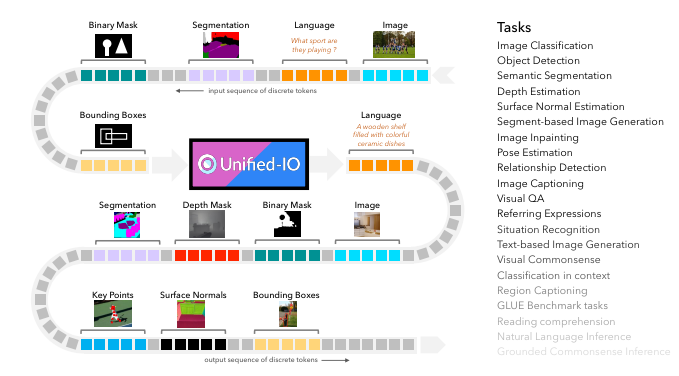
오늘 소개할 논문은 Unified-IO입니다. 최근 computer vision이나 vision language task를 수행하는 모델들은, pretrained backbone에 task-specific module(parameter)를 추가하여 fine-tuning 되는 형태로 사용됩니다. 즉, task마다 요구하는 output representation이 모두 다르기 때문에(object detection은 bounding box coordinate / segmentation은 score map / depth estimation은 depth map....), 하나의 unified model로는 다양한 computer vision task를 한번에 수행할 수는 없던 것이죠.
하지만 NLP 분야는 조금 다릅니다. NLP분야의 input과 output은 sequence로 표현이 가능합니다. 그렇기에, 추가적인 학습 없이도 pretrained GPT-3와 같은 unified model로 매우 다양한 NLP task를 수행할 수 있습니다.
본 논문에서는 computer vision, Vision-Language , NLP에 속하는 매우 다양한 task를 추가학습 없이 수행할 수 있는 Unified-IO라는 모델을 제안합니다.
How to represent Input&Output?
Unified IO가 수행할 수 있는 task는 아래와 같습니다.
- Computer Vision tasks : image classification / object detection / semantic segmentation / depth estimation / surface normal / joint estimation / image inpaininting
- Vision-Language tasks : visual quenstion answering / text to image generation / image captioning / region captioning ....
- NLP tasks : referring expression comprehension / NLI, Commonsense reasining ...
위에서 언급한 것 외에도, 매우 다양한 task를 수행할 수 있습니다. 이를 unified model로 수행하기 위해 필요한 것은, input output의 data representation을 모든 task들에 대해 통일하는 것입니다.
본 연구에서는, input과 output을 모두 sequence of token으로 표현하는 방법을 제안합니다. 즉, 위에서 제시한 모든 task들을 sequence to sequence problem으로 재정의한 것입니다.
Natural language나 bounding box coordinate가 아닌 RGB image나 depth map과 같은 dense data를 어떻게 sequence of token으로 표현할 수 있을까요? 본 논문에서는 pretrained VQ-VAE를 사용하여, 이미지를 sequence of token으로 표현하는 방법을 제안합니다.
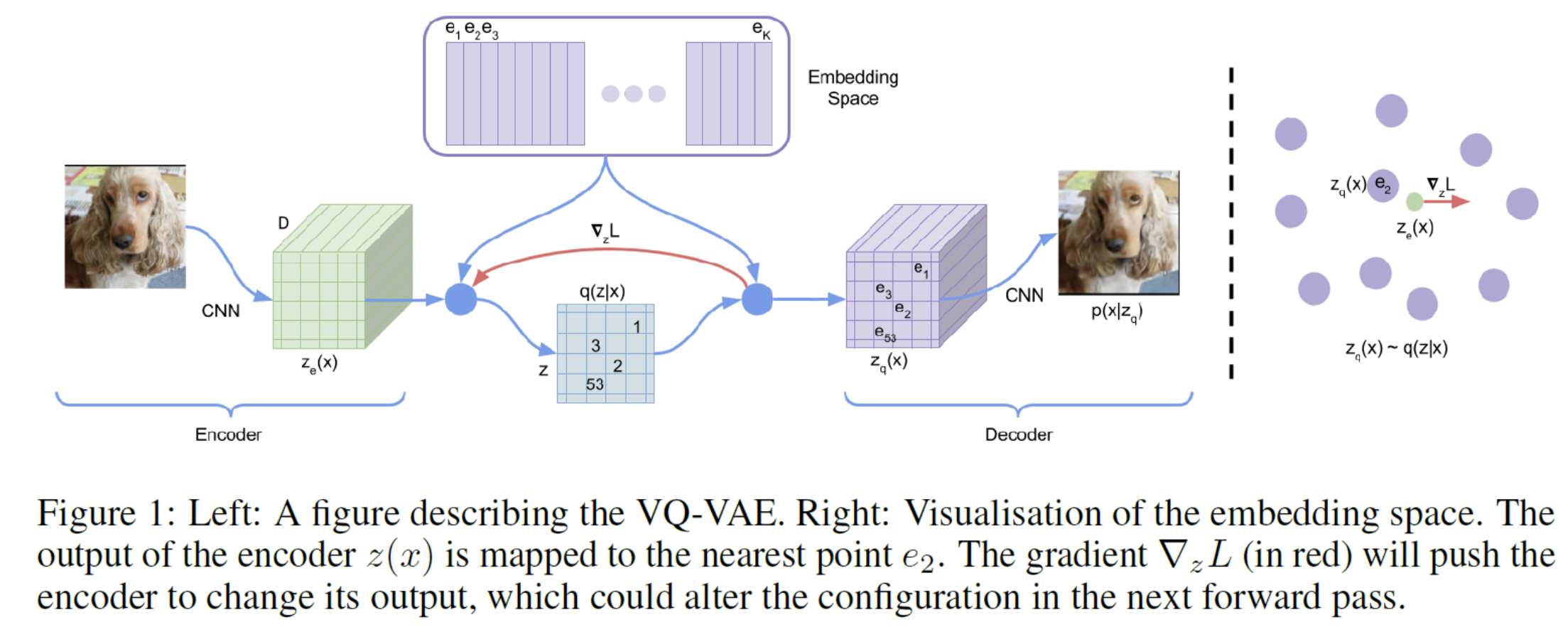 VQ-VAE는, 이미지를 discrete token sequence로 encoding 후 다시 원래의 이미지로 decoding하는 방식을 통해 학습된 모델로, RGB image를 sequence of token으로 변환시키는 데에 사용됩니다.
VQ-VAE는, 이미지를 discrete token sequence로 encoding 후 다시 원래의 이미지로 decoding하는 방식을 통해 학습된 모델로, RGB image를 sequence of token으로 변환시키는 데에 사용됩니다.
output이 image인 경우(image inpaininting, image generation)에는 VQ-VAE의 decoder를 fidelity측면에서 개선시킨 VQ-GAN을 사용하여, sequence of token을 바탕으로 이미지를 생성합니다.
참고로, segmentation map의 경우엔 엄밀히 말하면 rgb image가 아닙니다. 채널 수가 #class 인 score map이죠. 하지만, 이 score map을 시각화하면, 인간은 이것을 rgb image로 인식합니다.
 따라서, segmentation dataset으로 모델을 학습시킬 때에는, score map을 rgb image로 처리한 뒤 이를 sequence of token으로 변환하여 학습에 사용합니다.
따라서, segmentation dataset으로 모델을 학습시킬 때에는, score map을 rgb image로 처리한 뒤 이를 sequence of token으로 변환하여 학습에 사용합니다.
How to Train?
1. Pre-Training
- Text span denoising : 랜덤하게 15%의 token들을 masking -> MLM objective
- Masked Image denoising : 랜덤하게 75%의 image token들을 masking -> MIM(masked image modeling) objective
2. Multi-Task Learning
- 80개의 task specific dataset들로 학습
- 하나의 batch에 여러 task의 dataset들을 포함시킴(For each task category, we sample tasks with a temperature-scaled mixing strategy to make sure the model is sufficiently exposed to under-represented tasks)
위와 같은 방식으로 Unified-IO에 대한 학습이 이루어지며, 상세한 demo는 아래 링크에서 확인하실 수 있습니다.
