
Try1

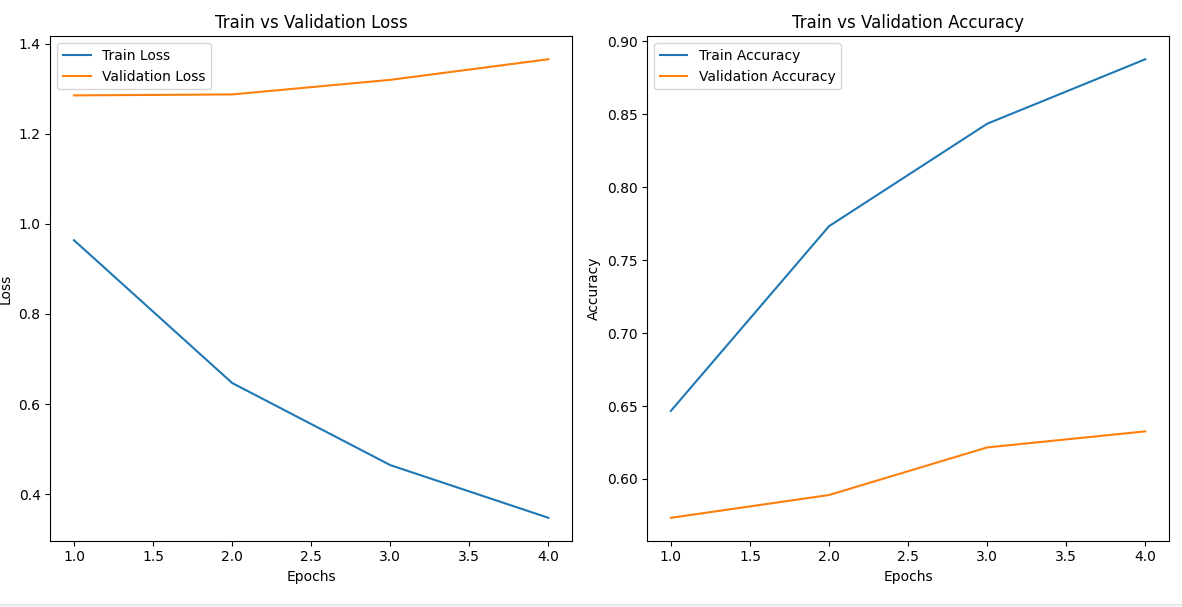
[테스트 데이터]
Test Loss: 1.2816, Test Accuracy: 0.5654과적합을 방지하려고 데이터 증강과 Waight Sampler를 사용했지만, 아쉽게도 과적합이 발생함
Try2 EfficientNetB0으로 변경
EfficientNetB7은 소규모(2만개 정도)데이터 셋에 적합하지 않다고 판단하여 EfficientNetB0으로 변경

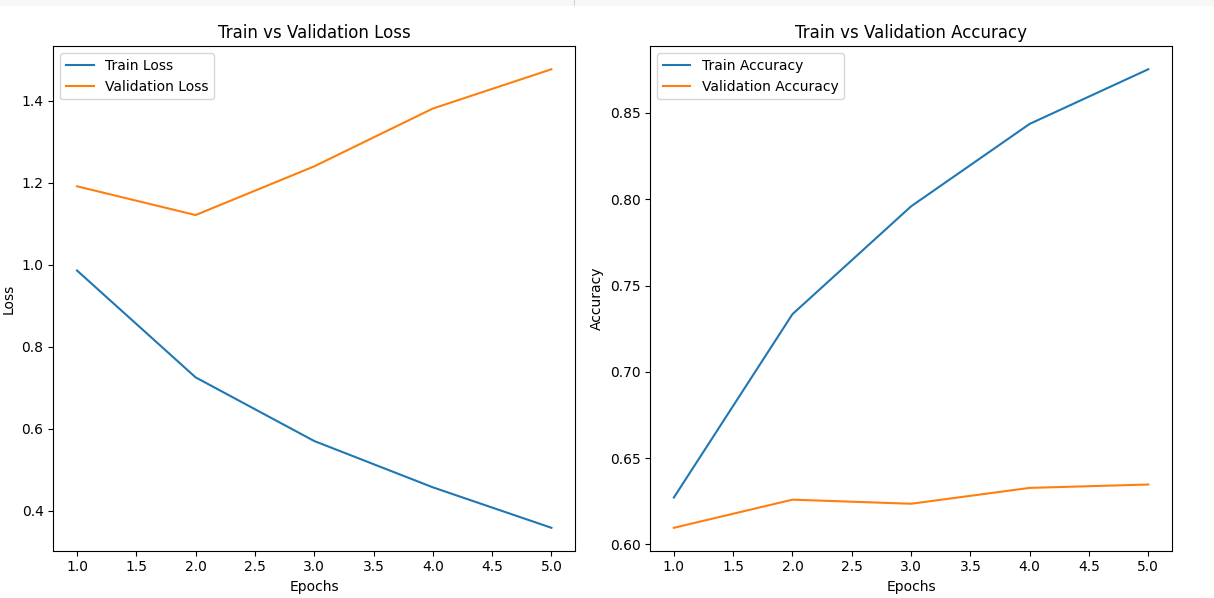
[테스트 데이터]
Test Loss: 1.0959, Test Accuracy: 0.6315첫번째로 시도했던 것보다는 아주 조오오오오오금 괜찮아 진 것 같기도?
Try3 Learning Rate Scheduler 적용/ optimaizer 개선
Learning Rate Scheduler 적용
- 학습률을 조절하여 과적합 문제 완화 목적
from torch.optim.lr_scheduler import ReduceLROnPlateau
scheduler = ReduceLROnPlateau(optimizer, mode='min', factor=0.1, patience=2, verbose=True)optimizer 개선
- 모델이 학습 데이터의 특정 패턴에 과하게 의존하지 않도록 하기 위함
optimizer = optim.Adamax(model.parameters(), lr=0.001, weight_decay=1e-4)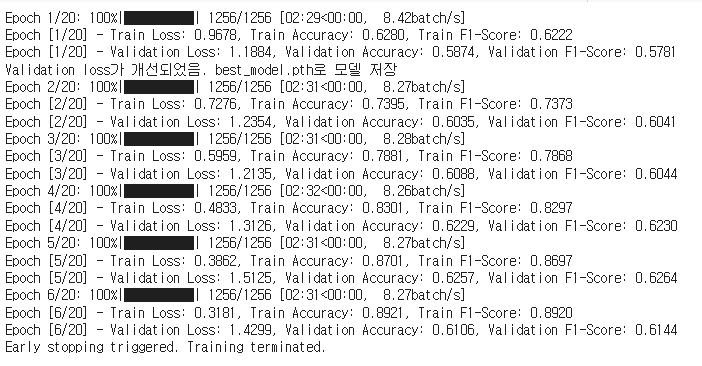
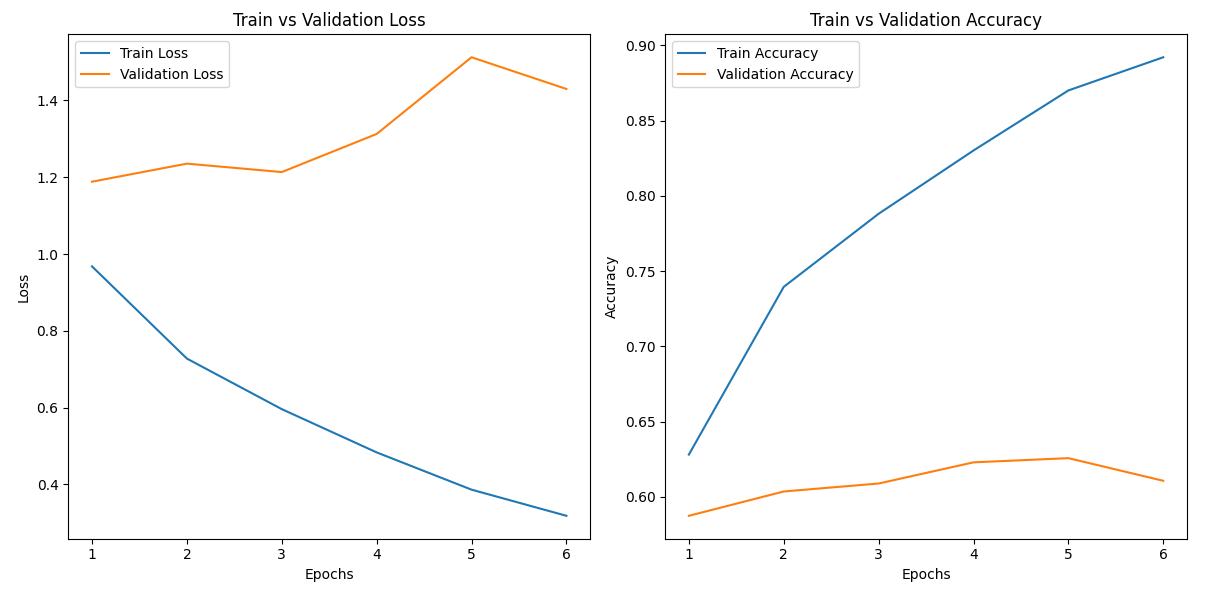
[테스트 데이터]
Test Loss: 1.1740, Test Accuracy: 0.5830???? 잘 모르겠다.. 😅
Try4 batch size 늘리기
GPU 성능 걱저응로 Batch size를 16으로 낮게 설정했는데, 혹시 너무 낮은 값으로 디테일한 부분까지 캐치하느라 과적합이 발생한 건 아닌지 의심...
train_loader = DataLoader(train_dataset, batch_size=32, sampler=sampler)
valid_loader = DataLoader(valid_dataset, batch_size=32, shuffle=False)
valid_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)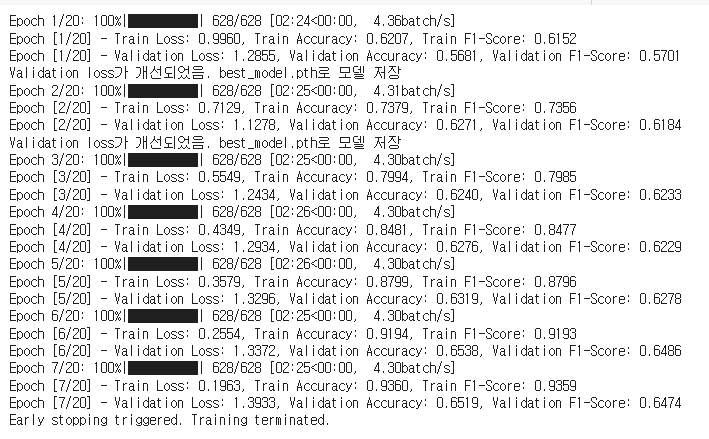
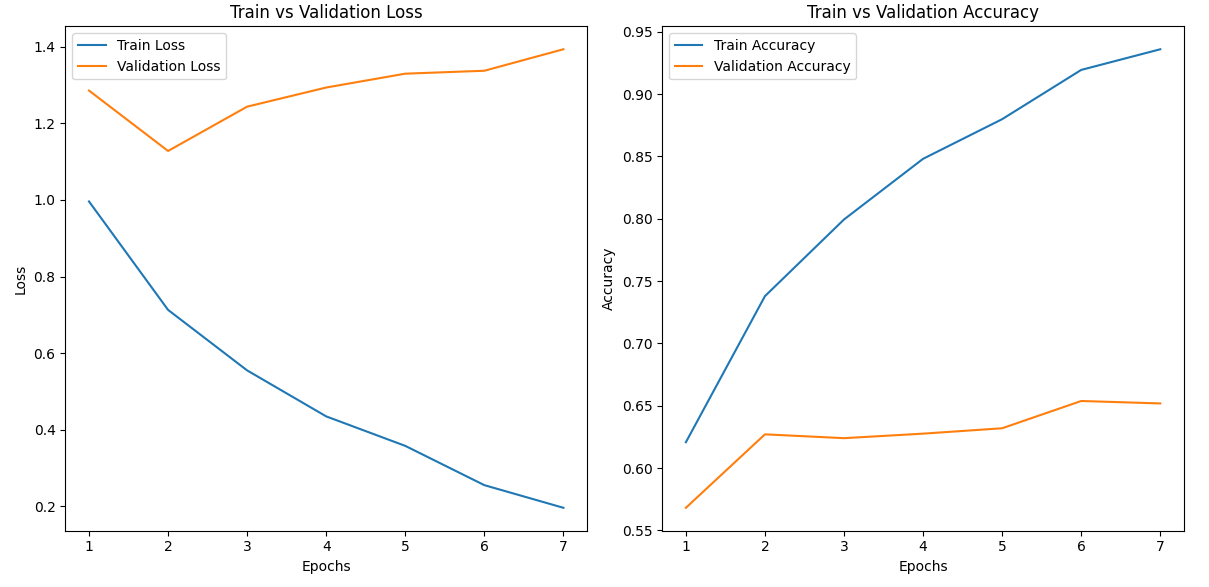
[테스트 데이터]
Test Loss: 1.1081, Test Accuracy: 0.6172흠.. 더 잘 모르겠다.. Try2가 아직까지 성능이 조금 더 좋다...
Try5 train 전체 데이터 증강
생각해보니
from collections import Counter
from torch.utils.data import WeightedRandomSampler, DataLoader
# train_dataset의 레이블 분포 계산
class_counts = Counter(train_dataset.labels)
print(f"Class counts: {class_counts}")
# 클래스별 가중치 계산
total_samples = sum(class_counts.values())
class_weights = {cls: total_samples / count for cls, count in class_counts.items()}
print(f"Class weights: {class_weights}")
# 샘플별 가중치 생성
sample_weights = [class_weights[label] for label in train_dataset.labels]
# WeightedRandomSampler 생성
sampler = WeightedRandomSampler(weights=sample_weights, num_samples=len(sample_weights), replacement=True)샘플별 가중치를 계산하여 넣었는데,
내가 구현한 오버샘플링은 학습하면서 생성되기 때문에
샘플별 가중치는 원본데이터에 대해서만 반영된다.
결국 생략하기
from torch.utils.data import DataLoader
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
valid_loader = DataLoader(valid_dataset, batch_size=32, shuffle=False)
valid_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)train 전체 데이터 증강용 augmentations 만들어서 적용
import albumentations as A
from albumentations.pytorch import ToTensorV2
# disgusted 클래스 전용 증강
disgusted_augmentations = A.Compose([
A.HorizontalFlip(p=0.5),
A.RandomGamma(p=0.2),
A.Rotate(limit=30, p=0.3),
A.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
A.Resize(224, 224),
ToTensorV2()
])
# 모든 train 데이터에 적용할 기본 증강
general_augmentations = A.Compose([
A.HorizontalFlip(p=0.3),
A.RandomBrightnessContrast(p=0.3),
A.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
A.Resize(224, 224),
ToTensorV2()
])
# Default augmentations for validation/test (No augmentation, only normalization and resizing)
default_augmentations = A.Compose([
A.Resize(224, 224),
A.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
ToTensorV2()
])
class_augmentations = {
"disgusted": disgusted_augmentations,
} def __len__(self):
# disgusted 데이터를 여러 번 중복 반환해 데이터 비율을 높임
return len(self.image_paths) + len(self.disgusted_indices) * 2
def __getitem__(self, idx):
if idx < len(self.image_paths):
# 일반 데이터 반환
img_path = self.image_paths[idx]
label = self.labels[idx]
category = list(self.category_to_label.keys())[label]
else:
# disgusted 데이터를 중복 반환
disgusted_idx = self.disgusted_indices[(idx - len(self.image_paths)) % len(self.disgusted_indices)]
img_path = self.image_paths[disgusted_idx]
label = self.labels[disgusted_idx]
category = "disgusted"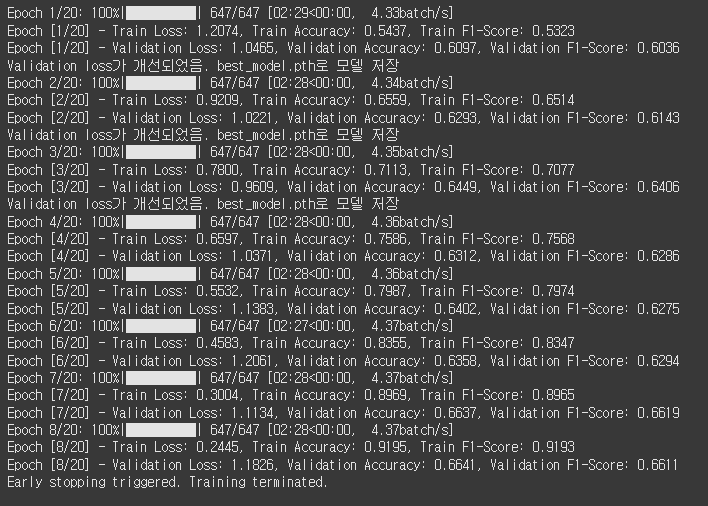
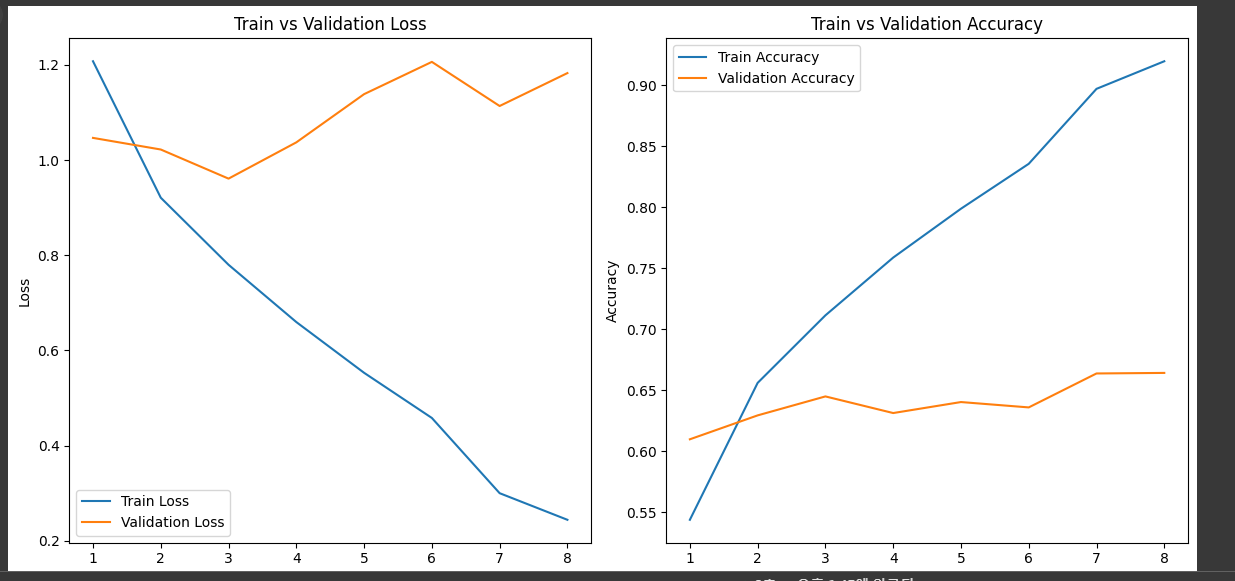
Test Loss: 0.9736, Test Accuracy: 0.6508한 번 정규화 없애봄

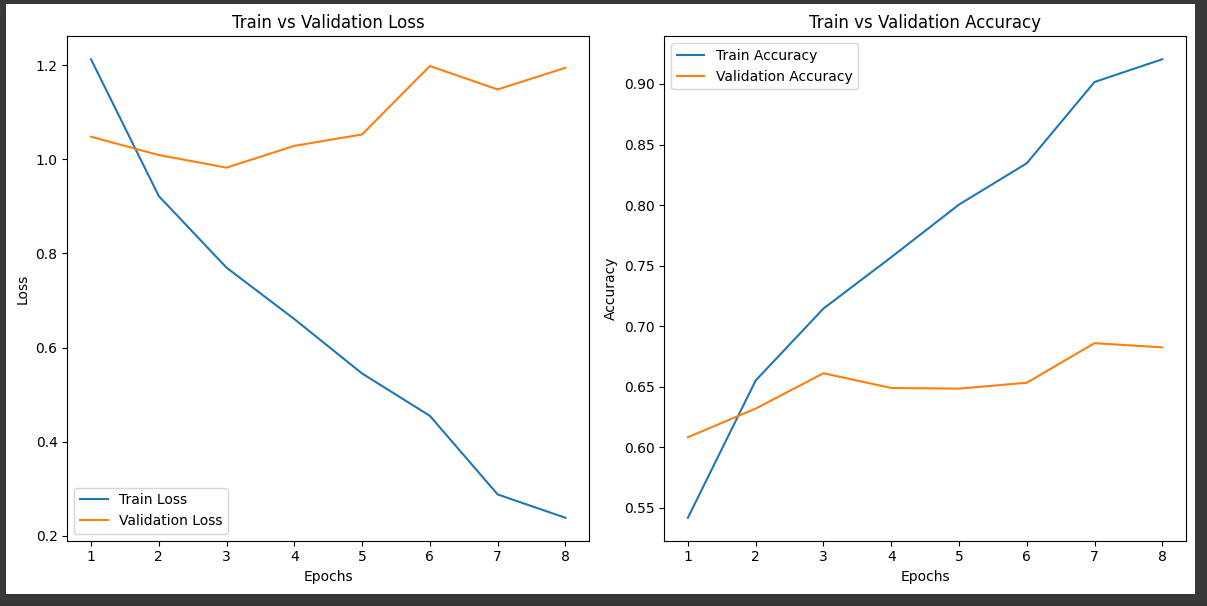
[테스트 데이터]
Test Loss: 0.9824, Test Accuracy: 0.6611흠... 😓 정규화 있는 Try5 모델로 구글에 있는 사진 다운로드 받아서 테스트 해봤다.
외부 자료 테스트
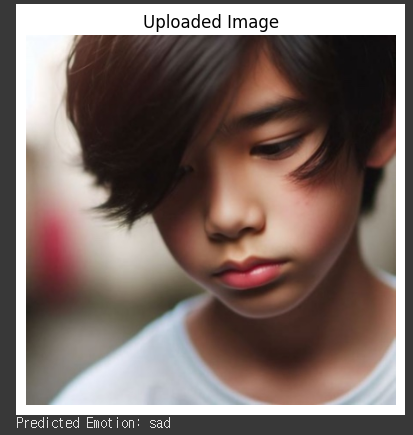
내가 생각한 감정 sad
예측한 감정 sad
내가 생각한 감정 fearful
예측한 감정 angry

내가 생각한 감정 neutral
예측한 감정 sad

내가 생각한 감정 happy
예측한 감정 surprised

내가 생각한 감정 happy
예측한 감정 disgusted

내가 생각한 감정 happy
예측한 감정 happy

내가 생각한 감정 angry
예측한 감정 angry

결론
사람의 얼굴을 보고 감정을 파악하는 일은 사람에게도, 기계에게도 쉽지 않은 일이다.
