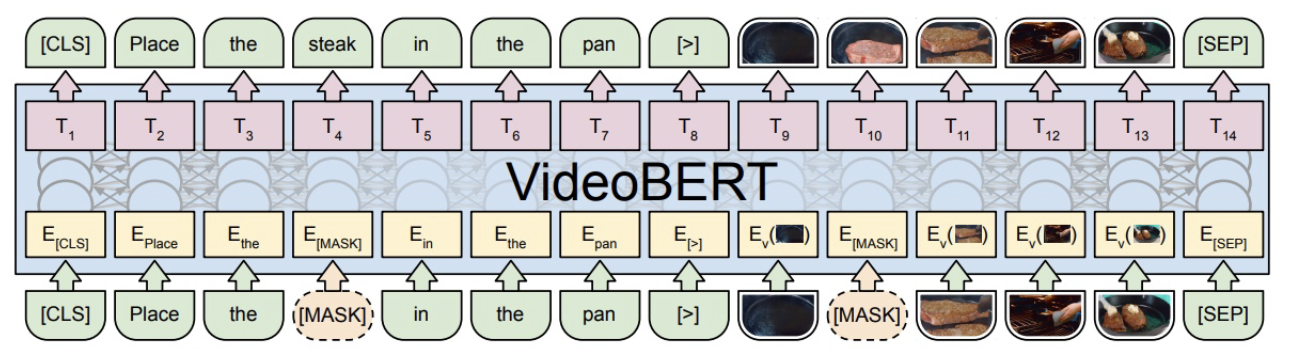
HowTo100M dataset은 유튜브 영상으로부터 수집된 거대한 규모의 비디오 데이터셋이다. 추상적인 주제의 영상이 아닌, 물리적인 행동과 행동에 대한 음성 묘사가 존재하는 instructional video들로 구성되어 있다. MSR-VTT처럼 수작업으로 vid