
오늘은, 문장간 유사도를 계산하는데 사용되는 평가지표인 BERTScore에 대한 논문에 대해 공부한 내용을 정리해보았다.
❗Before Read ❗
- 완벽하게 순서대로 논문을 인용한 것이 아니고 부분부분 첨부하여 순서가 조금 다르거나 없는 부분이 있을 수 있습니다.
- 중간중간 제가 만든 예시가 있어, 적절한 예시가 아닐 수도 있습니다.
ABSTRACT

- BERTScore는 생성된 문장과 정답 문장 간 유사도 점수를 계산한다.
- contextual embeddings 사용해 계산한다.
- 변형된 문장(adversarial paraphrase)에도 강인하다.
기존 metric의 단점

- metric의 최종 목표는 생성된 문장과 정답 문장이 문맥 상 동일한지 평가하는 것이다.
- BLEU는 단순히, 겹친 단어의 수를 count한다.
→ 단어의 내재된 의미와 통사구조의 다양성을 제대로 평가하지 못한다.
BLEU / ROUGE (n-gram)
- BLEU (precision)
- translation 평가
- exact match count
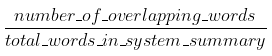
the cat was found under the bed (ref)
the cat was under the bed (can)
- ROUGE (recall)
- generation 평가
- exact match count
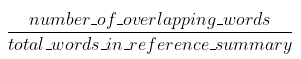
the cat was found under the bed (ref)
the cat was under the bed (can)
- n-gram
연속된 n개의 단어 또는 n개의 문자로 이루어진 text 조각
- Unigram (1-gram) the / cat / was / found / under / the / bed
- Bigram (2-gram) the cat / cat was / was under / under the / the bed
- Trigram (3-gram) the cat was / cat was under / was under the / under the bed
단점 1. 유의어 취약
people like foreign cars (ref)
people like visiting places abroad (can1)
consumers prefer imported cars (can2)
문맥을 파악하면 can2가 더 높은 점수여야 하지만, exact match한 단어 수가 적어 점수가 낮다.
단점 2. 문장 내 단어의 위치에 취약
- Distant dependencies
문장 내에서 멀리 떨어져 있는 단어들 간의 의존 관계를 제대로 파악하지 못할 수 있다.
The cat that the boy adopted last week is very playful (ref)
The cat / cat that / that the / the boy / boy adopted / adopted last / last week / week is ….
- Semantically-critical ordering changes
단어 순서가 바뀌어 의미가 크게 변한 문장을 잘 처리하지 못할 수 있다.
The chef cooked a delicious meal for the guests (ref)
The chef / chef cooked / cooked a / a delicious / delicious meal / meal for / for the / the guestsThe guests cooked a delicious meal for the chef (can)
The guests/ guests cooked / cooked a / a delicious / delicious meal / meal for / for the / the chef
많은 bigram이 일치해 거의 동일한 문장으로 판단할 수 있다. (진한 글씨만 다름)
BERTSCORE

- BERTSCORE는 비교문장의 token들의 embedding vector 간 cosine 유사도의 합으로 계산한다.
- contextualized token embeddings를 통해 유의어, 단어 위치에 대한 한계점 극복
계산과정
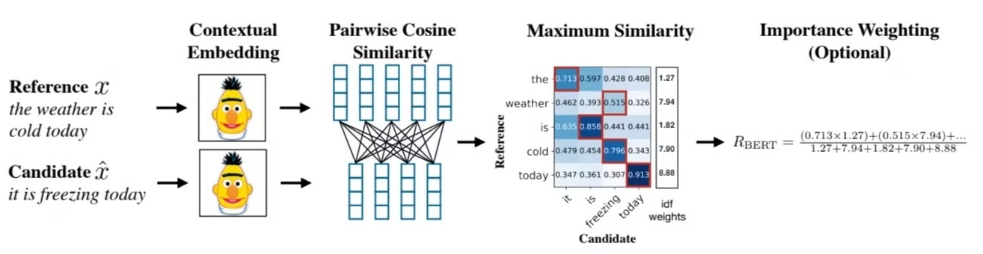
위의 과정으로 BERTSCORE는 계산된다. 차례대로 자세히 살펴보자
1. Token Representation

- ‘BERT’나 ‘ELMo’ 와 같은 모델로 “서로 다른 문장에서의 같은 단어” 를 vector화 할때, 해당 단어의 주위 단어들을 기반으로 생성한다.
- BERT 모델 기준 wordpiece 토큰화, transformer encoder로 계산된다.
- self-attention과 nonlinear transformations 반복
2. Similarity Measure
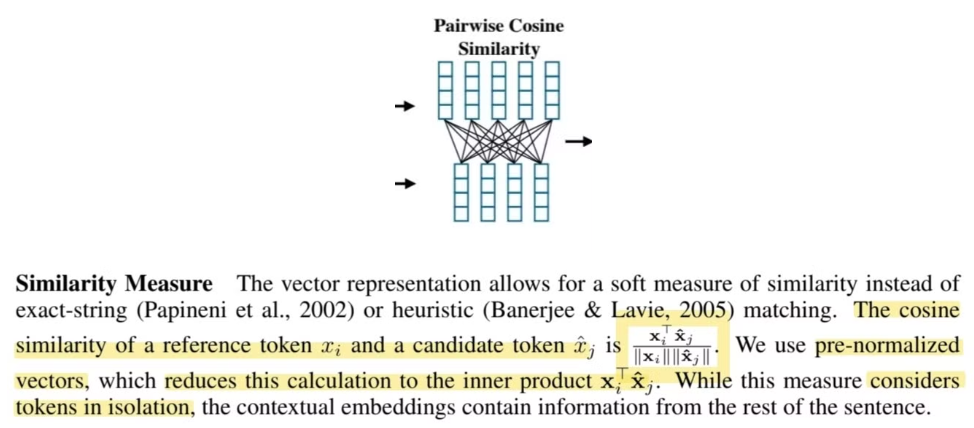
정확한 단어 일치나, 휴리스틱한 매칭이 아닌 cosine 유사도를 계산한다.
정답인 token 와 예측한 token 간 유사도는 아래와 같다.
pre-normalized vector를 사용하여 분모를 1로 만들어 로 계산한다.
3. BERTSCORE

계산과정
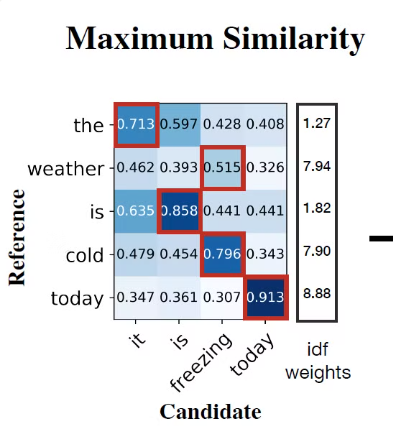
1.위의 그림을 예시로, cold 라는 정답 단어에 대한 예측 단어의 유사도
→ 0.479 / 0.454 / 0.796 / 0.343
가장 높은 0.796인 freezing이 선택된다.
정답 단어를 기준으로 제일 높은 유사도 값들을 구해서 평균을 낸 값이 Recall (재현율) 이다.
4. Important Weighting
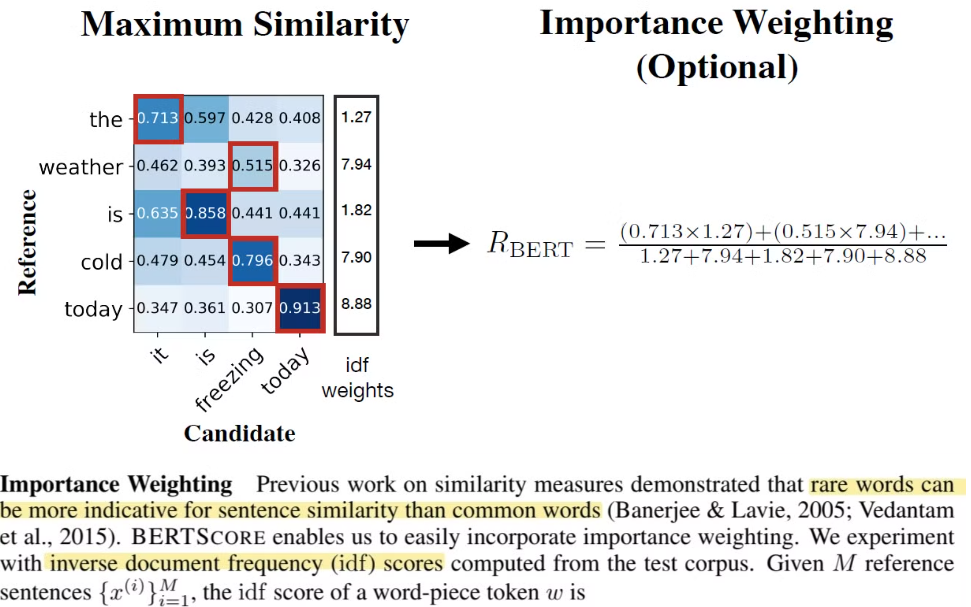
-
빈도수가 낮은 단어들이 중요하다는 점을 공식으로 반영하겠다.
-
TF-IDF(Term Frequency-Inverse Document Frequency)
- TF-IDF는 단어의 빈도와, 역 문서 빈도를 사용해 문서 단어 행렬(DTM)에 가중치를 부여함
- TF와 IDF를 곱한 값
- tf (d,t) : 특정 문서 d에서 특정단어 t의 등장 횟수
- df (t) : 특정 단어 t가 등장한 문서의 수 (한 문서에 여러번 등장해도 한번으로 count)
- idf (t) : df(t)에 반비례하는 수, ( n이 커질 수록, IDF의 값 급증 → log)
- 불용어 등과 같이 자주 쓰이는 단어 비중을 줄여줌 (a, the)
- 특정 문서에서 자주 등장하는 단어는 중요하지만, 여러 문서에서 자주 등장하는 단어는 중요 x
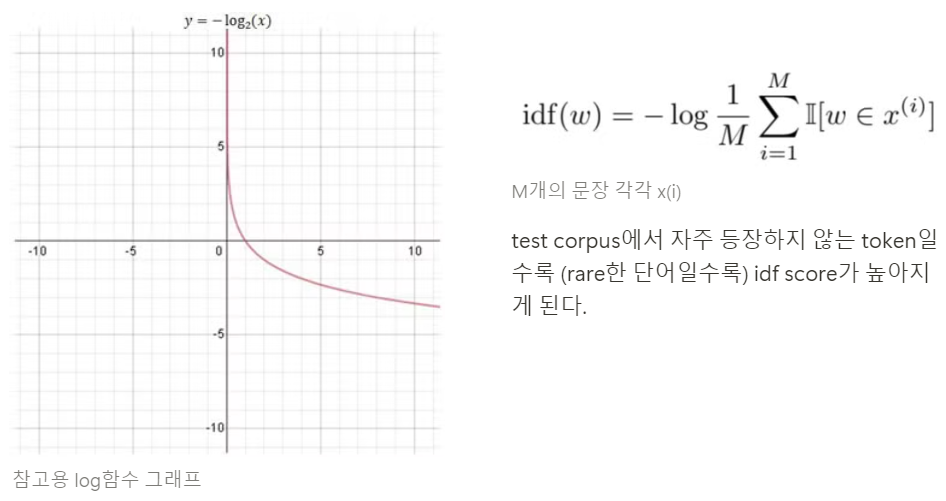

-
분자
각 단어의 중요도(역빈도수) 에 따라 계산된 유사도에 가중치를 부여한다. 드물게 등장하는 매칭된 단어 (코사인 유사도가 높은 단어) 에 대해 강조하게 된다.
- 분모
ref sentence x의 단어들에 대한 IDF 값들의 합으로 전체 유사도 계산이후 정규화하는 역할을 한다.
드물게 등장하는 중요한 단어에 대해 높은 유사도를 가질 경우 더 높은 score를 갖게 된다.
5. Baseling Rescaling

- pre-normalized vector로 진행해 -1~1 사이 값이 나올 줄 알았는데 실제 계산해보니 더 작은 범위
- 가독성을 떨어뜨린다고 판단
- ‘b’ baseline을 경계로 경험적 하한선을 구축
- Common Crawl monolingual datasets 사용
- 1M개의 정답-예측 문장 pair random으로 구축
- 위 pair sample들의 BERTSCORE의 평균으로 b 계산
- score의 가독성만 높여줌, ranking ability에 영향을 주지는 않음
Experiment result
Translation
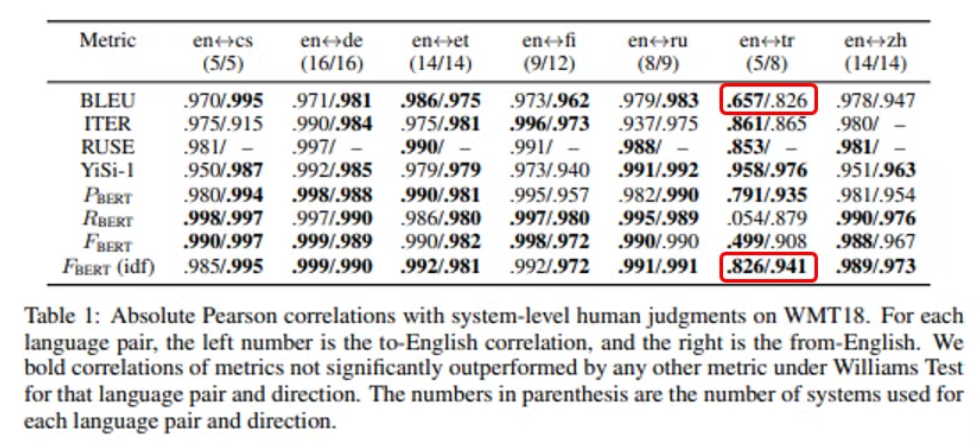
- WMT 18 데이터셋
- human judgments와 Metric을 통한 값 사이의 Pearson 상관관계값의 절대값 을 나타냄.
→ 높을수록, 인간이 번역한 결과와 유사하다
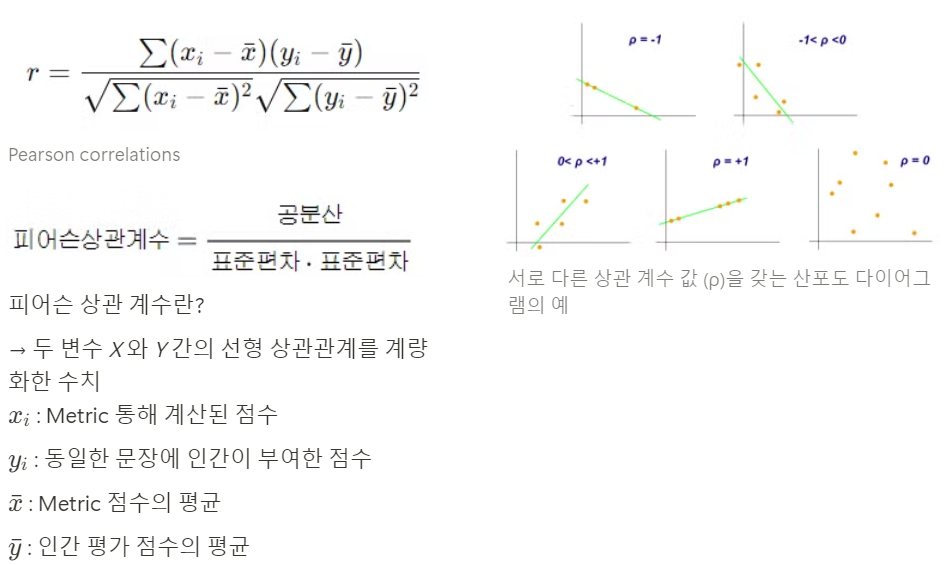
인간이 내린 평가점수와, Metric을 통해 계산한 평가점수가 유사하면, -1에 가까운 혹은 1에 가까운 값을 가진다.
보다 가 더 높은 성능을 가진다.
Image Captioning
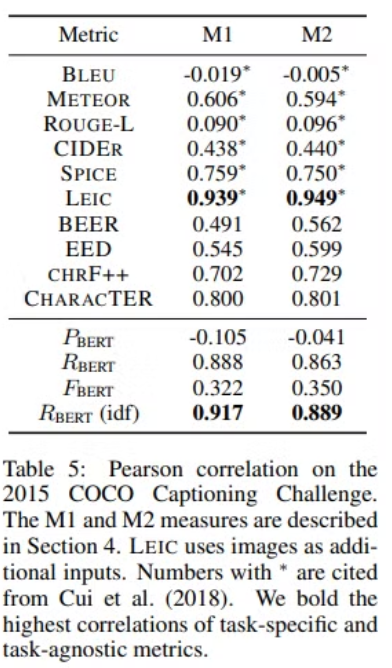

- M1 : 더 좋거나, 인간 캡션과 동일하게 평가된 캡션의 비율
- M2 : 인간 캡션과 구분할 수 없는 캡션의 비율
M1과 M2에 대한 인간의 평가와 Metric을 통한 평가 간 Pearson 상관관계로 일치도 확인
전반적으로 BERTSCORE가 기존의 Metric보다 더 사람이 내린 평가와 유사한 결과를 내는 것을 알 수 있었다. 하지만, 실제로 BERTSCORE를 사용하려면, GPU에 BERT 언어모델을 load해둬야하고, 특정도메인마다 다 다른 cosine similarity 값이 나올 것이다.
그리고, BERT모델을 embedding시 사용하기 때문에 BERT가 가질 수 있는 단점은 모두 가질 수 있는 평가지표라고 할 수 있다.
Reference
https://arxiv.org/abs/1904.09675
https://heavy-bladder-a05.notion.site/BERTScore-Evaluating-Text-Generation-with-BERT-e0904c262b4e4ddda90a9c57a2652ca3?pvs=4
https://heygeronimo.tistory.com/28
https://velog.io/@tobigs-nlp/BERTScore-Evaluating-Text-Generation-with-BERT
