
Policy improvement , SARSA
SARSA는 State Action Reward State Action의 줄임말이다. 먼저, TD(Temporal Difference) control에 대해서 알아보자, TD method에서는 최적의 policy를 구축하는 것이 목표다. policy는 모든 state에서 어떤 action을 할지에 대한 확률 값들이다.
즉, 최적의 policy를 찾아가는 것은 reward가 최대가 되게끔 action을 선택하도록 각 state에서의 action 선택 확률값(policy)을 조정하는 것이다.
이런 TD method에는 off policy, on policy 두가지 방법이 존재하고, 각각 Q learning 그리고 SARSA method라고 한다.
On policy & Off policy
on policy와 off policy의 차이는 그렇게 어렵지 않다.
- on policy : behavior policy와 target policy가 동일하다.
- off policy : behavior policy와 target policy가 서로 다르다.
그렇다면 behvior policy와 target policy는 뭘까?
- behavior policy : 실제 강화학습 환경에서의 agent가 action을 선택하는 policy
- target policy : 현재 policy를 evaluate하고, imporve하기 위해 Q(action value) V(state value)를 계산할 때 사용하는 policy
이를 수식으로 나타내면 아래와 같다.
- On policy :
- Off policy :
On policy의 경우 target을 실제 선택했던 action 의 action value를 썼다. 하지만, Off policy의 경우 target은 max값이 되게끔 하는 action을 선택하고, 실제 behavior policy에서 선택하는 action은 달라질 수 있다.
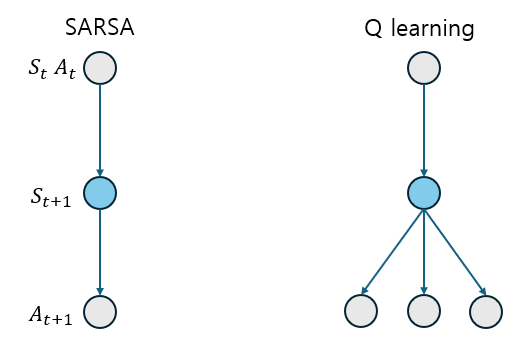
위의 그림과 같이, SARSA는 behavior policy에 따라 을 선택하고 그 값으로 새로운 Q value를 update하고, Q learing은 behavior policy에서 선택한 이 아닌, 에서 가장높은 Q value로 Q value를 update하기 때문에, 선택하지 않았던 action을 반영해서 update하는 것을 알 수 있다.
Expected SARSA
SARSA에서 실제 선택된 action value를 선택하는 것이 아닌, 다음 선택 가능한 모든 action을 수행 한 후, 그 평균값을 사용하는 방법이다.
policy자체가 action의 확률값을 의미하고, Q value는 해당 action을 취했을때 reward를 의미하기 때문에, 평균값((확률x확률변수)=평균)을 구할 수 있다.
기존 SARSA가 선택한 한개의 action에 대해서 update한다는 단점을 극복하기 위해 등장한 방법이다.
Bias and Variance in RL
이제 MC method와 TD method에 대해서 어느정도 정리가 되었다. 둘의 bias, variance 값에 대해 target value를 통해 비교해보자.
Bias
Bias는 실제 target의 평균값과 모델이 예측한 값의 차이다. 따라서 강화학습에서 예측한 state value와 target의 평균의 차이이다.
MC의 경우, state value function 은 이다. MC method 자체가 무수히 많이 수행해 의 평균을 구하고 이를 state value로 지정하기 때문에 bias가 없다는 것을 알 수 있다.
TD의 경우, targe값이 이다. TD method는 실제 관측한 값 을 제외하고 예측한 값 도 포함되게 된다. 즉, Bias가 생길 수 밖에 없다.
Variance
Variance는 예측한 값이 얼마나 잡음이 많이 있는지에 대한 값이다.
MC의 경우, 수많은 reward를 모두 측정한 sum이기 때문에 잡음이 껴 큰 값을 왔다갔다한다. 즉 variance가 크다.
TD의 경우, MC에 비해서 reward 자체를 값만 반영하기 때문에, variance가 낮다.
Bias와 Variance 연관성
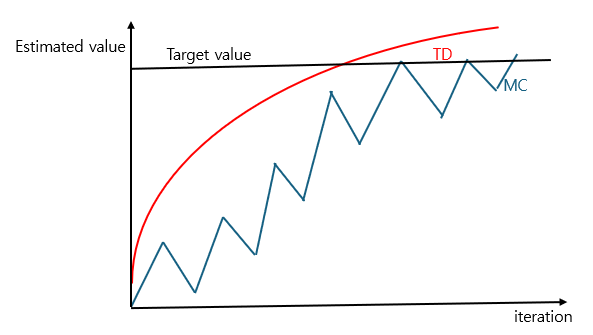
한번 위의 Bias와 Variance를 토대로 MC method와 TD method가 estimate한 value가 어떻게 imporve되는지 그려보았다. MC는 variance가 크다. 그렇지만, iteration을 충분히 많이 진행하면, target value와 가까운 값으로 수렴하는 것을 확인할 수 있다. TD는 오차가 어느정도 있지만, variance가 작아 estimated value가 요동치지 않는 것을 알 수 있다.
MC method가 더 정확한 값으로 수렴하긴 하지만, variance가 너무 커서 많은 iteration을 진행해야 한다. 하지만, 현실적으로, 저정도로 iteration을 진행하는 것은 불가능에 가깝다. 즉, 어느정도 오차는 있지만, variance가 작아 덜 요동치는 예측값을 가지는 TD method가 많은 iteration을 진행하기 힘든 case에선 더 좋다는 것을 알 수 있다.
