
Double DQN
target network에서의 max Q값을 return하는 a를 선택하는 것이 아니라, main network에서 max Q값을 return하는 a를 target network에서 선택하는 것이다.
main network와 target network에서 max값은 서로 다를 수 있다. 즉, main network에서 Q값이 가장 컸던 action a’ 가 target network에선 제일 큰 Q값을 return하지 않을 수 있다는 것이다.
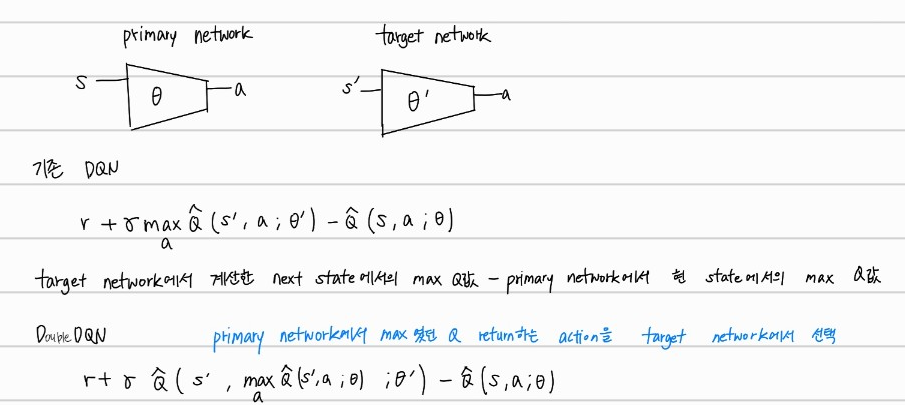
이 방식을 통해서 overestimate(과평가) 하는 것을 방지할 수 있다. 이전에 다룬 Double Q learning과 동일하지만, network를 사용한다는 차이가 있다. 사실 Double Q learning과 DQN을 합친 것이라고 생각하면 된다.
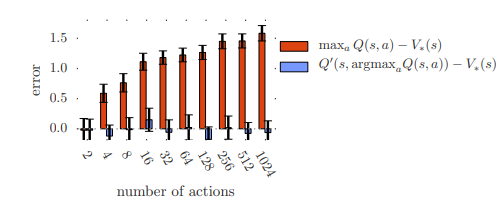
action의 수가 늘어날 수록, vanilla Q-learning은 error가 늘어나는 것을 확인 할 수 있다. Double Q-learning은 error가 action의 수에 비례하지않음을 확인할 수 있다.

(●'◡'●)