2022, Rethinking Audio-Visual Synchronization for Active Speaker Detection [MLSP]
Active Speaker Detection (ASD)
Abstract
Problem
- Existing research lacks a clear definition of active speakers
- Fail to model audio-visual synchronization and often classify unsynchronized videos as active speaking
Proposal
- New definition that requires synchronization between audio and visual speaking activities
- Cross-modal contrastive learning strategy
- Positional encoding in attention modules for supervised ASD models to leverage the synchronization cue
Experimental results
- Model can successfully detect unsynchronized speaking as not speaking, addressing the limitation of current models
1. Introudction
Importance of active speaker detection (ASD)
- ASD is crucial for various downstream tasks such as speaker recognition, speaker diarization, speech separation, and human-computer interaction
Problem
- No consistent definition of active speakers in the literature
- with some studies requiring synchronized speaking signals from the same person in both audio and visual modalities
- while others allow non-synchronized signals from different but related persons
- (e.g., Dubbed movies)
Audio-visual synchronization
- Aligns with the definition in the Active Speakers in the Wild (ASW) dataset [ref]
- Requiring audio-visual synchronization is more practical than not requiring
- Dubbed movies (translated movies or documentaries with a narrator)
- Challenging to determine which person should be considered speaking in the video
- Which person should be considered speaking in the video, the person shown in the visual scene, the unseen narrator, or both?
- What degree of relevance should be used in the definition of active speakers?
- ⇒ It is clear whether audio and visual speaking signals are synchronized or not.

- Challenging to determine which person should be considered speaking in the video
-
If the signals are not synchronized, there are generally two cases
(1) Mismatch
- The audio and the face track do not correspond to the same speaking content
(2) Misalignment
- The content and identity are the same for audio and face tracks, but one modality is delayed
-
Perceptual studies that suggest delays become detectable by ordinary people if they are greater than 125ms for audio delay and 45ms for visual delay.
Proposal
- Use cross-modal contrastive learning
- Apply positional encoding in an attention module when fusing audio and visual embeddings
- can temporally align
- Perform better on synthesized unsynchronized videos along with natural videos.
2. Related Work
Active Speaker Detection
- Utilizing the audio-visual correlation in videos
- “Look who’s talking: Speakerm detection using video and audio correlation,” in Proc. ICME, 2000
- “Audio-visual speaker localization via weighted clustering,” in Proc. MLSP, 2014
- Improving the modality encoding method
- Naver at ActivityNet Challenge 2019–task B active speaker detection (AVA)
- Focus on the fusion method or leverage context
- UniCon: Unified context network for robust active speaker detection, in Proc. ACM Multimedia, 2021
- How to design a three-stage architecture for audio-visual active
speaker detection in the wild,” in Proc. ICCV, 2021
⇒ none of the existing methods explicitly model audio-visual synchronization
Audio-Visual Synchronization
- Owens and Efros [14]
- Learn audio and visual representations using audio-visual synchronization cues in a self-supervised way
- Chung and Zisserman [15]: "Out of time: automated lip sync in the wild" in Proc. ACCV, 2016 (github)
- SyncNet to detect the synchronization between lip movement and speech
- Kim et al. [5]: “Look who’s talking: Active speaker detection in the wild,” in Proc. Interspeech, 2021 (github)
- Self-supervised learning with SyncNet for ASD and achieved promising performance.
- Ding et al. [16]
- Dynamic triplet loss and multinomial loss for self-supervised audio-visual synchronization learning.
- Chen et al. [17]
- Studied synchronization in an in-the-wild setting
- Other domain
- Audio-visual speech separation [18]
- Speech-driven talking face generation [19]
- Lip to speech synthesis [20]
3. Case study
Two research questions
(1) Can current models correctly label unsynchronized videos as "Not Speaking"?
(2) What do current models really learn?
Problem of exsisting model
- Current models tend to make false-positive predictions on unsynchronized videos, they fail to detect unsynchronized videos as "Not Speaking.
3.1. Unsynchronization test by augmentation
Create unsynchronized video segments (mismatched and misaligned) from original test videos
- both the AVA validation set and the ASW test set
- unsynchronized videos take different proportions but have the same total number of videos
1) Mismatched video segments
- How to make?
- Randomly swapping the audio of speaking segments of the original videos
- For each face track, replace the audio of each speaking segment with another random speaking segment from different videos
- Randomly swapping the audio of speaking segments of the original videos
- Show lip movements in the video and speaking voices in the audio, but these activities do not match
- ASD labels are set as negatives
2) Misaligned video segments
- How to make?
- Shifting the original audio of speaking segments in time
- Randomly shift the speaking segment's original audio to the left or right by a time shift greater than 125ms, the human detectable threshold of any delay
- Shifting the original audio of speaking segments in time
Performance on existing research
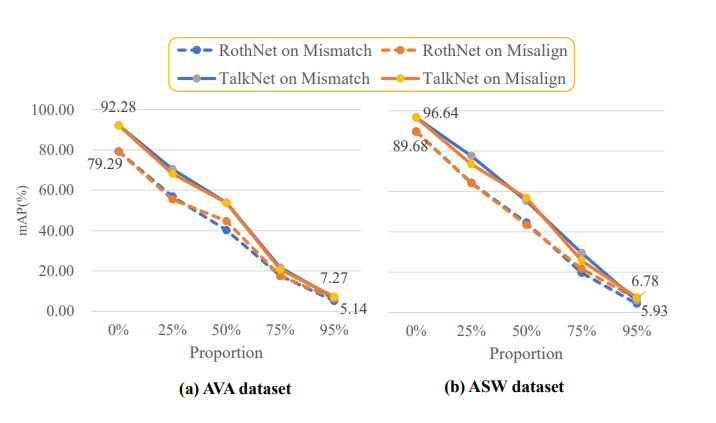
- Performance with five different proportions of unsynchronized videos
- Both models do not properly model audio-visual synchronization
- Hypothesis
- Rely on individual modality features and basic audio-visual correlations to classify videos
- Ignore the synchronization cue
3.2. Understanding what existing ASD models learn
What existing ASD models learn?
- Remove key information from audio and visual tracks
-
Silencing the audio tracks
-
Masking the bottom 30% of visual frames of each face track with zero to cover the lips
Performance on existing research
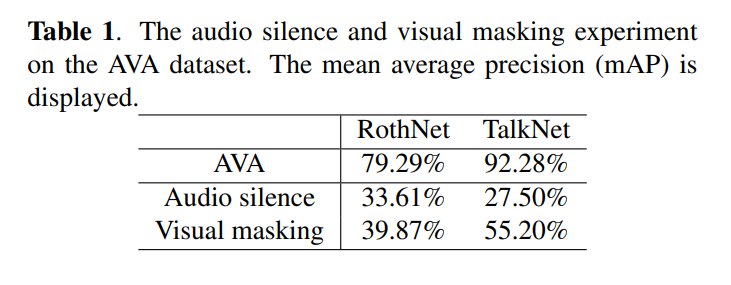
-
Both RothNet and TalkNet deteriorate dramatically in both cases
- Showing that both models use voice activity and lip movement information for ASD
-
Combined model
- Then, the authors train a voice activity detection (VAD) model and a lip movement detection model modified from the audio and visual frontends of TalkNet
- The probability of speaking is calculated as the product of the probabilities predicted by the two models
- The combined model's mAP in the AVA val set is 90.72%, close to that of TalkNet, indicating that using only a VAD and a lip movement detection model is able to perform comparably with the SoTA ASD models
4. Method
4.1. Cross-modal contrastive learning
Objective
- To address the lack of unsynchronized data in the training dataset
Method
- Augment the features in the embedding space to enforce contrastive learning
- Positive samples (Sets: )
- at lest one
- Negative samples
- Randomly exchanging the audio embeddings of a face track with audio embeddings of another positive sample
- and are indexes of two randomly selected face tracks from , and is different from
- Mathematically, the additional contrastive samples are , where .
- We only use the face tracks which contain positive frames for contrastive learning
- Randomly exchanging the audio embeddings of a face track with audio embeddings of another positive sample
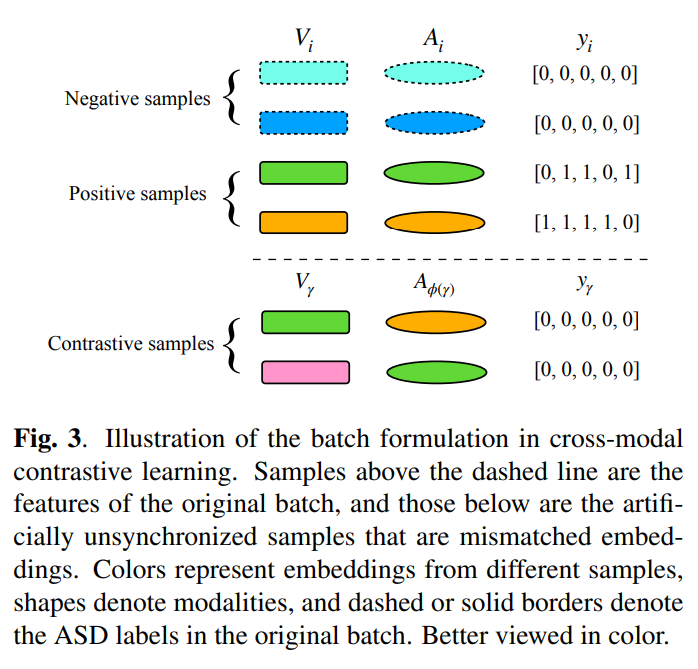
Loss
Experiment
- Augmented training set only contains mismatched videos as negative samples
- Demonstrate that such trained models are able to handle not only mismatched videos but also misaligned videos during inference
4.2. Model architecture: Sync-TalkNet
- This section describes the model architecture used in the proposed method.
- The Sync-TalkNet architecture is based on the TalkNet model and consists of two frontends:
- a visual frontend and an audio frontend
- The visual frontend takes the RGB face frames of face track i as input,
- The audio frontend ingests the Mel-frequency cepstral coefficient (MFCC) vectors computed from the corresponding audio signals of face track i.
- a visual frontend and an audio frontend
- The backend makes predictions of speaking probability in every video frame
- the visual and audio embeddings through several attention modules
-
-
-
The cross-modal features are computed with cross-attention module, where and are concatenated and passed through the self-attention layer.
-
- the visual and audio embeddings through several attention modules
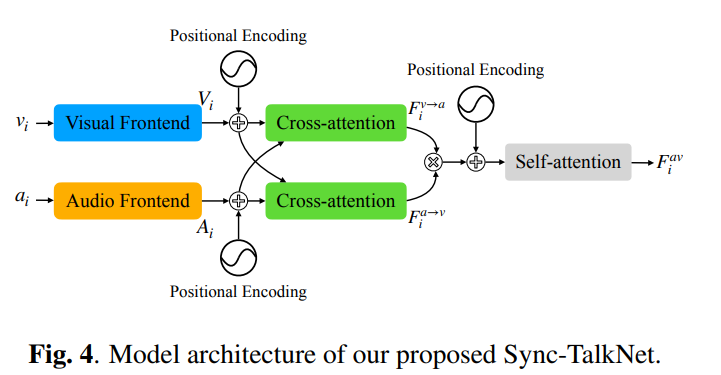
Positional Encoding (PE)
- The proposed method adds positional encoding to the attention modules to leverage synchronization cues.
- Without the positional encoding, the cross-attention layer is permutation-invariant for the
inputs, which makes it difficult for the model to learn the synchronization between visual and audio
5. Experiment
5.1 Performance of the proposed method
Unsynchroinzation test
-
The results show that Sync-TalkNet and Sync-RothNet outperform the two baseline models, RothNet and TalkNet, in the augmented test sets.

-
Sync-TalkNet achieves better results than TalkNet on the ASW test set and slightly lower results on the AVA val set.
-
The proposed method leverages both the advantages of supervised and self-supervised ASD models, achieving excellent performance on both original and unsynchronized augmented datasets.
Narrated videos detection.
-
Trained on the ASW dataset, to detect unsynchronized dubbed movies in the AVA validation set
-
True positive rate (TPR)
- the ratio of positively predicted frames to positively labeled frames
- lower TPR indicates the more likely the video is from a dubbed movie.

- Manual checking confirmed that the three videos with the lowest TPR are dubbed movies, while the three with the highest TPR are not dubbed movies.
- Suggests that Sync-TalkNet may be useful for detecting unsynchronized dubbed videos
5.2 Ablation study
The effects of positional encoding and cross-modal contrastive learning
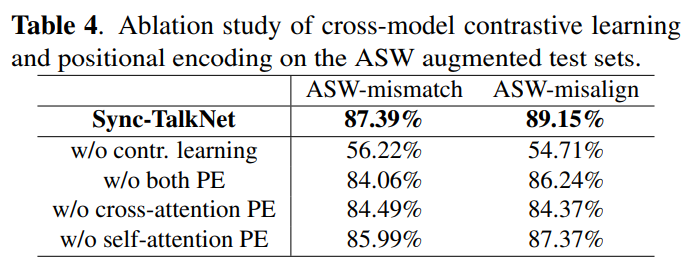
- Cross-modal contrastive learning is crucial for learning synchronization
- Removing positional encoding causes a performance drop, but not a catastrophic one
- As the model can still learn weak timeline information with the guidance of contrastive learning
- Impact of applying positional encoding on both cross-attention and self-attention modules, with results indicating that doing so helps Sync-TalkNet better perceive timeline information
