(1) Beam Search
이전에 Seq2Seq에 대해 다룰 때 Decoder에서 최종적으로 추론하는 과정의 기억을 되살려보자. 최종 추론 단계에선 각 time step마다의 output을 그대로 다음 time step의 input으로 이용하였다. 이 과정을 Greedy decoding이라고 한다. 즉, 현재 time step에서 그때그때 가장 높은 확률로 나오는 단어를 Deterministic하게 다음 단어로 넣는 것이다. 이 방법은 하지만 한 번 추론이 잘못되면 되돌릴 수 없는 잘못된 추론결과가 나오게 된다. 이를 개선시키기 위해 두 가지 방법이 제시된다.
이상적으로 우리는 처음 주어진 input x에 대해 추론결과로 생성된 시퀀스 y에 대해 다음과 같은 확률을 최대화 시키는 것이 목적이다.
먼저 완전탐색 방법(Exhaustive search)은 가능한 모든 y를 계산한 뒤 가장 높은 확률의 y를 최종 추론 결과로 내보내는 것이다. 하지만 계산복잡도가 이기 때문에 너무 비싸다(expensive).
따라서 Beam search 방법을 주로 사용하는데, 모든 y를 계산하는 것이 아닌 매 step마다 정해진 k라는 숫자만큼의 가장 높은 score의 시퀀스를 keep해 가는 방식이다. k는 beam size라고 부르며 score에 대한 식은 다음과 같다.
이 score는 전부 negative한 값을 가지며 값이 큰 것(절댓값이 작은거)을 keep 하는 방식으로 진행된다. Beam search는 globally optimal solution을 찾지는 못하지만 대신 완전탐색 방법보다는 훨씬 효율적이고 복잡도도 훨씬 낮다.
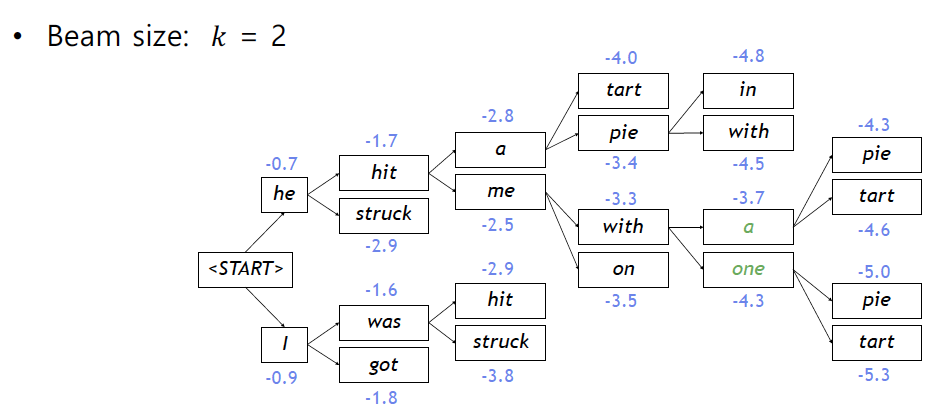
그림을 보면 추론의 매 time step 마다 하나의 시퀀스에 대해 두개의 경우의 수를 확인하고(그림에서는 총 4개) 이 중 두개에 대해서만 다음 time step을 진행하는 방식이다. 최종적으로 "he hit me with a pie" 라는 시퀀스가 나오게 된다.
Beam search를 사용한다면 각 시퀀스 별로 끝나는 시점, 즉 EOS 토큰이 나오는 시점이 각각 다를 것이다. 하나가 먼저 끝나더라도 그 시퀀스는 보존해놓고 beam size 값을 하나 줄인채 나머지의 beam search를 계속 진행한다. 최종적으로 beam search는 지정한 Time step만큼이 지났거나 혹은 지정한 갯수의 완료 시퀀스가 모일때까지 진행하게 된다. 지정한 갯수가 모인다는 뜻은 곧 beam size가 0이 됨을 의미한다. 그러나 시퀀스가 끝나는 시점이 각각 다르다는 것은 곧 길이가 다르다는 것이고 이는 긴 시퀀스의 score가 일반적으로 더 낮다는 문제를 야기한다. 따라서 각 시퀀스의 score를 각 시퀀스의 길이로 나눠주는 normalize를 진행하면 문제를 일부 해결할 수 있다.
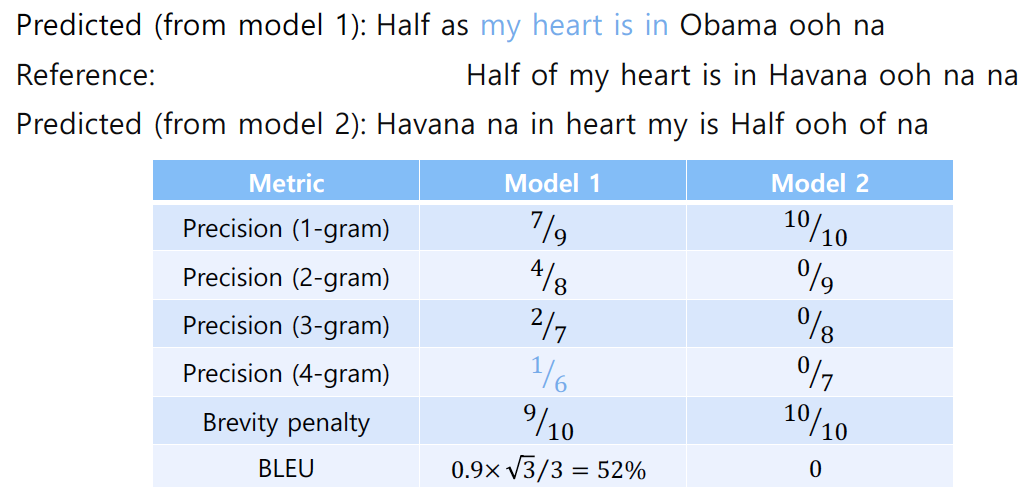
(2) BLEU(BiLingual Evaluation Understudy) score
출력이 시퀀스인 경우 그 성능을 확인하는 지표는 일반적인 accuracy나 F-score로 할 수 없다. 시퀀스 내 단어의 순서를 고려하지 않는 지표이기 때문이다. 따라서 시퀀스 생성 모델, 특히 기계번역 모델의 성능을 확인할 지표로 BLEU score를 사용하게 된다(물론 단점도 있는 듯 하다).
prediction 시퀀스와 reference 시퀀스간의 N-gram precision을 로 확인한다. 식은 다음과 같다.
min항은 brevity penalty라고 부르는데, 너무 짧은 시퀀스에 대해 패널티를 주는 것이다. 다음 그림에서 계산 방법을 더 정확히 확인할 수 있다.