
CNN
CNN은 Convolutional Neural Network의 약자로, 영상에서 객체, 클래스, 범주인식을 위한 패턴을 찾을때 사용되는 딥러닝(데이터로부터 직접 학습함) 모델이다. 오디오, 시계열과 같은 신호 데이터를 분류할 때도 효과적이다.
주요 구성 요소
Convolutional layer
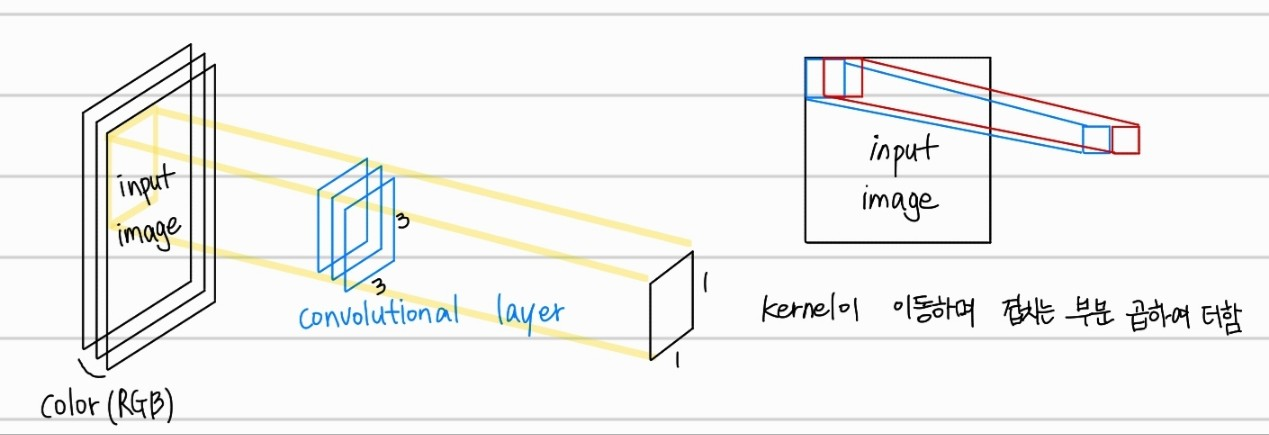
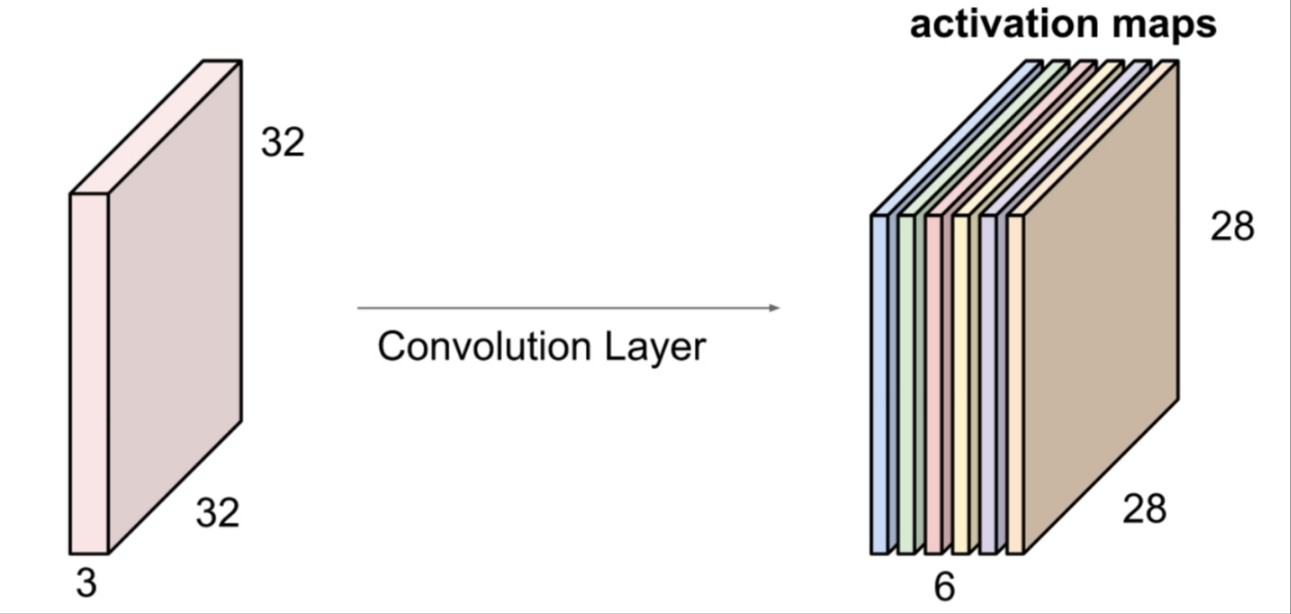
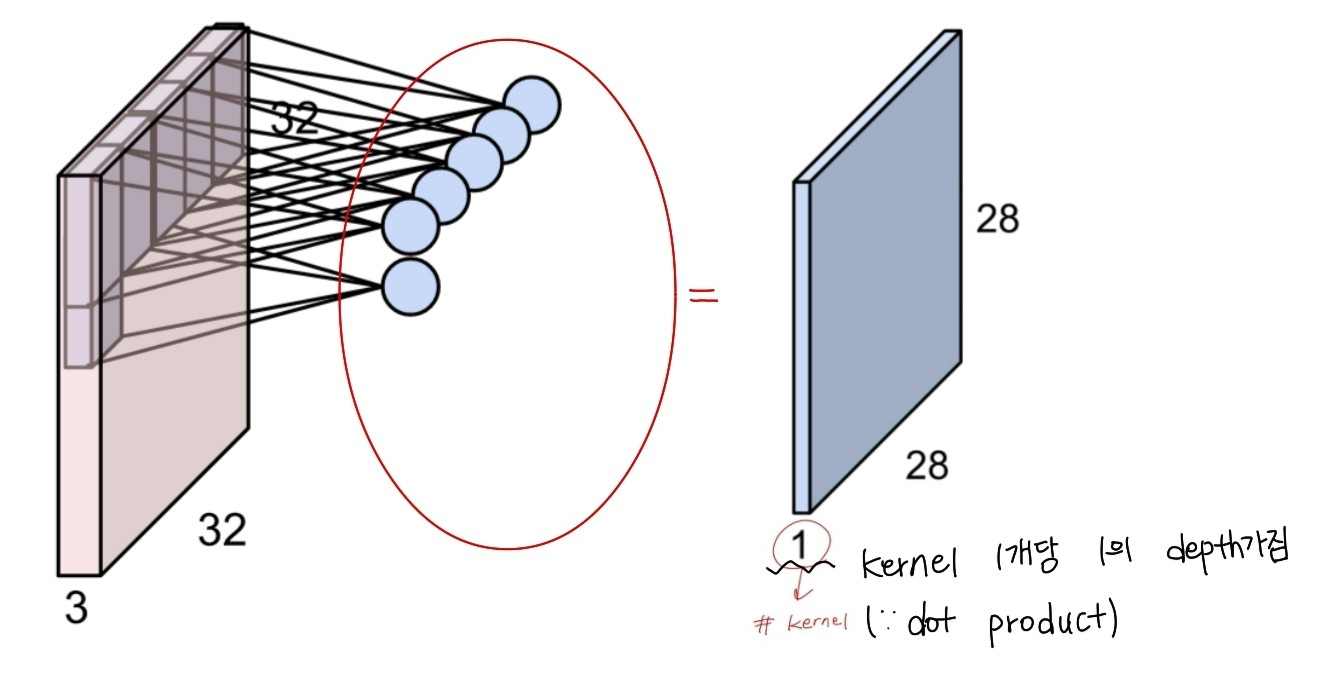
이미지의 특징을 추출하는 계층이다. 각 필터는 다양한 특징인 선,모서리,질감 등을 감지할 수 있게 학습된다. kernel의 갯수만큼의 convolutional layer의 출력값의 channel이 정해진다. 위의 사진은 5x5x3 의 kernel을 6개 사용한 결과이다.
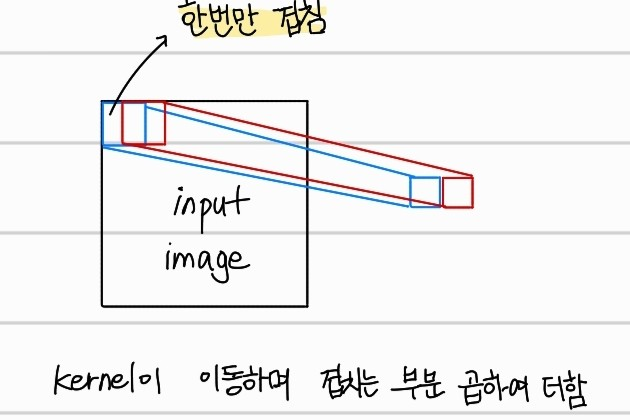
input image와 kernel이 겹친 부분을 stride만큼 이동하며 겹친 부분들의 내적을 output으로 가진다.출력된 한 channel당 width와 height는
위의 수식을 만족한다.
Padding
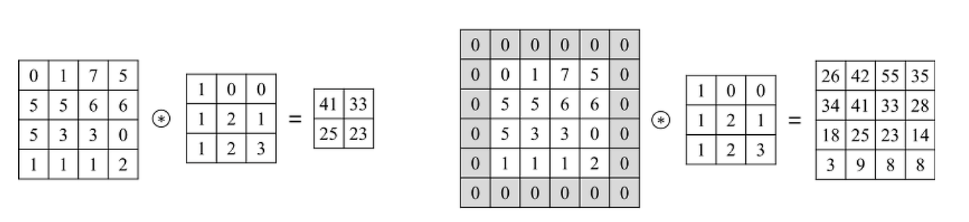
위의 계산과정에서 알 수 있듯이, convolutional layer를 지날 수록, 출력 이미지의 크기가 점점 작아지게 된다. 또한, 가장자리에 위치한 픽셀들의 정보는 점점 사라지게 된다. 따라서, 이미지의 가장 자리에 특정 값으로 설정된 픽셀들을 추가해 출력 이미지가 입력 이미지와 같거나 비슷하게 만드는 역할을 한다.
Zero-padding의 경우, 이미지 손실이 없는 것을 확인할 수 있다.
Fully Connected layer (완전 연결층)
CNN에서의 Fully Connected layer는 기본 NN의 FC layer와 매우 유사하다. 일단, Convolutional layer를 통과한 값은 이미지의 형태를 갖고 있기 때문에, flatten과정을 진행한 후, activation function을 통과하게끔 한다.
Pooling Layer
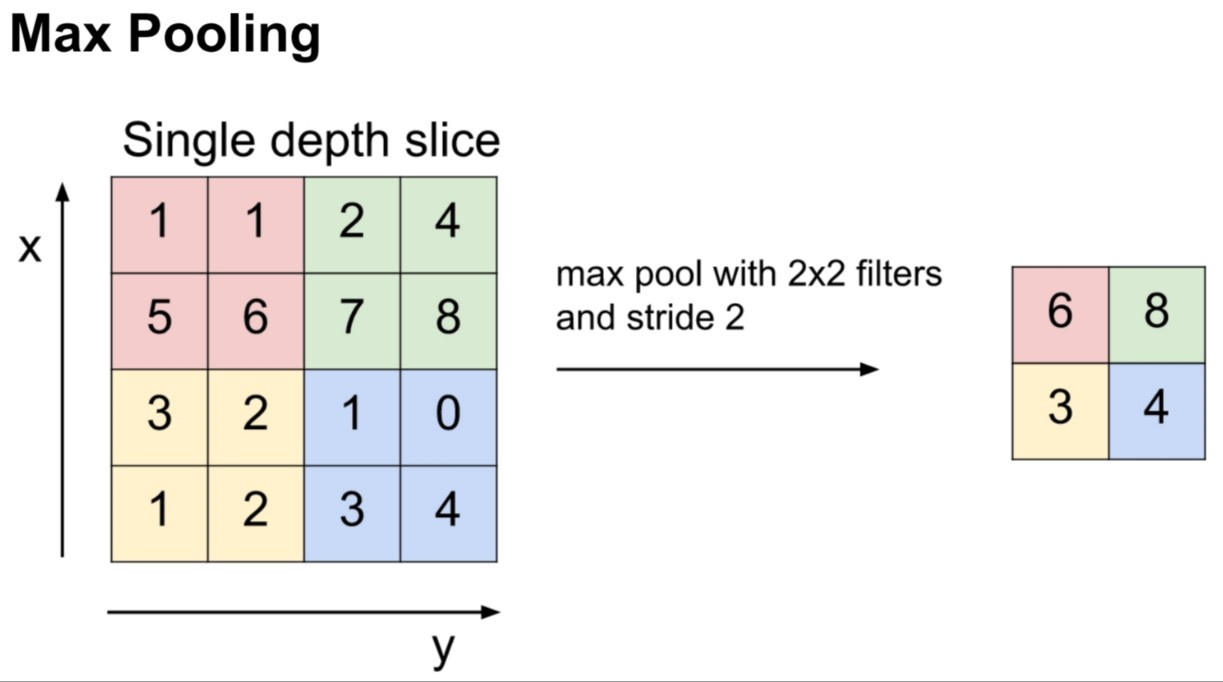
이미지의 크기를 유지하게 되면, Fully Connected layer로 연결할때, 연산량이 늘 수 있다. 따라서, 이미지를 적당한 크기로 줄이거나 키우는 layer로 특정 feature를 강조할 수 있도록 도와준다.
2x2 filter크기로 max pooling을 진행하면 위와 같이 된다. pooling kernel의 내부 픽셀들이 이동하거나 회전하더라도 같은 출력값을 가지게 된다.
1)이미지가 회전하거나 이동한 것에 대해서 강인하다.
2) CNN이 처리해야하는 이미지 크기가 줄어들어 딥러닝 모델의 파라미터 수가 감소하는 것도 학습시간을 절약하고, 오버피팅을 어느정도 완화할 수 있다.
Reference
https://kr.mathworks.com/discovery/convolutional-neural-network.html
https://rubber-tree.tistory.com/116
