HowTo100M dataset
HowTo100M dataset은 유튜브 영상으로부터 수집된 거대한 규모의 비디오 데이터셋이다. 추상적인 주제의 영상이 아닌, 물리적인 행동과 행동에 대한 음성 묘사가 존재하는 instructional video들로 구성되어 있다.
MSR-VTT처럼 수작업으로 video clip-caption이 큐레이션 된 것이 아닌, 유튜브의 automatic speech recognition 시스템을 사용한 narrated video dataset이다. 따라서 규모가 기타 비디오 데이터셋에 비해 훨씬 크다(약 1억 개의 video clip-sentence pair).
https://paperswithcode.com/dataset/howto100m
이러한 형태의 narrated video dataset은 데이터의 스케일을 매우 큰 규모로 키우는 게 가능하다. 하지만 사람이 직접 curating한 데이터가 아니기 때문에 상당히 noisy하다는 단점이 있다. 따라서, 이러한 거대한 규모의 narrated video dataset을 사용하여 유의미한 video representation을 학습하고, 다양한 시각 관련 downstream task에 적용하는 연구가 활발히 이어지고 있다.
따라서 본 포스팅에서는 narrated video dataset을 활용한 Video representation learning 연구들 몇 가지에 대해 다루어 보고자 한다.
VideoBERT(2019)
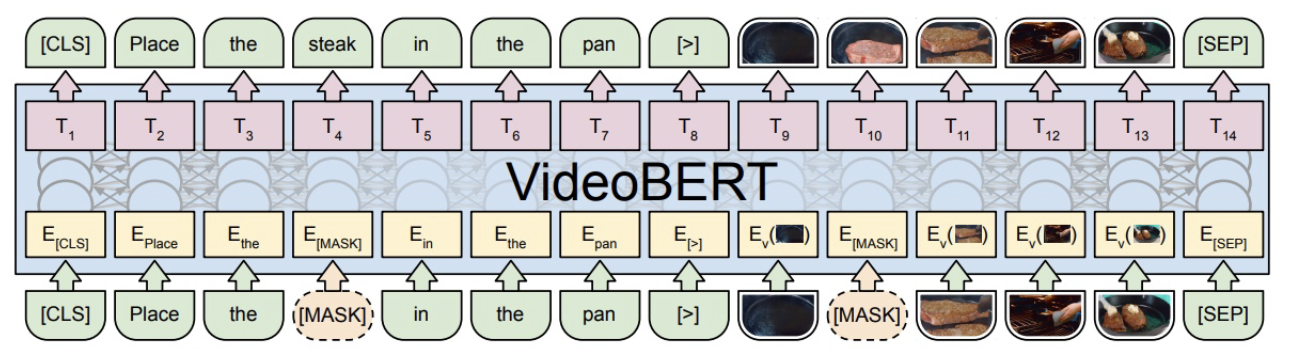 VideoBERT는 BERT와 마찬가지로, Masked Language Modeling objective와 비슷한 종류의 objective를 제안한다. S3D라는 3D convolution network backbone으로 일정 개수의 frame들의 묶음을 visual token으로 discretize(이산화)한 뒤, 이 visual token들에 대해 MLM을 적용하여 bi-directional video encoder를 학습하는 것이 핵심 아이디어이다.
VideoBERT는 BERT와 마찬가지로, Masked Language Modeling objective와 비슷한 종류의 objective를 제안한다. S3D라는 3D convolution network backbone으로 일정 개수의 frame들의 묶음을 visual token으로 discretize(이산화)한 뒤, 이 visual token들에 대해 MLM을 적용하여 bi-directional video encoder를 학습하는 것이 핵심 아이디어이다.
결국 비디오는 프레임들의 순차열이고, 언어는 토큰(단어)들의 순차열이기 때문에 위와 같은 방식의 학습이 가능하다. 또한, 연속적인 값들로 이루어진 비디오 프레임을 토큰화했기 때문에 MLM과 같은 loss function을 사용할 수 있다.
MIL-NCE(2019)
HowTo100M과 같은 narrated video dataset은 규모가 크다는 장점이 있지만, 데이터 자체가 noisy하다는 단점이 있다. Noise는 두 가지 종류가 있다.
- ASR을 통해 음성을 text로 변환하는 과정에서 발생하는 노이즈
- Video clip과 ASR을 통해 추출된 text간의 temporal mis-alignment
해당 논문에서 해결하고자 하는 noise는 후자이다. 즉, 비디오를 보면 음성 묘사가 시각적인 행위에 앞서는 경우도 있고 음성 묘사가 시각적인 행위 이후에 등장하는 경우도 있다. 아니면 특정 시각적인 행위를 묘사하는 음성 묘사가 없을 수도 있고, 발화자가 의미 없는(시각적인 행위와 관련 없는) 말을 하는 경우도 있다.
해당 논문에서는 mis-alignment문제를 해결하기 위해서 일반적인 contrastive learning을 위한 infoNCE 손실함수의 변형된 버젼(Multiple Instance Learning NCE)을 제안한다.
video clip과 text pair의 순차열이 있다고 해 보자. 데이터에 존재하는 mis-alignment때문에, step 의 video-clip과 연관된 text description이 무조건 step 의 text라는 법이 없다. step에 상응하는 text중에 정답이 있을 가능성이 있다. 따라서 해당 논문에서 제안하는 loss function은 아래와 같다.
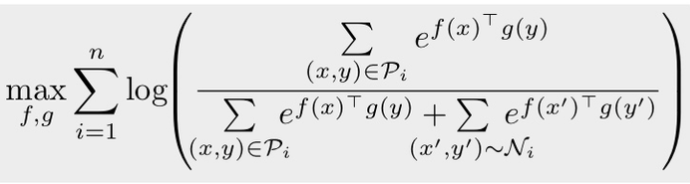 는 video clip, 는 text description을 의미하고, 는 positive set을 의미하고, 어떤 video clip 가 주어졌을 때,
는 video clip, 는 text description을 의미하고, 는 positive set을 의미하고, 어떤 video clip 가 주어졌을 때,
라고 표현할 수 있다. 이 때 는 hyperparameter이다. 해당 방법론을 적용한 결과, 기존의 SOTA모델들에 비해 downstream benchmark성능이 큰 폭으로 개선되었다.
UniVL(2020)
MerLot(2021)
