[논문리뷰]OV-DETR : Open vocabulary DETR with Conditional Matching(2022)
Vision-Language Multimodal
논문 제목 : Open-Vocabulary DETR with Conditional Matching
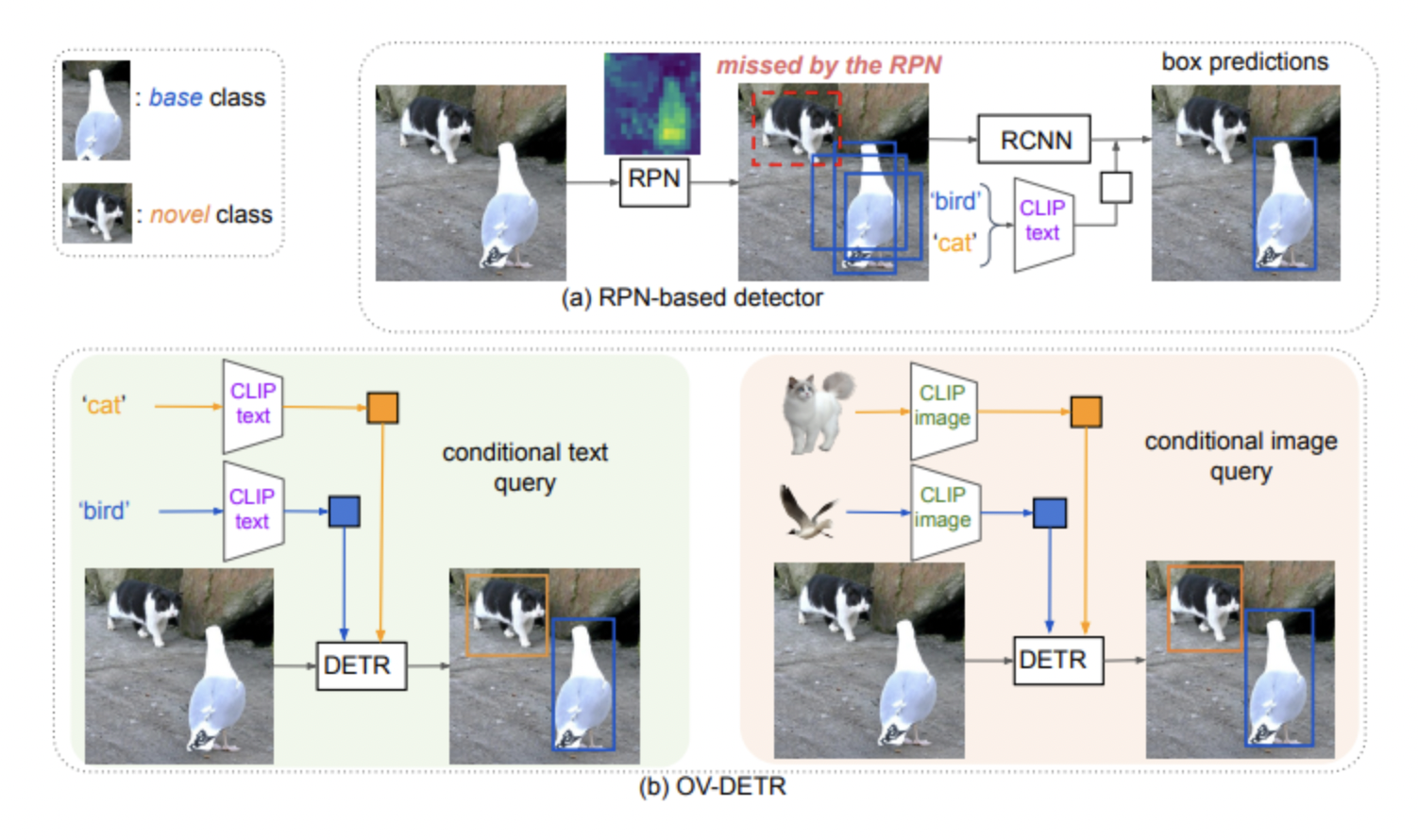
본 논문에서는, RPN을 통한 Object proposal과 VL-foundation model을 통한 open vocabulary classfication의 결합으로 이루어지는 open vocabulary object detection(ex. ViLD)와는 다른 방식의 프레임워크를 제안합니다. End to End 방식의 object detection algorithm인 DETR와 CLIP에 기반하여 open vocabulary object detection이 가능한 OV-DETR이라는 모델을 소개합니다.
본 방법론을 소개하기 앞서, 간략하게 DETR에 대해 설명해 보겠습니다.
DETR
: input image
: learnable object queries
: predictions of bounding boxes
: ground truth annotation
: CNN+transformer image encoder
: transformer decoder
DETR의 학습과정은 두 단계로 이루어집니다.
1. Set prediction
첫 번째 단계는, forward propagation을 통해서 이미지가 주어졌을 때 set of bounding box(N개)를 예측하는 것입니다.
2. Bipartite matching for Loss Computation
하지만, N개의 예측된 bounding box와 K개의 ground truth bounding box간의 매칭이 존재하지 않는다면, 손실함수를 계산하는 것 자체가 불가능해집니다. 따라서, Hungarian Loss를 기준으로 Bipartite matching을 수행 한 뒤, 손실 함수가 계산됩니다.
이 식에서 첫 번째 항은 object label에 대한 cross entropy loss이고, 두 번째와 세 번째 항은 object bounding box에 대한 손실 함수입니다.
하지만, open vocabulary object detection의 셋팅에서 위와 같은 방식으로 학습을 하게 되면 novel class에 대한 object detection이 이루어질 수 없습니다. 따라서, 본 논문에서는 DETR를 통해 Open vocabulary object detection을 수행하기 위하여, conditional matching이라는 방식을 제안합니다.
Conditional Matching for Open-Vocabulary Detection
기존의 object detection은, 이미지가 주어지면 이미지에 존재하는 모든 object를 localize하고 label을 할당하는 방식이었습니다. 반면, 이 방식은 조금 다릅니다.
Inference의 측면
탐지하고자 하는 label이 {cat, dog, car}이라고 하겠습니다. cat이라는 label을 넣어 주면, 이 모델은 이미지에서 고양이를 localize합니다. 그리고 dog를 넣어주면, 이 모델은 이미지에서 개를 localize합니다. 만약 이미지에 개가 없다면 아무것도 localize하지 않을 수도 있겠죠. 이러한 방식으로, 모든 class들에 대해 forward propagation을 진행하게 되면, 한 이미지에 대한 Object detection결과를 반환받을 수 있습니다.
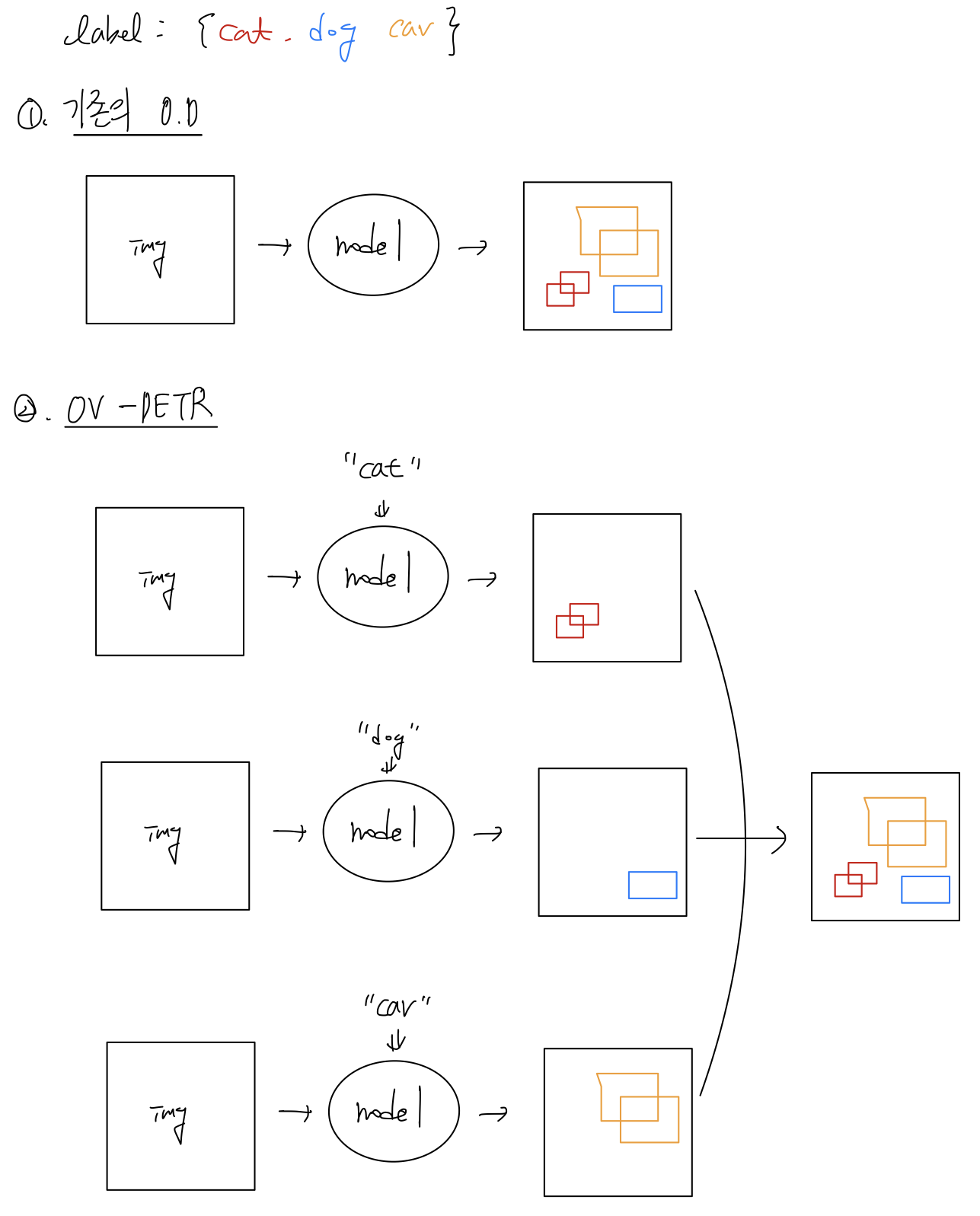
모든 class에 대해 forward propagation을 해야 하기 때문에 추론 속도가 매우 느리다는 치명적인 단점이 있지만, DETR이라는 one-stage object detection model로 open vocabulary object detection에 성공했다는 점에서 의미가 있다고 생각합니다.
Training의 측면
OV-DETR은 특정 label에 조건화 된 bounding box를 예측하는 것을 목적으로 하며, 학습 과정에서 보지 못한 label에 대해서도 bounding box를 예측할 수 있어야 합니다.
Conditional Input
따라서 학습 과정에서는 ground truth label과 ground truth bounding box에 대한 CLIP embedding을 뽑아 주고, 이것을 object query에 적용합니다.
: image
: bounding box of the image
: label of bounding box
라고 하면, 아래와 같이 ground truth annotation에 대한 CLIP embedding을 표기할 수 있습니다.
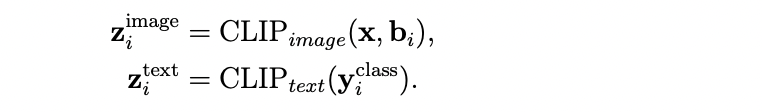
그 다음, DETR decoder의 input인 learnable object queries 들을 혹은 에 대해 조건화하기 위하여 아래와 같은 연산을 수행합니다.
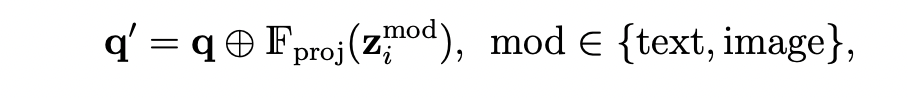
이렇게 정의된 는 class-specific object query가 됩니다.(는 class-agnostic query).
결국 모델은 input image 와 class-specific object query인 를 인풋으로 받고, 해당 class에 상응하는 N개의 set of bounding box를 산출합니다.
Conditional Matching
이렇게 산출된 N개의 bounding box와, input class에 상응하는 groud truth box간의 bipartite matching을 수행한 후, DETR과 비슷한 형식의 loss를 산출하게 됩니다.
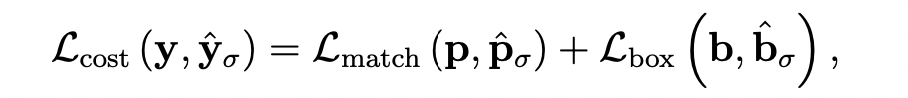 두 번째 항인 는 DETR과 마찬가지로 로 이루어집니다. 달라지는 부분은 (bounding box의 분류 라벨에 대한 cross entropy loss) 대신, 를 사용한다는 것입니다.
두 번째 항인 는 DETR과 마찬가지로 로 이루어집니다. 달라지는 부분은 (bounding box의 분류 라벨에 대한 cross entropy loss) 대신, 를 사용한다는 것입니다.
논문에는 에 대한 수식이 생략되어 있습니다.
조금 자세히 설명하자면, 특정 label 에 대해 조건화된 bounding box prediction이 이고, 이 prediction과 bipartite matching을 통해 매칭된 ground truth bounding box가 라고 하겠습니다. 그리고, 에 상응하는 groudn truth label을 라고 하겠습니다.
이 때, 에 상응하는 ground truth label이 과 같으면, matching(1), 가 아니라면 unmatching(0)으로 binary matching loss를 산출하는 것입니다.
수식으로 표현하자면, single image 와 conditioned label 에 대한 binary matching loss는 아래와 같이 표현할 수 있습니다.(부정확할 수도 있습니다..)
, where is matched pair of prediction & ground truth, is unmatched pair of prediction & ground truth.
Qualitative Results & Limitations
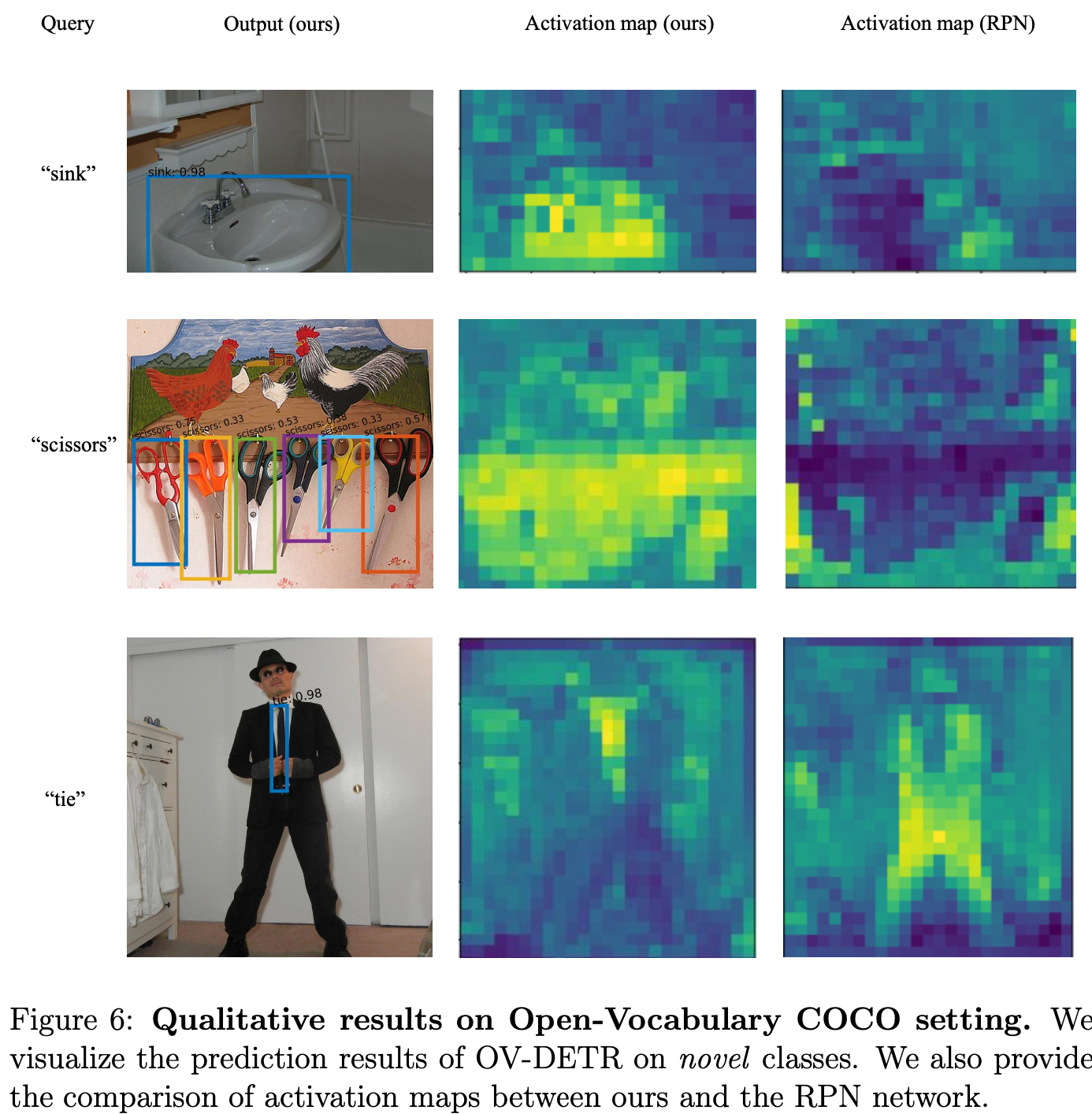
RPN 기반 open vocabulary object detection과 비교했을 때, attention map을 통해 알 수 있듯이 RPN이 잘 detect하지 못하는 novel object에 대해 OV-DETR은 잘 탐지 해냅니다.
하지만 몇 가지 한계점이 있습니다.
먼저, 앞서 언급했듯이 visual grounding과 유사한 방식으로 작동하기 때문에, 모든 label set에 대한 object detection을 수행하려면, 계산 시간이 오래 걸립니다.
두 번째로, image가 query로 주어질 경우에 occluded(가려지거나) or small object에 대해서는 잘 탐지하지 못합니다. 또한, 이미지에 존재하지 않는 text query를 제시해도 특정 사물이 탐지되는 현상이 발생한다고 합니다.

