논문 출처 : https://arxiv.org/abs/1706.03762
1. Introduction
RNN과 LSTM, GRU 같은 RNN 계열 시퀀스 모델은 기계번역이나 언어모델같은 task에서 성능을 올리는데 큰 공을 세웠다. 그러나 Recurrent 모델에서 time step으로 나뉘는 특성상 parallelization을 막는 크나큰 단점이 있었고, 이는 시퀀스 길이가 길어짐에 따라 단점이 극대화되며 곧 메모리 용량 관련 문제도 야기시켰다. 이러한 단점을 해결하기 위해 몇몇 trick들이 제시되어 왔으나 완벽하게 해결하지는 못했다.
Attention은 문장의 길이에 크게 구애받지 않고 각 토큰간의 연관성을 좀 더 잘 표현함에 있어서 크게 주목받는 방법이었다. 하지만 Seq2Seq with attention에서 처럼 대부분의 시도가 기존의 RNN 계열 모델과 함께 사용하는 것 뿐이었다.
따라서 본 논문은 기존의 RNN 구조를 전혀 사용하지 않고 오로지 Attention 기법만을 사용하여 모델을 구성하겠다는 것에 그 목적이 있다. 이로인해 앞에서 언급한 parallelization이 자연스럽게 해결될 것임을 강조하였다.
2. Model Architecture
기계번역 등과 같은 input 시퀀스와 전혀 다른 새로운 구조와 형태를 가진 output 시퀀스를 만들어 내는 모델을 Neural Sequence Transduction Model이라고 부른다. 기본적으로 이전에 봐왔던 것처럼 이런 Transduction model은 Encoder-Decoder structure를 가지게 된다. 즉 Encoder는 task에 맞는 symbol representation으로 된 input sequence 를 continuous representation으로 된 으로 만들어내는 역할을 한다. Decoder는 이 를 이용해 를 매 time step마다 하나씩 만들어나간다. 이러한 모델들은 auto-regressive하기 때문에 이전에 만들어진 결과물들을 추가적인 input으로 다음 결과물을 만들어내는데 사용하는 방식을 가졌다. 적어도 지금까지 RNN계열에서는 그랬다는 것이다.
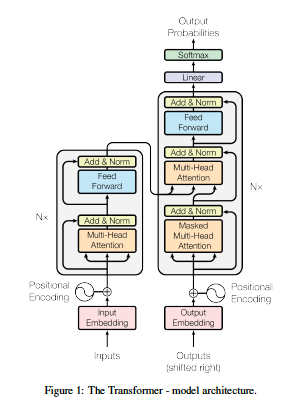
위 그림은 Transformer의 전체적인 구조이다. Encoder와 Decoder의 형식을 유지하는 것은 같지만 내부 구조는 기존의 Transduction Model과 완전히 다르다. 하나하나 뜯어보도록 하자.
(1) Encoder and Decoder Stacks
Encoder
Encoder는 input-임베딩레이어 위에 그림 좌측의 회색 블록 6개를 쌓는 것으로 구성되어 있다. 각 회색블록은 두 개의 Sub-layer로 구성되어있는데, 하나는 Multi-head Self-attention mechanism 이고 다른 하나는 position-wise fully connected feed-forward network이다. 각 sub-layer에는 Residual connect가 존재하고 그 결과물에 LayerNorm을 하는 것으로 구성된다. 논문의 수식을 참고하면 의 형태가 각 Sub-layer에게 적용되는 것이다. 이 residual connect와 이후 블록이 쌓이는 것을 고려해 원활하게 연산될 수 있도록 임베딩 레이어 뿐만 아니라 블록의 출력 dimension은 무조건 로 고정한다고 한다.
Decoder
Decoder도 마찬가지로 output-임베딩레이어 위에 그림 우측의 좀 더 긴 회색블록을 6개 쌓는 것으로 구성된다. 총 세 단계로 구성되는데 첫 번째는 Masked Multi-head Self-attention mechanism이다. 뒤에서 자세히 설명하겠지만 이는 Decoder의 매 generate 단계마다 아직 등장하지 않은 단어들을 아예 생각하지 않고 이전의 결과물로만 추론해낼 수 있도록 Masking(확률을 0으로 만든다.)하는 과정이다. 두 번째는 기존과 동일한 Self-attention 구조이지만 Self-Attention의 세 가지 구성요소인 Query, Key, Value 중 Key와 Value는 Encoder의 마지막 출력에서 가져오는 구조이다. 마지막은 Encoder와 동일한 position-wise fully connected feed-forward network이다.
(2) Attention
이 모델의 가장 핵심인 Self-Attention 구조에 대해 더 깊고 자세히 알아볼 시간이다. 사실 부스트캠프 교육과정 중에 학습정리로 이 글에서 Self-Attention 구조에 대해 자세히 설명한 바가 있지만 논문의 문장을 최대한 인용하며 다시 한 번 제대로 설명해 보겠다. 이전에 Seq2Seq with Attention의 그 Attention과 많이 비슷하기는 하나 RNN 구조 자체를 대체하는 점에서 추가된 부분이 많다.
(구조를 설명하기 위한 모든 그림과 도형은 논문과 이 블로그에서 가져왔음을 밝힌다.)
Scaled Dot-Product Attention
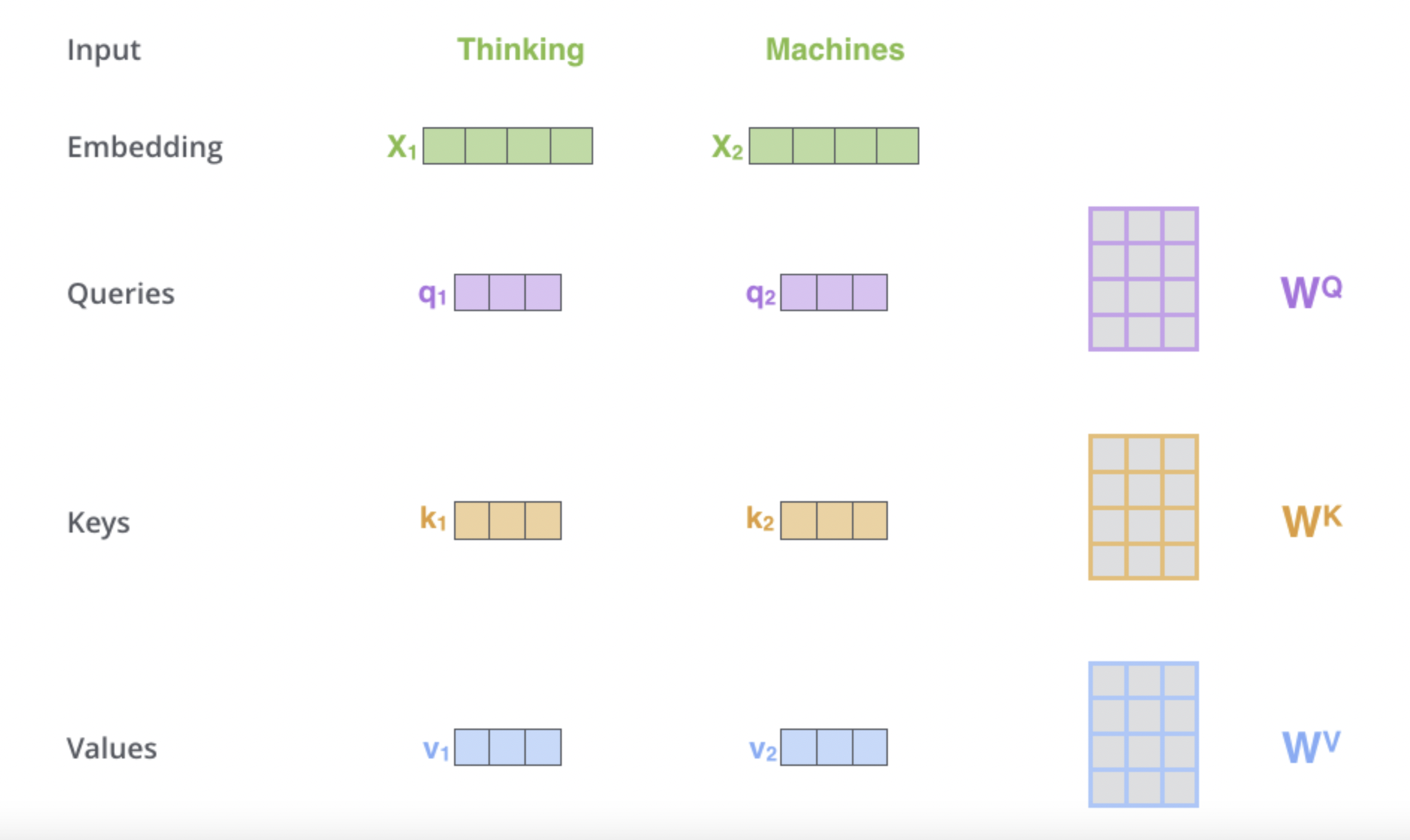
임베딩에 관한 얘기는 뒤에서 하고 우선 각 단어가 임베딩되어 의 형태로 Encoder 블록에 들어왔다고 하자. 참고로 앞에서 언급했듯이 임베딩 dimension 역시 로 고정한다는 점을 기억하자. 각 단어의 임베딩 벡터들은 를 통해 Query 벡터, Key 벡터, Value 벡터로 변환된다. Query 벡터와 Key 벡터의 형상이 같음을 기억하자. 이 는 Hyperparameter로 empirically하게 설정하는 값이며 저자는 로 같게 설정하였다. 다만 명확한 구분을 위해 숫자가 아닌 문자를 통해 표기하여 설명하겠다.
Query란 해당 단어를 기준으로 연관성 검사를 하겠다는 것으로 이해하면 된다. Key는 그렇다면 직관적으로 Query 단어와 연관성 검사를 당하는 모든 단어들(자기 자신 포함)이 될 것이다. Value는 이전의 Seq2Seq with attention에서 Encoder의 각 hidden state들 이라고 생각하면 좋을 것 같다. 구체적인 메커니즘을 확인해보자.
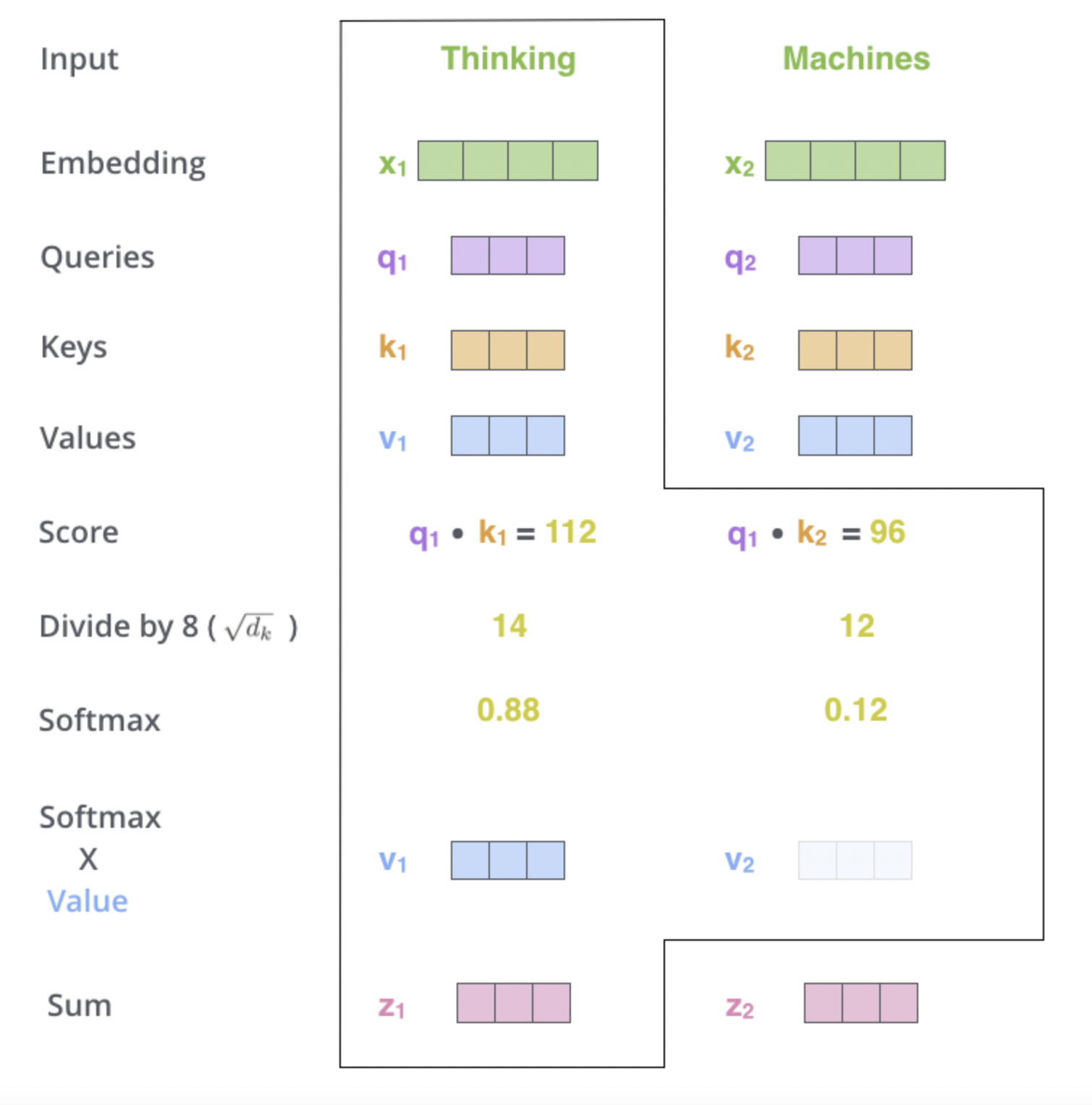
우선 하나의 임베딩 벡터가 Query 벡터 으로 변환되었다. 이 은 다른 단어들과의 연관성을 측정하기 위해 모든 단어들의 Key 벡터 (batch를 신경쓰지 않고 n개의 token으로 이루어진 하나의 시퀀스에 대해서만 진행한다고 편의를 위해 가정) 와의 내적을 진행한다. 그 값이 위 그림에서 Score에 해당하는 것이다. 내적을 해야하기 때문에 Query와 Key가 라는 같은 dimension을 가져야 했던 것이다. 여기까지의 결과물은 이다.
그 후 score 벡터내 각 element에 대해 Scaling을 목적으로 를 곱해준다. 이 Scaling은 내적이라는 연산이 벡터 dimension이 길어질 수록 값이 매우 커지거나 작아지는 등 편향이 짙어 softmax연산에서 분포가 더욱 한 쪽으로 치우치는 문제가 있고 이는 gradient 값에도 안 좋은 영향을 주기 때문에 이를 방지하기 위한 Approach라고 할 수 있다.
이 후 Softmax 연산을 통해 마치 이전처럼 attention 벡터를 만들게 된다. 여기에 각 단어들의 Value 벡터 과 Weighted sum을 하게 된다. 즉 attention vector를 이라고 할 때, 의 연산을 통해 최종 의 길이를 가지는 하나를 만들어내게 된다.
모든 단어에 대해 각각 Query로 적용하여 같은 연산을 진행하게 되면 우리는 최종적으로 의 출력물을 얻게된다.
Attention 과정 전체를 식으로 정리하면 다음과 같다.
Multi-head Attention
저자는 Self Attention 하나, 즉 하나의 Query, Key, Value 행렬로 벡터를 만들어내는 것보다 이를 head(parallel attention layer)라는 단위를 통해 여러개의 Self-Attention 연산을 수행하고 그 결과물을 결합하여 벡터를 만들어내는 것이 각 head마다 다른 feature를 잡아내 더욱 좋은 성능을 낼 것이라 생각했다.
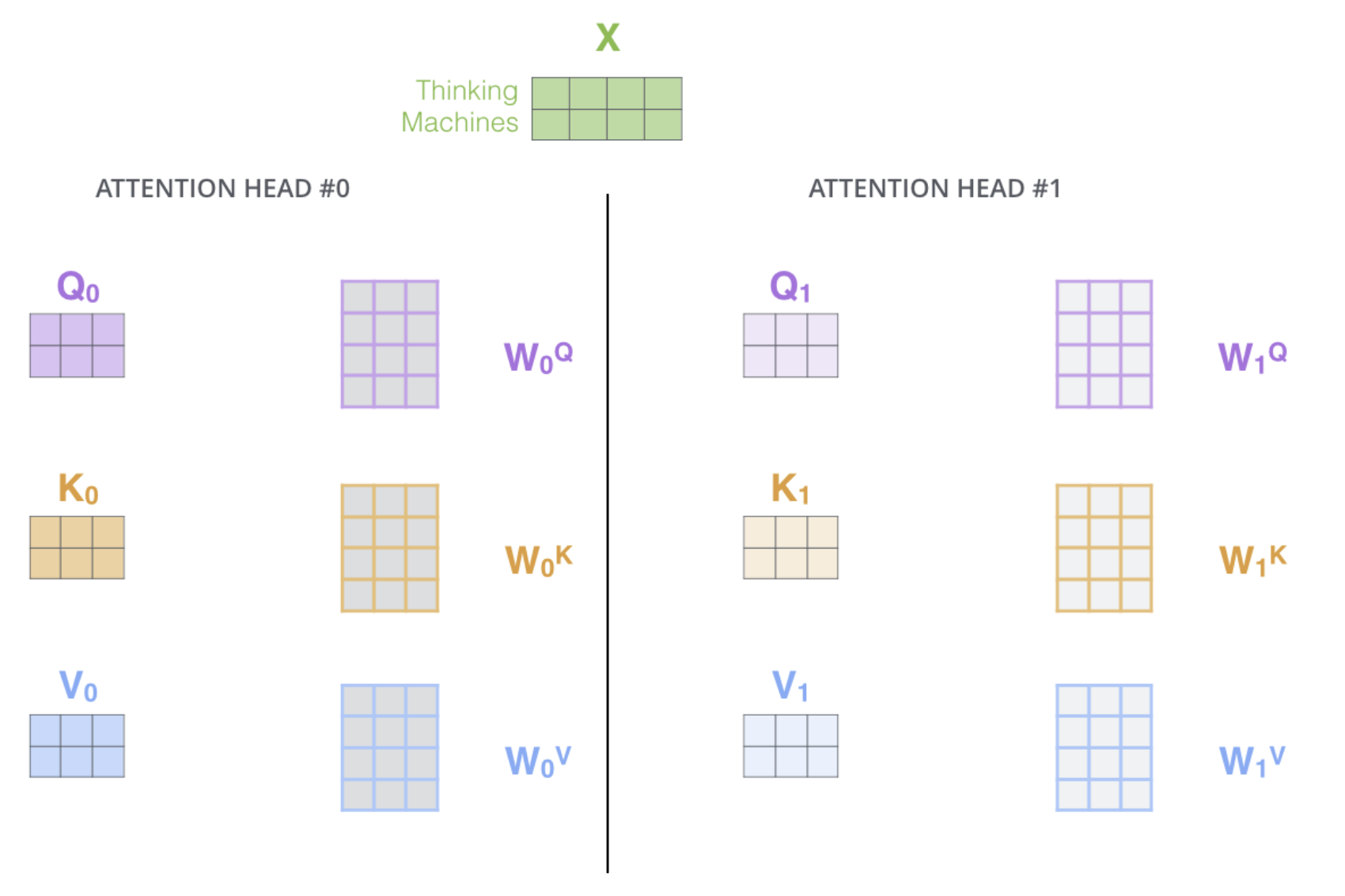
즉, 동일한 Scaled Dot-Product Attention mechanism이 각 head마다 다른 가중치 행렬들을 통해 서로 다른 를 내보낸다는 것이다.
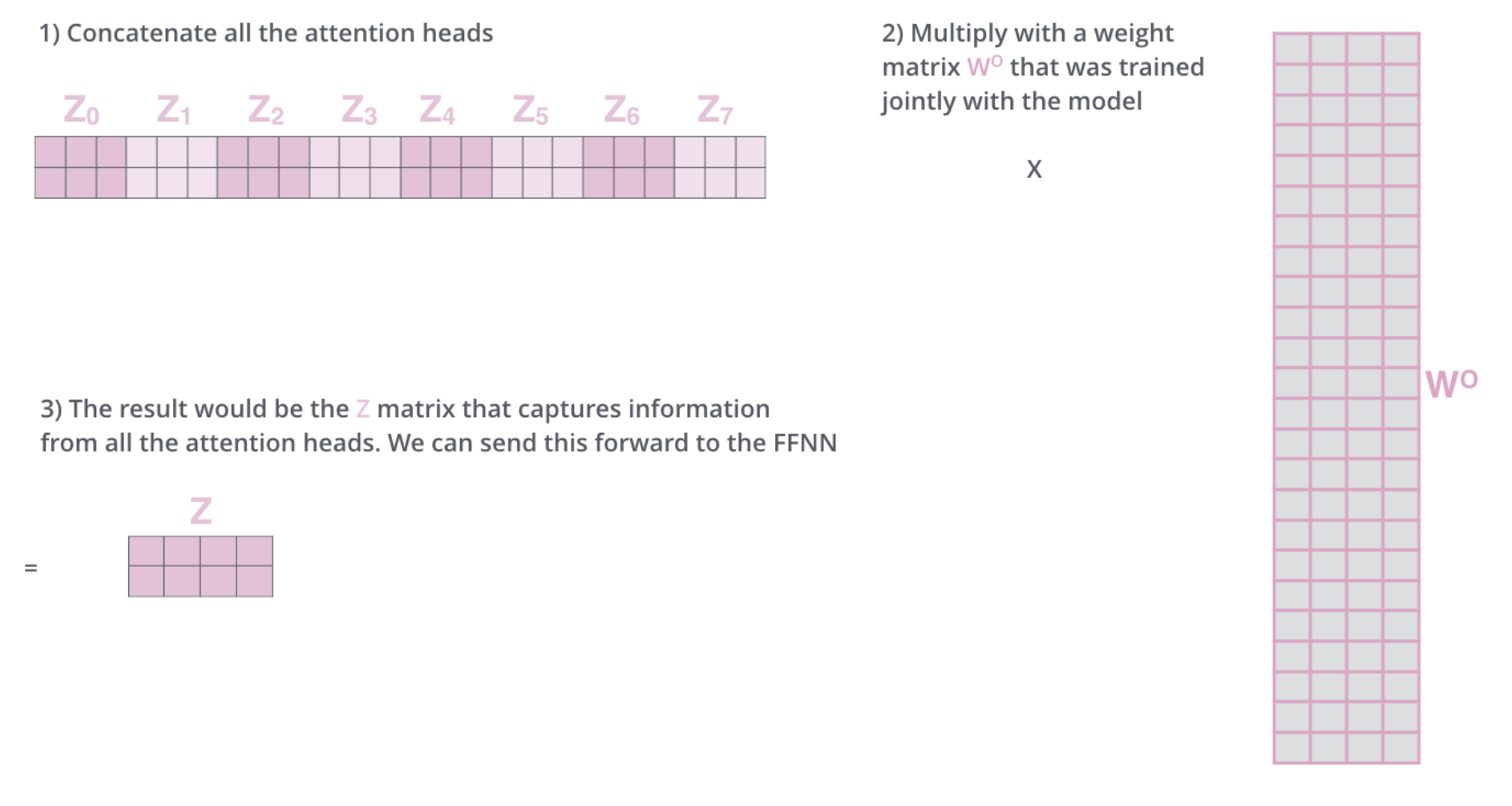
위 그림에서는 head 갯수를 8개로 가정하였다(). 실제로 저자도 head 갯수가 8일때 가장 좋은 성능을 보였다고 언급하고 있다. 이전에 우리가 써왔던 annotation 그대로 각 가 연결(concatenation)되어 라는 벡터를 만들게 된다. 여기에 라는 새로운 가중치 행렬을 곱해 최종적으로 모든 정보를 담은 벡터가 만들어진다.
Batch까지 고려한다면 output의 shape가 바뀔 수는 있지만 각 단어를 표현하는 representation이 의 벡터라는 점은 변함이 없다는 것을 유의하자. 저자는 최종적으로 로 값을 지정하였다. 뒤에서 다양한 dimension 값에 대해서 실험하는 부분이 나오니 우선 값 자체에 대해 의구심이 들어도 조금만 참아보자. Multi-head attention의 전체 수식은 다음과 같다. 참고로 저자의 말에 따르면 head 단위로 나눠 하는 것과 하나의 attention으로 하는것의 연산량 차이는 크게 없다고 한다.
Applications of Attention in our Model
Encoder와 Decoder에 적용되는 self-attention은 위치에 따라 조금씩 다른 것을 앞에서 언급한 바 있다. 기본적으로 위에서 설명한 구조를 따르지만 2개의 sub-layer는 mechanism이 조금 다른 attention layer이다.
-
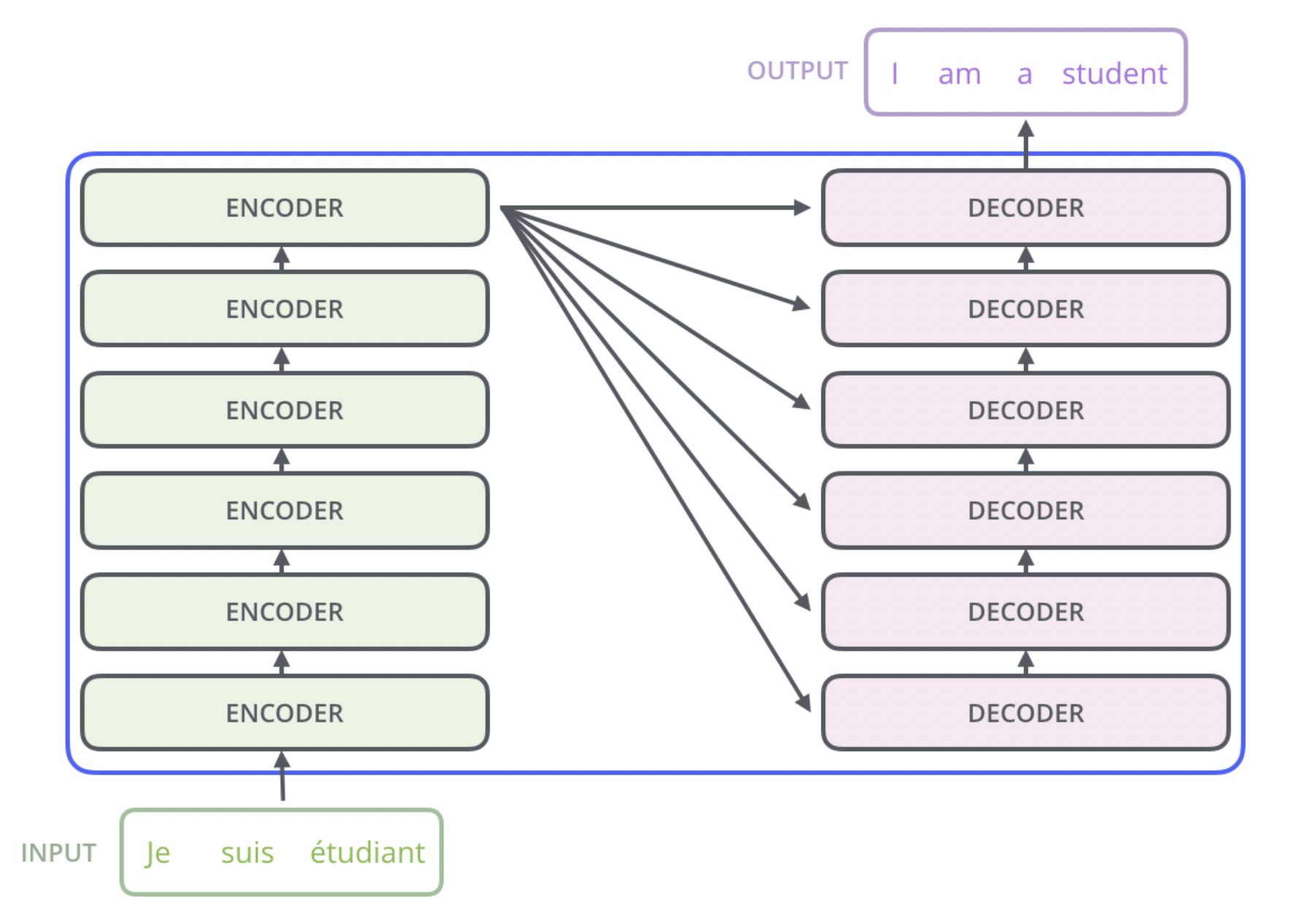
Encoder-Decoder attention이라 불리는 이 layer는 Decoder 블록의 가운데에 위치해있다. Encoder에서 오는 정보를 받는 layer의 역할을 한다. 마치 이전의 Seq2Seq with attention에서 Decoder가 Encoder의 모든 hidden states를 통해 context vector를 만들었듯이 Encoder의 정보를 활용하기 위해, Query는 Decoder 블록의 아래에서 올라오는 output을 통해서 만들게 되지만 Key와 Value는 Encoder 블록 stack의 가장 맨위 마지막 output을 통해 만들게 된다. Decoder 블록도 여러개가 stack으로 쌓여있다고 위에서 언급하였는데, 매 블록마다 똑같이 Encoder 블록 stack의 가장 맨위 마지막 output을 사용한다(그림 참고).
-
Masked Multi-head attention이라 불리는 이 layer는 Decoder 블록의 맨 아래에 위치한다. 앞에서도 언급했지만 우리가 일반적인 Decoder의 동작을 생각해보면 Decoder의 input으로 들어가는 시퀀스는 한번에 다 들어가는게 아니라 차례대로 한 단어씩 들어가서 다음 단어를 추론해내는 방식으로 진행된다. 물론 input이 right shift 되어 SOS 토큰으로 시작해야하는 것은 당연하다. Transformer의 Decoder에서도 같은 동작을 수행하기 위해서는 미래에 등장할 단어들은 신경쓰지 않는 방식이 적용되어야 한다는 뜻이다. 실제로 논문에서는 We need to prevent leftward information flow in the decoder to preserve the auto-regressive property 라고말하고 있다. 이를 Self-attention에서 구현하기 위해 mask 개념이 도입된다. 하던대로 Decoder의 input sequence의 모든 단어에 대해 Query와 Key의 내적을 진행하고 나면 총 의 행렬이 생길 것이다. 이때 row는 query 단어들이라고 하고 column은 key 단어들이라고 하자. 미래의 정보를 반영하지 않기 위해 이 행렬을 하삼각행렬(lower triangular matrix)으로 만든 후 위쪽 부분을 0이 아닌 매우 작은 값()로 채우게 된다. 각 Query 단어의 내적값 벡터 기준으로 보면 해당 query 단어까지만 내적값으로 메꿔져있고 그 이후부터는 로 채워져있는 형태인 것이다. 이후 softmax를 진행하면 에 해당하는 값은 0으로 된다. Value와 weighted sum하는 과정에서 미래의 단어 value 벡터들은 완전히 무시된다는 것이다.
(3) Position-wise Feed-Forward Networks
크게 어려울 것 없는 2개의 fc layer로 구성된 network이다. 핵심은 ReLU activation function을 사용했다는 것과 로 정했다는 것이다. Position-wise가 붙은 것은 이전의 각 단어의 벡터를 구하는 과정이 단어끼리 dependent했지만 이 network에서는 결과를 구하는 과정이 당연히 서로 independent하게 fc layer를 지나는 결과물일 뿐이기 때문이다.
(4) Embeddings and Softmax
Encoder 블록으로 들어가기전 input Embedding 하나, Decoder 블록으로 들어가기전 output Embedding 하나, Decoder output을 다시 단어를 추론하기 위한 vocab size 길이의 벡터로 바꿔주는 linear까지 모두 저자는 같은 learned embedding weight matrix를 쓴다고 명시하고 있다. 단 embedding layer들에 한해 weight에 을 곱한다고 한다.
(5) Positional Encoding
이대로만 되면 사실 시퀀스 안에서 단어의 순서는 전혀 전혀 고려되지 않는다. 그렇기에 우리는 임베딩된 단어 벡터들에게 시퀀스내에서 해당 단어의 위치에 대한 정보를 더해줘야 한다. 를 문장 내에서 단어의 위치, 를 각 단어의 임베딩 벡터에서 몇 번째 dimension(index)인지라고 할 때, 다음과 같은 식으로 positional 벡터를 구성한다.
이 과정을 통해 저자는 가변적인 시퀀스길이와 상관없이 문장의 위치정보를 잘 전달할 수 있다고 한다. 이 값들은 참고로 학습되거나 하이퍼파라미터 값이 아닌 미리 계산되는 pos와 i에 따른 고정적인 값들이다.
3. Other points
(1) optimizer
Adam optimzier()를 사용하였으며 learning rate는 다음과 같은 식을 통해 결정한다.
(2) Residual Dropout
0.1의 dropout rate로 각 sub_layer와 Add&Norm 사이에서 dropout을 진행한다. 또 embedding과 positional encoding을 더하는 과정에도 dropout을 적용한다.
(3) Label Smoothing
이 논문에서 처음 제시된 Lable Smoothing() 기법이 적용되었다. 모델의 confidency를 낮추기 때문에 perplexity가 높아지는 단점이 있지만 전체적인 성능을 올리는데는 좋은 기법이다.
4. Why Self-Attention

저자는 크게 세 가지 측면에서 기존의 모델들 보다 나은 점을 언급하고 있다.
먼저 Complexity per Layer인데 즉 각 Layer 마다의 연산량을 의미한다. RNN과 비교했을 때 Self-Attention의 경우 내적 연산에서 의 연산을 진행하고 이를 d개 모아야 하므로 총 의 연산량을 가진다. 반면 RNN의 경우 각 time step n번동안 의 연산을 하게 되는데 이 행렬연산이 의 연산량을 가지므로 총 의 연산량을 가진다. 현실적으로 n이 d보다 훨씬 큰 값을 가지므로 complexity per layer 자체는 RNN이 더 낫다고 할 수 있다.
그러나 Sequential Operations 에서 큰 차이가 발생한다. Self Attention의 경우 한 시퀀스에 대한 representation을 만들기 위해 한번의 연산이면 해결된다. 하지만 RNN의 경우 시퀀스의 한 단어에 대한 연산이 끝나야지만 다음 단어로 넘어갈 수 있기 때문에 의 연산량을 가진다.
마지막으로 Maximum Path Length는 시퀀스 내 가장 멀리 떨어져 있는 단어끼리 연관성을 측정하기 위한 연산량을 의미하는데 Self-Attention은 한번의 연산으로 모든 단어끼리의 연관성을 측정하지만 RNN의 경우 처음단어에서 끝단어까지 가는데 n번을 기다려야 하므로 여기서도 의 연산량을 가지게 된다.
종합해서 Self-Attention이 RNN보다 훨씬 빠르게 학습을 진행할 수 있다는 큰 장점을 가진다.
5. 마무리
Transformer는 현재 딥러닝의 트렌드를 이끄는 중요한 기술으로 반복해서 숙지해야할 논문이다. 추후에 LayerNorm이나 Residual connect에 대한 내용을 더 추가할 예정이다.
