
Extraction QA pytorch
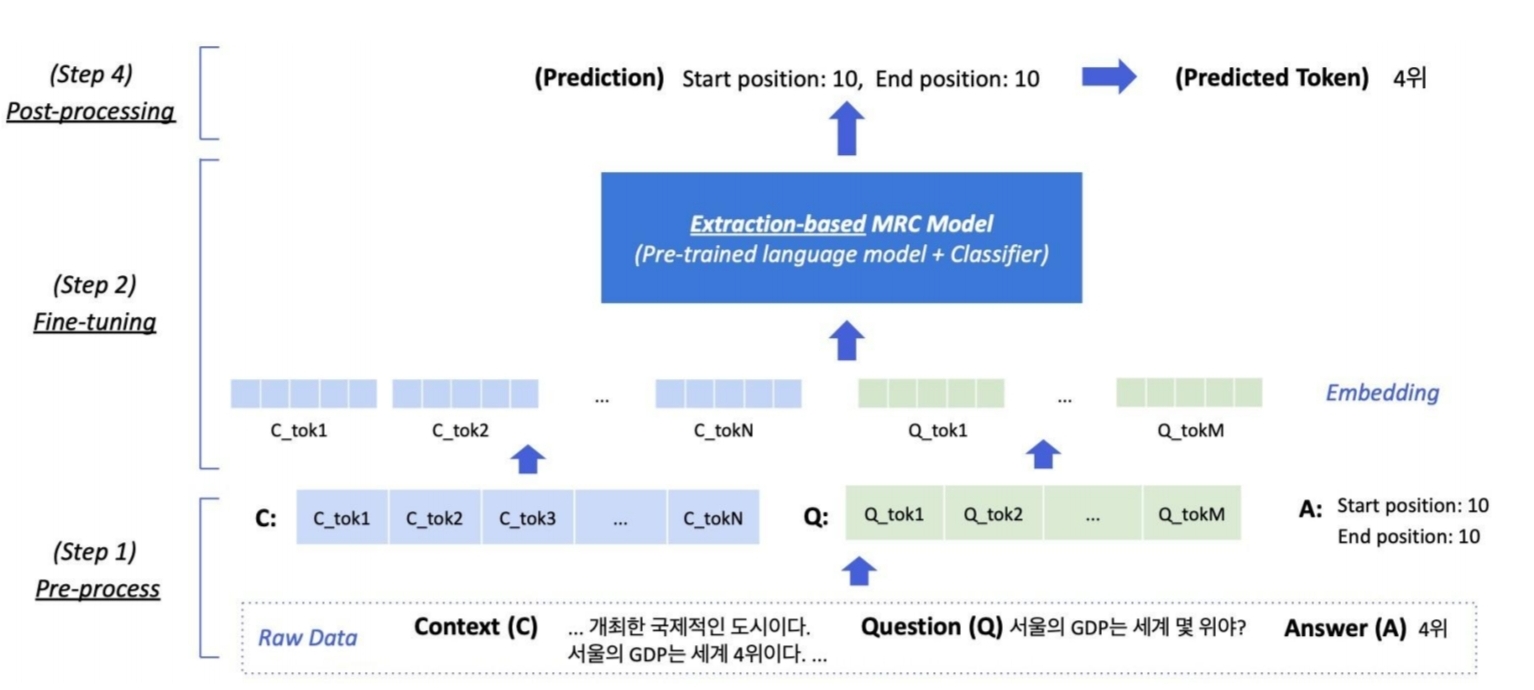
위는 Extractive QA의 flow이다. Raw data에서 context와 question 토큰화 한 후 MRC Model에 입력한다. code로는 아래와 같이 작성한다.
from transformers import AutoModelForQuestionAnswering, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("ainize/klue-bert-base-mrc")
model = AutoModelForQuestionAnswering.from_pretrained("ainize/klue-bert-base-mrc")
context="'근대적 경영학' 또는 '고전적 경영학'에서 현대적 경영학으로 전환되는 시기는 1950년대이다. 2차 세계대전을 마치고, 6.25전쟁의 시기로 유럽은 전후 재건에 집중하고, 유럽 제국주의의 식민지가 독립하여 아프리카, 아시아, 아메리카 대륙에서 신생국가가 형성되는 시기였고, 미국은 전쟁 이후 경제적 변화에 기업이 적응을 해야 하던 시기였다. 특히 1954년 피터 드러커의 저서 《경영의 실제》는 현대적 경영의 기준을 제시하여서, 기존 근대적 인사조직관리를 넘어선 현대적 인사조직관리의 전환점이 된다. 드러커는 경영자의 역할을 강조하며 경영이 현시대 최고의 예술이자 과학이라고 주장하였고 , 이 주장은 21세기 인사조직관리의 역할을 자리매김했다.\n\n현대적 인사조직관리와 근대 인사조직관리의 가장 큰 차이는 통합이다. 19세기의 영향을 받던 근대적 경영학(고전적 경영)의 흐름은 기능을 강조하였지만, 1950년대 이후의 현대 경영학은 통합을 강조하였다. 기능이 분화된 '기계적인 기업조직' 이해에서 다양한 기능을 인사조직관리의 목적, 경영의 목적을 위해서 다양한 분야를 통합하여 '유기적 기업 조직' 이해로 전환되었다. 이 통합적 접근방식은 과정, 시스템, 상황을 중심으로 하는 인사조직관리 방식을 형성했다."
question="현대적 인사조직관리의 시발점이 된 책은?"
encodings = tokenizer(context,question,max_length=512, truncation=True,padding="max_length",return_token_type_ids=False)encoding값을 구하는 과정에서 context와 question을 동시에 인자로 넣어 tokenizer를 실행하는 것을 알 수 있다.
model 을 출력해서 import한 pre-trained model의 구조를 살펴보자
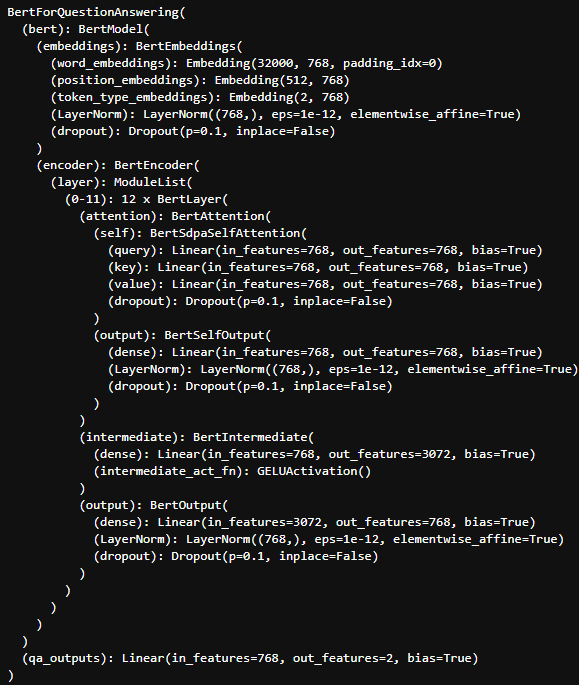
qa_outputs이라는 linear layer를 추가해 token마다 768 size로 embedding되는 결과를 2개의 output으로 선형변환하는 것을 알 수 있다.
encodings = tokenizer(context, question, max_length=512, truncation=True,
padding="max_length", return_token_type_ids=False)
encodings = {key: torch.tensor([val]) for key, val in encodings.items()}
input_ids = encodings["input_ids"]
attention_mask = encodings["attention_mask"]
pred = model(input_ids, attention_mask=attention_mask)tokenizer를 통해서, input_ids와 attention_mask를 얻는다. 여기서, token_type_ids는 필요없기 때문에 따로 반환하지 않는다. 최종적으로 model에 두 값을 입력해서 추론을 진행한다.
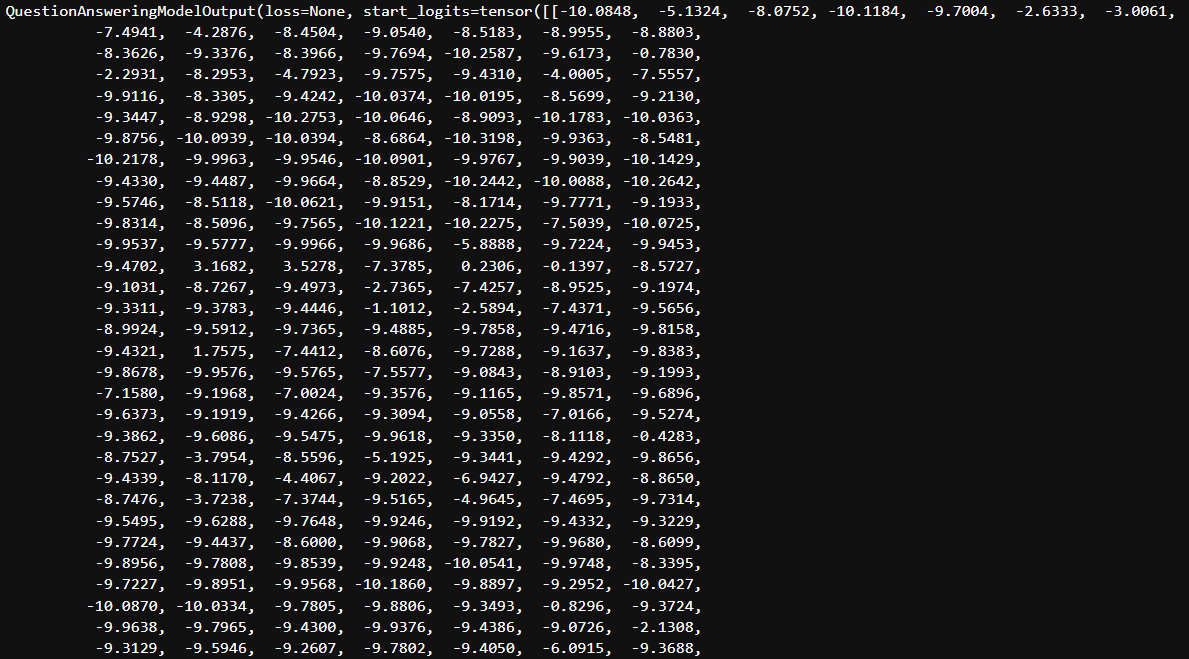
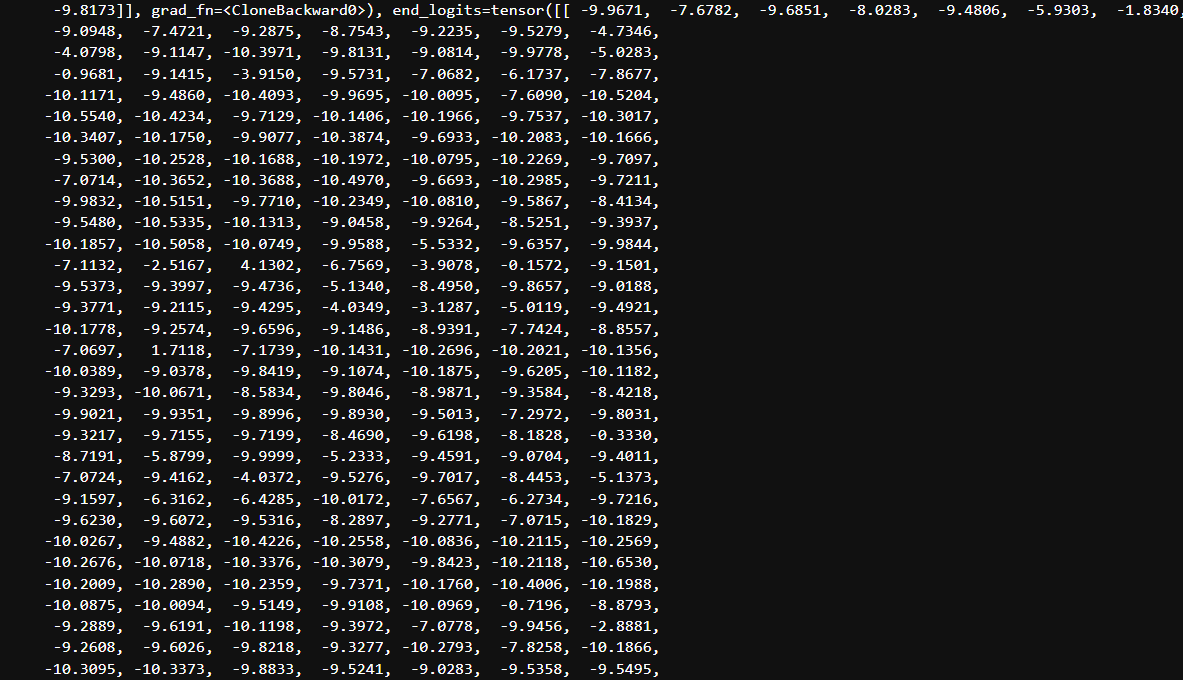
위와 같이 pred의 결과는 start_logits과 end_logits의 tensor를 반환한다.
print(pred['start_logits'].size())
실제로, start_logits의 tensor size를 출력해보면, [1,512] 로 이는 문장 최대길이인 max_length=512에서의 각 token에 대한start_logits 값들이다. 즉, 각 index는 token들을 의미하게 된다.
start_logits, end_logits = pred.start_logits, pred.end_logits
token_start_index, token_end_index = start_logits.argmax(dim=-1), end_logits.argmax(dim=-1)최종적으로, context 내 start index값과 end index값을 argmax를 통해서 추출하게 된다.
token_start_index와 token_end_index는 모두 context내 answer span index를 가지게 된다.
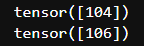
pred_ids = input_ids[0][token_start_index: token_end_index + 1]input_ids는 tokenizer를 통해서 구한 값이고, index에 해당하는 단어들의 embedding 값들을 가져올 수 있다. 이를 다시 단어로 decode하면 context내 단어를 예측하는 것이다.
내가 진행한 예시는 pred_ids는 아래와 같은 결과값을 가졌다.

이를 그대로 decode하게 되면 context 내 answer를 출력할 수 있다.
prediction = tokenizer.decode(pred_ids)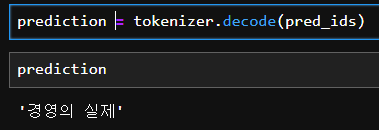
정답은 경영의 실제임을 확인할 수 있었다.
Reference
