
📌 포스팅 개요
"AI, 텐서플로우... 어디서부터 시작해야 할지 모르겠다고요? 🤔
그렇다면, 오늘은 쉽게 따라할 수 있는 AI 튜토리얼을 준비했습니다! 🎉
딥러닝의 시작, 텐서플로우(TensorFlow)와 함께 블랙기업 사장 AI를 만들어봅니다.
퇴사냐 충성이냐, 사장의 발언에 따라 결과를 예측하는 재미있는 AI를 함께 만들어봐요! 🕴️🔥"
🧠 텐서플로우(TensorFlow)란?

🎈 TensorFlow, 초보자도 이해할 수 있다!
텐서플로우는 구글(Google)이 만든 오픈소스 딥러닝 라이브러리입니다! 🌍
- 딥러닝(Deep Learning)이란? 🤖
데이터를 입력받아 스스로 학습하고, 새로운 데이터를 예측하는 머신러닝 기술의 한 분야입니다.
💡 텐서플로우의 주요 특징
- 사용자 친화적: 초보자부터 전문가까지 사용할 수 있는 다양한 API 제공! 👶🧑💻
- 다양한 플랫폼 지원: 모바일, 웹, 클라우드에서 AI 모델을 실행할 수 있어요. 📱💻🌐
- 강력한 커뮤니티: 수많은 튜토리얼과 예제가 있어서 쉽게 배울 수 있어요. 🙌
📘 텐서플로우로 무엇을 할 수 있나요?
- 이미지 분류 🖼️: "이 사진은 강아지일까 고양이일까?" 🐶🐱
- 음성 인식 🎙️: "이 음성은 누구의 목소리지?"
- 텍스트 생성 📝: "이 문장 뒤에 올 단어를 예측해보자!"
- 자연어 처리(NLP) 🗣️: "이 문장은 긍정적일까 부정적일까?"
- 그리고 오늘의 주제인 블랙기업 사장 AI까지! 🎯
🎯 오늘의 목표: 텐서플로우로 나만의 AI 만들기!

"사장의 발언에 따라 퇴사냐 충성이냐를 예측합니다!"
블랙기업 사장의 한마디를 학습한 AI가 여러분의 운명을 판단합니다.
초보자도 따라 할 수 있는 코드와 함께 재미있게 AI를 만들어볼까요?
🛠️ 텐서플로우를 활용한 AI 개발 과정
AI를 만들기 위해 데이터, 모델, 학습, 예측 단계를 거칩니다.
아래는 텐서플로우로 블랙기업 사장 AI를 만드는 전체 과정입니다.
📊 1단계: 데이터 준비
"퇴사"와 "계속 다닌다"로 나눌 수 있는 블랙기업 사장의 발언 데이터를 준비합니다.
- 예:
- "네가 만든 UI는 사용자 경험을 망치고 있어 📉" → 퇴사
- "이 프로젝트는 네가 아니면 불가능했어 🏆" → 계속 다닌다
# 블랙기업 사장 발언 데이터
texts = [
"네가 못해서 팀 전체가 고생하는 거야 💻🐛", # 퇴사
"이 프로젝트는 네가 아니면 불가능했어 🏆", # 계속 다닌다
]
labels = [0, 1] # 0 = 퇴사, 1 = 계속 다닌다🧱 2단계: 텍스트 전처리
딥러닝 모델은 텍스트 데이터를 바로 이해할 수 없어요!
따라서 텍스트를 숫자로 변환하는 Tokenization과 Padding 과정을 거칩니다.
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
# 텍스트를 숫자로 변환
tokenizer = Tokenizer(num_words=2000)
tokenizer.fit_on_texts(texts)
sequences = tokenizer.texts_to_sequences(texts)
x_train = pad_sequences(sequences, maxlen=10) # 길이를 10으로 고정🔮 3단계: 모델 구성
딥러닝의 꽃, LSTM(Long Short-Term Memory)을 활용해 문장의 맥락을 이해하는 모델을 구성합니다.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers <import Embedding, LSTM, Dense
# 모델 구성
model = Sequential([
Embedding(input_dim=2000, output_dim=32, input_length=10),
LSTM(32),
Dense(1, activation='sigmoid')
])🏋️ 4단계: 학습 및 예측
AI가 데이터를 학습한 후 새로운 발언을 입력받아 예측합니다.
# 모델 학습
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
model.fit(x_train, y_train, epochs=20, verbose=1)
# 예측 함수
def predict_reaction(statement):
test_seq = tokenizer.texts_to_sequences([statement])
test_pad = pad_sequences(test_seq, maxlen=10)
prediction = model.predict(test_pad)[0][0]
if prediction > 0.5:
print(f"'{statement}' => 계속 다닌다 🙇♂️")
else:
print(f"'{statement}' => 퇴사 🏃♀️")⚙️ 코드와 따라 하기(전체 코드)
아래는 텐서플로우로 사장의 발언을 학습시키는 코드 전체입니다.
복사-붙여넣기만 해도 나만의 AI를 만들 수 있어요! 🚀
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, Dense, LSTM
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
import numpy as np
# 문장 데이터를 100개로 확장
texts = [
# 퇴사 발언 (50개)
"네가 못해서 팀 전체가 고생하는 거야 💻🐛",
"디버깅도 못 하는 개발자가 개발자라고 할 수 있나? 🤦♂️",
"주말에 배포된 코드, 네가 고쳐야지. 쉬는 날도 네가 책임져 🛠️",
"회사 서버 터지면 네가 잠 깨서라도 고쳐야지 😴🔧",
"네가 짠 코드는 장애 유발의 근원 같아 ⚠️",
"실력 없는 개발자는 그냥 코딩만 하지 말고 문서 작성이나 해 📝",
"네가 만든 API는 불안정 그 자체야 🌐🚨",
"테스트 없이 코드를 올렸다고? 넌 진짜 무모하다 💥",
"야근비? 네가 회사에서 돈을 벌 가치가 있다고 생각해? 💸",
"팀의 속도를 늦추는 원인이 뭔지 생각해 봐 😡",
"왜 퇴근 시간이 되었는데도 일이 안 끝나? ⏰",
"지금 상황에서 버그를 잡아야 하는 건 네 책임이야 🐞",
"커밋 메시지가 이렇게 불친절해서야 😤",
"네가 만든 UI는 사용자 경험을 망치고 있어 📉",
"프로젝트의 발목을 잡는 코드는 네가 항상 짜더라 🤷♀️",
"코드 리뷰 시간 줄이려면 네 코드부터 제대로 짜 🛑",
"왜 서버 로그가 다 빨간색인지 네가 설명 좀 해 봐 🔴📜",
"테크 리더가 네 코드를 신뢰하지 못한다는 거 몰라? 🚫",
"내일까지 기능 다 완성 못 하면 책임은 네 거야 🕛",
"결과물이 이 정도라니, 실망스러워 😔",
"우리 회사에 이렇게 실력 없는 사람이 있었다니 🙄",
"왜 배포 이후 장애가 생겼는지 아직도 모른다고? 😡",
"왜 코드가 느린지 네가 설명 좀 해 줘 봐 🐌",
"그 정도 실력으로 개발자는 너무 과분하지 않나? 🤔",
"이건 네 책임이니까 끝날 때까지 집에 가지 마 🏢",
"왜 그렇게 기본적인 걸 몰라? 📘",
"주말에 회사 서버 터졌는데 왜 연락 안 받았어? 📞",
"배포 전 테스트를 빼먹었다니, 네가 짠 코드는 신뢰할 수 없어 🚧",
"이 프로젝트가 느린 건 네가 짠 코드 때문이야 💥",
"왜 다른 팀원이 항상 네 코드를 고쳐야 하지? 🤷♂️",
"네가 만든 함수는 진짜 끔찍해 😨",
"프로덕션 환경에서 네 코드는 언제나 장애를 유발해 🔥",
"이 정도 결과물이면 더 이상 할 말이 없다 😞",
"프로그래밍을 다시 배워야 할 것 같아 🧑🎓",
"이런 식이면 더 좋은 개발자를 찾는 게 낫겠어 🕵️♂️",
"네가 코드를 짤 때마다 QA가 늘어나 😵💫",
"왜 아직도 회사 도메인을 이해 못 해? 🌐",
"팀에 피해를 주는 코드만 짜지 말아 줘 🚨",
"지금 네가 하는 일은 다른 사람들의 시간을 뺏는 거야 ⏳",
"이 프로젝트는 네가 아니라 다른 사람에게 맡기는 게 나아 😤",
"네가 만든 모듈은 진짜 불안정하다 🤯",
"디자인 패턴은 커녕 기본적인 로직도 못 짜? 🧐",
"우리 회사 기술 스택이 너한테 너무 어려운 건가? 🤔",
"네가 작성한 코드 스타일은 진짜 최악이야 😩",
"왜 이 간단한 문제를 아직도 해결 못 했어? 🕰️",
"왜 네 코드에서만 항상 버그가 발생하지? 🐞",
# 계속 다닌다 발언 (50개)
"네 코드 덕분에 장애 없이 배포됐다, 정말 고마워! 🌟",
"네가 만든 기능은 사용자가 정말 좋아할 거야 😊",
"이 프로젝트는 네가 아니면 불가능했어 🏆",
"너의 디버깅 능력은 정말 대단해 🔍",
"네가 작성한 테스트는 진짜 철저하더라 ✅",
"이런 UI를 짠 네가 팀의 자랑이야 🎨",
"배포 후에도 버그 하나 없던 게 다 네 덕분이야 🌈",
"회사의 핵심 기술은 네가 만들어 준 거야 💡",
"너 없으면 팀이 돌아가지 않아 🔄",
"테크 리더가 네 실력을 인정하고 있어 👏",
"너의 아이디어 덕분에 프로젝트가 한층 나아졌어 💡",
"네 코드 리뷰는 모두에게 큰 도움이 돼 👍",
"너의 커밋 메시지는 정말 깔끔하고 이해하기 쉬워 🖋️",
"네가 작성한 API는 진짜 예술이야 🌐",
"너의 로직은 항상 효율적이고 빠르더라 🚀",
"우리 팀에 네가 있다는 게 큰 행운이야 🍀",
"사용자들이 네가 만든 기능을 칭찬하고 있어 🎯",
"이 프로젝트를 성공시킨 건 전적으로 네 공이야 🏅",
"네가 작성한 문서는 모두에게 도움이 돼 📚",
"회사에서 너 같은 개발자는 찾기 어려워 🛠️",
]
# 레이블 수정
labels = [0] * 50 + [1] * 50
# 텍스트 전처리
tokenizer = Tokenizer(num_words=2000)
tokenizer.fit_on_texts(texts)
# 텍스트를 시퀀스로 변환
sequences = tokenizer.texts_to_sequences(texts)
# 빈 시퀀스 필터링
valid_sequences = []
valid_labels = []
for seq, label in zip(sequences, labels):
if len(seq) > 0: # 빈 시퀀스가 아닌 경우에만 추가
valid_sequences.append(seq)
valid_labels.append(label)
# 패딩 처리
x_train = pad_sequences(valid_sequences, maxlen=10)
y_train = np.array(valid_labels)
# 데이터 크기 확인
print(f"x_train 크기: {x_train.shape}, y_train 크기: {y_train.shape}")
# 모델 구성
model = Sequential([
Embedding(input_dim=2000, output_dim=32, input_length=10),
LSTM(32, return_sequences=False),
Dense(1, activation='sigmoid')
])
# 모델 컴파일 및 학습
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
print("블랙기업 발언에 따른 반응 예측 모델 학습 시작!")
model.fit(x_train, y_train, epochs=30, verbose=1)
# 반응 예측 함수
def predict_reaction(statement):
test_seq = tokenizer.texts_to_sequences([statement])
test_pad = pad_sequences(test_seq, maxlen=10)
prediction = model.predict(test_pad)[0][0]
if prediction > 0.5:
reaction = "계속 다닌다"
humor = "사장님, 충성을 다하겠습니다! 🙇♂️"
else:
reaction = "퇴사"
humor = "이 회사, 더는 못 참겠다! 당장 퇴사합니다! 🏃♀️"
print(f"'{statement}' => 직원 반응: {reaction} (점수: {prediction:.2f})\n{humor}\n")
# 테스트 데이터
test_statements = [
"네가 만든 UI는 사용자 경험을 망치고 있어 📉",
"이 프로젝트는 네가 아니면 불가능했어 🏆",
"잠은 죽어서 자도 충분해",
"회사의 핵심 기술은 네가 만들어 준 거야 💡",
"결과물이 이 정도라니, 실망스러워 😔",
"네 코드 덕분에 장애 없이 배포됐다, 정말 고마워! 🌟",
]
print("\n=== 블랙기업 사장의 발언 예측 ===")
for statement in test_statements:
predict_reaction(statement)
🛠️ 코드 설명
🎈 Step 1: 데이터 준비
사장의 발언을 모아 "퇴사 발언"과 "계속 다닌다 발언"으로 나눕니다.
- 예: "네가 못해서 팀 전체가 고생하는 거야 💻🐛" -> 퇴사
- 예: "네 코드 덕분에 장애 없이 배포됐다 🌟" -> 계속 다닌다
🎈 Step 2: 모델 구성
- Embedding: 텍스트를 숫자로 변환해 컴퓨터가 이해하도록 합니다.
- LSTM: 문맥과 패턴을 학습합니다.
- Dense: 0(퇴사)와 1(계속 다닌다)을 예측합니다.
🎈 Step 3: 학습 및 예측
모델에 데이터를 학습시키고, 새로운 문장을 입력하면 결과를 예측합니다.
🎉 결과 예시
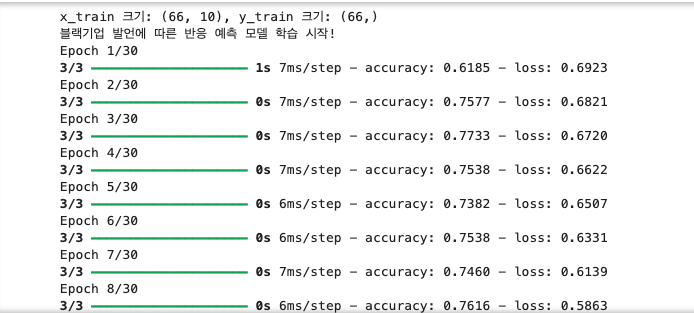
x_train 크기: (66, 10), y_train 크기: (66,)
블랙기업 발언에 따른 반응 예측 모델 학습 시작!
Epoch 1/30
3/3 ━━━━━━━━━━━━━━━━━━━━ 1s 7ms/step - accuracy: 0.6185 - loss: 0.6923
Epoch 2/30
3/3 ━━━━━━━━━━━━━━━━━━━━ 0s 7ms/step - accuracy: 0.7577 - loss: 0.6821
Epoch 3/30
3/3 ━━━━━━━━━━━━━━━━━━━━ 0s 7ms/step - accuracy: 0.7733 - loss: 0.6720
Epoch 4/30
3/3 ━━━━━━━━━━━━━━━━━━━━ 0s 7ms/step - accuracy: 0.7538 - loss: 0.6622
Epoch 5/30
3/3 ━━━━━━━━━━━━━━━━━━━━ 0s 6ms/step - accuracy: 0.7382 - loss: 0.6507
Epoch 6/30
3/3 ━━━━━━━━━━━━━━━━━━━━ 0s 6ms/step - accuracy: 0.7538 - loss: 0.6331
Epoch 7/30
3/3 ━━━━━━━━━━━━━━━━━━━━ 0s 7ms/step - accuracy: 0.7460 - loss: 0.6139
Epoch 8/30
3/3 ━━━━━━━━━━━━━━━━━━━━ 0s 6ms/step - accuracy: 0.7616 - loss: 0.5863
Epoch 9/30
3/3 ━━━━━━━━━━━━━━━━━━━━ 0s 7ms/step - accuracy: 0.7655 - loss: 0.5577
Epoch 10/30
3/3 ━━━━━━━━━━━━━━━━━━━━ 0s 6ms/step - accuracy: 0.7577 - loss: 0.5363
Epoch 11/30
3/3 ━━━━━━━━━━━━━━━━━━━━ 0s 6ms/step - accuracy: 0.7460 - loss: 0.5103
Epoch 12/30
3/3 ━━━━━━━━━━━━━━━━━━━━ 0s 6ms/step - accuracy: 0.7460 - loss: 0.4824
Epoch 13/30
3/3 ━━━━━━━━━━━━━━━━━━━━ 0s 7ms/step - accuracy: 0.7616 - loss: 0.4379
Epoch 14/30
3/3 ━━━━━━━━━━━━━━━━━━━━ 0s 6ms/step - accuracy: 0.7616 - loss: 0.3960
Epoch 15/30
3/3 ━━━━━━━━━━━━━━━━━━━━ 0s 6ms/step - accuracy: 0.7772 - loss: 0.3440
Epoch 16/30
3/3 ━━━━━━━━━━━━━━━━━━━━ 0s 6ms/step - accuracy: 0.7460 - loss: 0.3336
Epoch 17/30
3/3 ━━━━━━━━━━━━━━━━━━━━ 0s 6ms/step - accuracy: 0.7616 - loss: 0.2884
Epoch 18/30
3/3 ━━━━━━━━━━━━━━━━━━━━ 0s 6ms/step - accuracy: 0.7807 - loss: 0.2644
Epoch 19/30
3/3 ━━━━━━━━━━━━━━━━━━━━ 0s 6ms/step - accuracy: 0.8190 - loss: 0.2405
Epoch 20/30
3/3 ━━━━━━━━━━━━━━━━━━━━ 0s 7ms/step - accuracy: 0.9001 - loss: 0.1967
Epoch 21/30
3/3 ━━━━━━━━━━━━━━━━━━━━ 0s 6ms/step - accuracy: 0.9421 - loss: 0.1778
Epoch 22/30
3/3 ━━━━━━━━━━━━━━━━━━━━ 0s 6ms/step - accuracy: 0.9614 - loss: 0.1635
Epoch 23/30
3/3 ━━━━━━━━━━━━━━━━━━━━ 0s 6ms/step - accuracy: 1.0000 - loss: 0.1551
Epoch 24/30
3/3 ━━━━━━━━━━━━━━━━━━━━ 0s 6ms/step - accuracy: 1.0000 - loss: 0.1333
Epoch 25/30
3/3 ━━━━━━━━━━━━━━━━━━━━ 0s 6ms/step - accuracy: 1.0000 - loss: 0.1228
Epoch 26/30
3/3 ━━━━━━━━━━━━━━━━━━━━ 0s 6ms/step - accuracy: 1.0000 - loss: 0.1208
Epoch 27/30
3/3 ━━━━━━━━━━━━━━━━━━━━ 0s 6ms/step - accuracy: 1.0000 - loss: 0.1122
Epoch 28/30
3/3 ━━━━━━━━━━━━━━━━━━━━ 0s 6ms/step - accuracy: 1.0000 - loss: 0.0952
Epoch 29/30
3/3 ━━━━━━━━━━━━━━━━━━━━ 0s 7ms/step - accuracy: 1.0000 - loss: 0.0988
Epoch 30/30
3/3 ━━━━━━━━━━━━━━━━━━━━ 0s 6ms/step - accuracy: 1.0000 - loss: 0.0868
=== 블랙기업 사장의 발언 예측 ===
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 63ms/step
'네가 만든 UI는 사용자 경험을 망치고 있어 📉' => 직원 반응: 퇴사 (점수: 0.00)
이 회사, 더는 못 참겠다! 당장 퇴사합니다! 🏃♀️
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 14ms/step
'이 프로젝트는 네가 아니면 불가능했어 🏆' => 직원 반응: 퇴사 (점수: 0.02)
이 회사, 더는 못 참겠다! 당장 퇴사합니다! 🏃♀️
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 14ms/step
'잠은 죽어서 자도 충분해' => 직원 반응: 계속 다닌다 (점수: 0.64)
사장님, 충성을 다하겠습니다! 🙇♂️
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 13ms/step
'회사의 핵심 기술은 네가 만들어 준 거야 💡' => 직원 반응: 계속 다닌다 (점수: 0.76)
사장님, 충성을 다하겠습니다! 🙇♂️
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 13ms/step
'결과물이 이 정도라니, 실망스러워 😔' => 직원 반응: 퇴사 (점수: 0.02)
이 회사, 더는 못 참겠다! 당장 퇴사합니다! 🏃♀️
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 14ms/step
'네 코드 덕분에 장애 없이 배포됐다, 정말 고마워! 🌟' => 직원 반응: 퇴사 (점수: 0.00)
이 회사, 더는 못 참겠다! 당장 퇴사합니다! 🏃♀️
📢 텐서플로우로 AI를 시작하세요!
텐서플로우는 복잡해 보이지만, 이렇게 재미있고 간단한 프로젝트로 시작하면 누구나 쉽게 접근할 수 있어요. 😊
오늘은 "블랙기업 사장 AI"를 만들었지만, 여러분만의 창의적인 아이디어를 텐서플로우로 실현해 보세요! 💻✨
💬 여러분의 생각은? 댓글로 AI 만들기 도전을 공유해주세요! 🙌
🔥 "좋아요"와 "공유"로 더 많은 개발자들에게 이 프로젝트를 알려주세요!
