
Categorical DQN 이란?
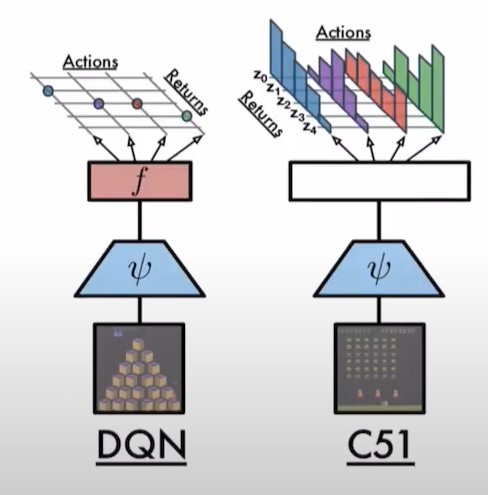
기존의 DQN은 action에 대한 평가 및 더 좋은 action을 선택하기위해 Q value(action return의 expectation) 를 사용한다. Q value는 바로 해당 action을 선택했을 때, 추후의 reward까지 계산하여, 총 reward값인 action value이다. 강화학습의 환경엔 랜덤성을 포함하는 경우가 다양하다. 더 현실적으로 구현할 수록 랜덤성은 증가할 것이다. categorical DQN은 이러한 랜덤성을 포함하는 환경에 대해, action에 대한 return값인 Q value를 확률 분포로써 구한다. 확률분포를 통한 action에 대한 평가는 더 정확하게 환경에 대한 이해를 한 network를 구축할 수 있음을 의미한다.
해당 알고리즘의 구성단계는 parameterization, Bellman update, Projection 순이다.
Parameterization
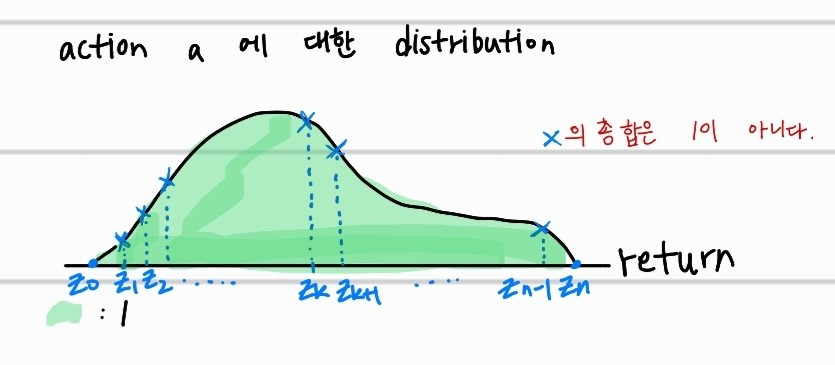
핵심은 바로 continuous distribution을 discrete distribution으로 바꾸는 것이다. 여기서 중요한 support 개념이 등장한다.
support
return의 범위를 n으로 등분하여 return 값 자체를 discrete하게 변환할 때 사용한다. 여기서, 은 각각 action에 대한 return값의 최소치와 최대치이다. 즉 네트워크를 구성하는 사람이 직접 결정해야하는 요소이다. 이 값들은 전부 fix되어있는 값들이고, 변하지않는다.
softmax
Q value의 distribution은 확률 밀도함수로, 전체 나올수있는 continuous 한 return값의 확률 분포의 합이 1이다. 즉, discrete하게 구분한 값들은, 해당 return이 나올 확률이 아닌 그저, 확률밀도함수의 해당 return값에서의 값. 일뿐이다. 따라서, 해당 y값들을 확률로 만들기 위해서 모든 y값들을 합쳐서 1이 나오게끔, softmax를 취한다. 해당 공식을 거친 는 이제, discrete한 return값에 대한 probablity가 되었다.
support와 softmax개념을 모두 합쳐 완성된 discrete distribution은 이다. 여기서 은 각 에서의 값을 보기 위해 사용한 delta function이다.
delta function
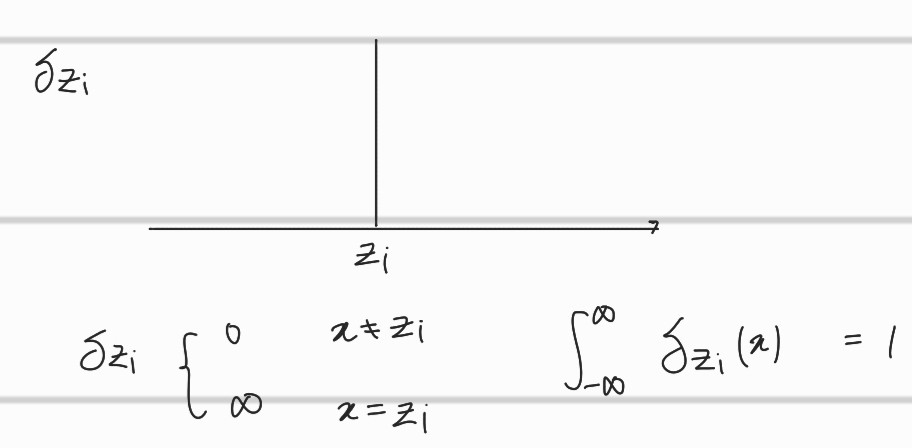 는 에서의 값만 인 함수이다. 따라서, 해당 function을 곱해주게 되면 support의 각 x값들에 해당하는 확률 값들만 가질 수 있게 된다.
는 에서의 값만 인 함수이다. 따라서, 해당 function을 곱해주게 되면 support의 각 x값들에 해당하는 확률 값들만 가질 수 있게 된다.
Bellman update
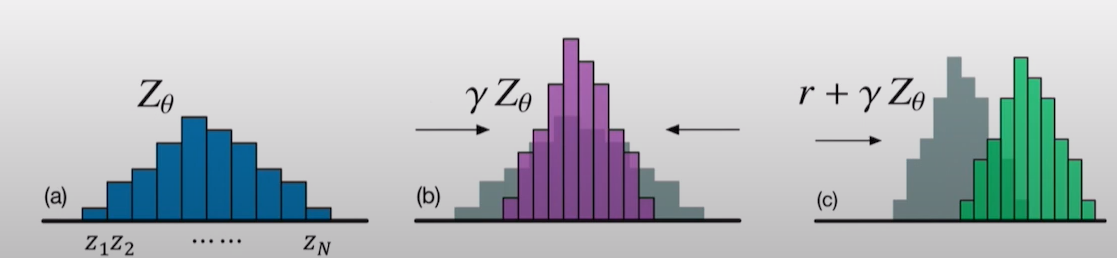
위의 (a)단계는 이전 parameterization을 거친 discrete action value distribution이다. 이제 이 값을 기존의 DQN과 동일하게 Bellman update를 통해서 target값을 도출하는데 사용할 것이다. 다음은 Belmman update 수식이다.
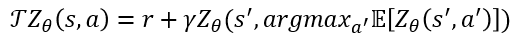
target distribution Z는 r(reward)+ (discount factor) (다음 state에서의 action분포의 기대값 중 제일 큰 action) 이다. 여기서 이 긴 state에서의 action분포의 기대값 중 제일 큰 action은 뭐냐면 바로 Q value이다. 다음 state에서 행할 수 있는 action은 각 action별로 distribution을 가지고 있다. 또한, 각 distribution의 평균은 바로 Q value와 동일한 값임을 나타낸다. 즉, Q value가 제일 크게 나오는 distribution을 가지는 action을 선택하는 것이다. 기존의 DQN과 Bellman update의 알고리즘에서는 차이가 없음을 알 수 있다. 하지만, 해당 Bellman update는 return값에 대한 연산을 진행하는 것이기 때문에, 기존의 action distribution이 좌,우로 평행이동하게 된다(beacuse of added reward). 따라서 제일 처음 조건으로 세웠던 support에 어긋나게 된다. support는 고정되어 있는 값이지만, target distribution 이동하게 되어버리면 main network와 target network의 distribution비교가 불가능 해지는 것이다. 따라서, 이를 극복하기 위해서 Projection이라는 개념을 사용해 loss를 구한다.
Projection
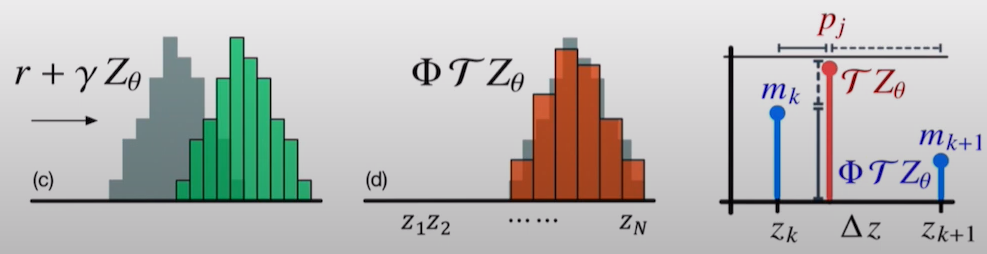
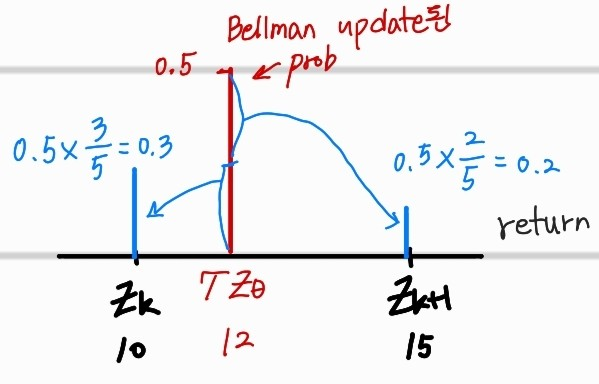
projection의 원리는 간단하다. 바로 직전의 Bellman update시, 이동한 return값들이 support와 다른 x값들(return)값들을 가지게 될 것이다. 하지만 우리는 discrete한 distribution으로 만들기 위해 함수를 이용했기 때문에, support위치의 확률값으로 Bellman update했던 distribution을 이동할 것이다. 꽤나, simple하다. 그저, 인접한 support와의 거리 비율에 맞게, distribution을 분배 해주는 것이다.해당 projection을 거친 target distribution은 가 된다.
Loss (KL distance)
이제 target, main network에 해당하는 action distribution이 모두 support에 맞게 설정 되었다. 마지막으로 그 둘의 loss를 구해야한다. 또한, 해당 loss를 최소화 하는 방법으로 weight를 update하는 것이 이 알고리즘의 마지막이다.
여기서 target distribution은 모두 상수 값이기 때문에, (일정 action 선택시까지 변하지않음 DQN기본 원리,main distribution이 target distribution을 따라가는 동안 target distribution의 값이 바로바로 변해서, 정확한 값으로 converge못함) 이 최소화 되는 값을 구하면 된다. 이를 cross entropy loss라고 한다. 분포간의 차이를 계산할때 자주 이용되는 방법이다. 기존 DQN에서의 mean square loss와 동일한 역할을 한다.

해당 알고리즘을 살펴보면 action selection은 그냥 Q value로 선택하는 것을 알 수 있다. 여기서 Q value는 확률(p)과 변수(return)의 값들이 모두 나와있는 distribution의 mean값이기 때문에, 모두 곱한뒤 sum한 값이다. 아래의 for문을 통해 projection을 완료한뒤, output으로 cross entropy loss를 반환하는 것을 확인할 수 있다.
