
Passage Retrieval
passage retrieval이란 query에 맞는 passage를 찾는 것이다. NLP에서 Open-domain QA 분야는 대규모 문서 중 질문에 맞는 답을 찾는 task를 수행한다. 이때 model 2가지가 사용될 수 도 있다.
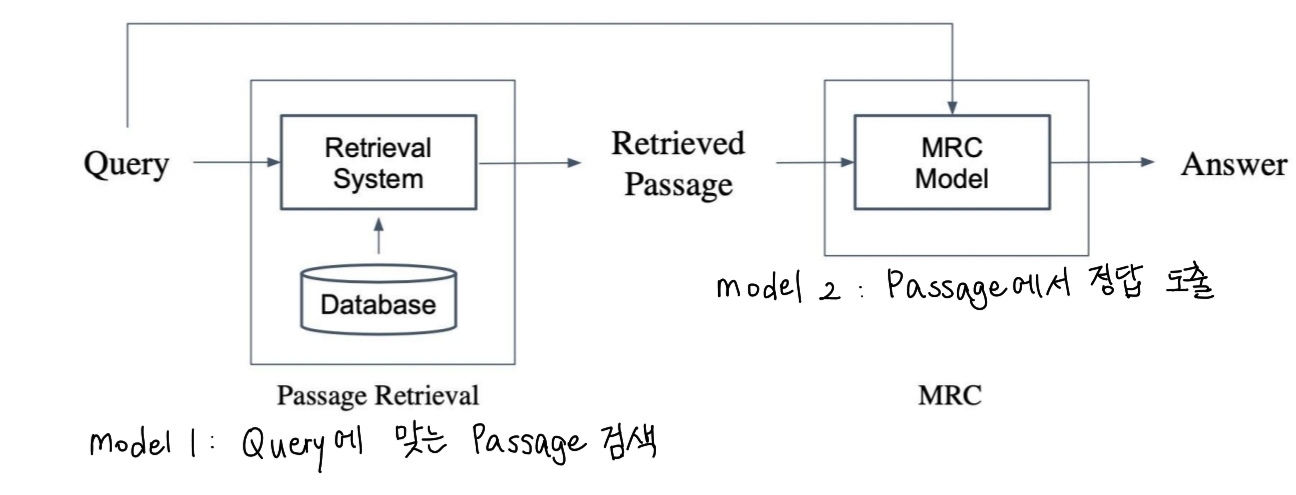
위와 같이 passage를 찾는 model과 passage에서 답을 찾는 model이 존재한다.
TF-IDF
컴퓨터는 글자를 읽지 못한다. 즉 모든 정보는 숫자로 vector화 해야한다. passage retrieval도 마찬가지이다.
먼저, 여러 passage들을 vector space에 embedding 한다. 그 후, query의 embedding vector와 해당 passage들의 거리를 코사인 유사도 등의 알고리즘으로 계산이 가능하다. 여기서 embedding의 방법으로 sparse embedding과 dense embedding이 존재한다.
-
sparse embedding
- 단어, 문장, 또는 문서를 매우 큰 차원 공간에서 표현 (dim=vocab size)
- 대부분의 차원 값이 0인 벡터로 표현
- 단순한 문법적 특징 catch
- 정확히 단어가 일치해야 해서 유의어에 취약
- ex) Bag of Words (BoW), TF-IDF, One-hot encoding
-
dense embedding
- 단어, 문장, 문서를 상대적으로 낮은 차원의 벡터 공간에서 표현
- 각 차원 값들이 모두 중요한 정보를 포함한 실수값을 가짐
- Word2Vec, GloVe, BERT, Transformers 등 모델 사용
- 단어 간의 유사성을 잘 반영하여 문맥이나 의미를 학습
- 학습이 필요한 임베딩이므로 대규모 데이터가 필요
TF-IDF
- Term Frequency(TF): 단어의 등장빈도
- Inverse Docuent Frequncy(IDF): 단어가 제공하는 정보의 양
을 의미한다.
It was the best of times
위의 문장의 경우 It was the 는 다른 문서나 문장에서도 자주 등장하는 단어인데, best,times는 그렇지 않기 때문에 더 많은 정보를 제공하는 것으로 여긴다.
- Term Frequency(TF)
문서 내 단어의 등장빈도이다.
- 실제로 count하기
- 문서 길이에 맞게 조정하기 (count/num words)
- binary나 log 정규화 한 값으로 매김
- Inverse Docuent Frequncy(IDF)
IDF는 단어가 제공하는 정보의 양을 의미한다. 따라서 얼마나 많은 문서에 등장했는지가 IDF값을 의미한다.
여기서 는 t라는 단어가 등장한 문서의 수를 의미한다. N은 총 문서의 수이다. 따라서, 모든 문서에 t라는 단어가 등장하면 해당 단어의 IDF 값은 0이 된다. (log1=0)
- TF-IDF
이제 최종적으로 두 값을 곱하게 되면 바로 TF-IDF 값이된다. 한 문서에 여러번 등장해서 TF값이 높더라도 여러 문서에 등장하는 단어라면 0에 가까운 값을 가지게된다.

위의 예시가 있다고 생각해보자
- TF

binary 값으로 실제 등장한 단어들에 대해 count하면 위와 같은 결과가 나온다.
- IDF

모든 문서에서 등장하는 단어는 0의 값을 가지는 것을 알 수 있다.
- TF-IDF

최종적으로 두값을 곱하게 되면 각 문서마다(row단위) vector화 된 표현이 가능해진다.
TF-IDF retrieval
사용자가 질의를 하게 되면 이제 동일한 방법으로 embedding하여 문서들의 TF-IDF값을 곱하여 유사도를 계산할 수 있다.
- 사용자가 입력한 질의 토큰화
- vocab에 없는 단어 제거
- 질의 하나의 문서로 생각해 TF-IDF값 계산
- 질의 TF-IDF와 문서 TF-IDF 값 유사도 계산
- ranking
이를 통해서 제일 질문과 유사한 의미를 가지는 passage를 불러오는 것이다.
BM25
TF-IDF는 한개의 문서가 길이가 너무 길어진다면 TF값들이 커지는 한계가 존재한다. 이를 극복하기 위한 방법이 BM25 알고리즘이다.
BM25는 TF-IDF 개념을 바탕으로 문서의 길이까지 고려해서 점수를 매긴다. TF 값에 한계를 지정해두어 일정한 범위를 유지하도록 하는 것이다. 평균적인 문서의 길이보다 더 작은 문서에 단어가 매칭된 경우 가중치를 부여하는 방식으로 수행한다.
- : 쿼리
- : 문서
- : 문서 에서 의 등장 횟수
- : 문서 의 길이(단어수)
- : 전체 문서의 평균 길이
- : BM25의 조정 매개변수
- : 용어 의 역문서빈도
위의 BM25 수식은 아래로 이루어져 있다. 먼저 IDF값에 대한 수식부터 살펴보자면,
IDF 수식
IDF는 자주 등장하는 단어에 대한 가중치를 낮추고 드물게 등장하는 단어에 더 높은 가중치를 부여한다. 위의 수식으로 BM25에서는 IDF값을 정한다.
TF 보정
- 은 조정 매개변수로 1.2~2 사이 값을 가진다
- TF의 과도한 영향 막기 위해서 TF값이 너무 커지지 않게 조정해주는 부분이다.
문서길이에 따른 보정
- 는 보정 매개변수로 문서 길이에 대한 민감도를 제어한다. 일반적으로 0.75 정도로 설정되고 값이 작을 수록 문서의 길이를 고려하지 않는 것이다.
- 길이가 긴 문서는 많은 단어를 포함할 가능성이 크지만, 쿼리와 관련있다고 단정 짓기는 힘들기 때문에 길이에 따른 편향을 상쇄하기 위해 보정하는 것이다.
실제로 BM25는 검색엔진에서도 아직 유용하게 사용된다고 한다.
