
Off policy Model free
Q learning의 가장 큰 특징은 모델 없이 학습하는 강화학습 알고리즘이라는 것이다. 강화학습 MDP를 기반으로 한다. 여기서 Q learning은 각 state에서의 transition에 대한 정보가 없어도 구현이 가능한 알고리즘이다. 즉 agent는 environment에 대해서 알지 못하고, 그저 action을 수행하며 environment가 알려주는 next state,reward를 수동적으로 알게 되는 것이다.
이때 action을 수행했을때 얻는 action value = Q value를 활용하기 때문에 Q learning이라는 이름이 붙여졌다. Q learning의 목표는 최적의 policy를 유도하는 것이다.
Policy : 주어진 state에서 어떤 action을 선택할지 확률로 표현한 규칙
주어진 state에서 action을 수행했을 때의 기대값인 Q value를 최대로 갖게 하기 위해 학습을 수행하고 최적의 policy를 유도한다. Agent는 reward의 총합을 최대화하기 위해 학습을 진행한다. 또한, 행동을 선택하는 policy와 reward를 계산할때 사용하는 target policy가 서로 다른 것을 통해서 SARSA와의 차이를 알 수 있다.
위의 식은 Q value를 update하는 과정이다. 에서의 Q value를 구하기 위해, 을 사용한다. next state에서 Q value를 가장 크게 받을 수 있는 action을 선택하는 것이다. 위의 수식은 MC(Monte Carlo)의 Random sampling과 DP(Dynamic Programming)의 bootstrapping을 활용하는 것을 알 수 있다.

Bootstrapping과 Random sampling을 모두 사용하여 model free인 알고리즘과 동시에 terminal state가 없어도 Q value를 계산할 수 있고, 빠르게 즉각 Q value를 update가 가능하다는 장점이 있다.
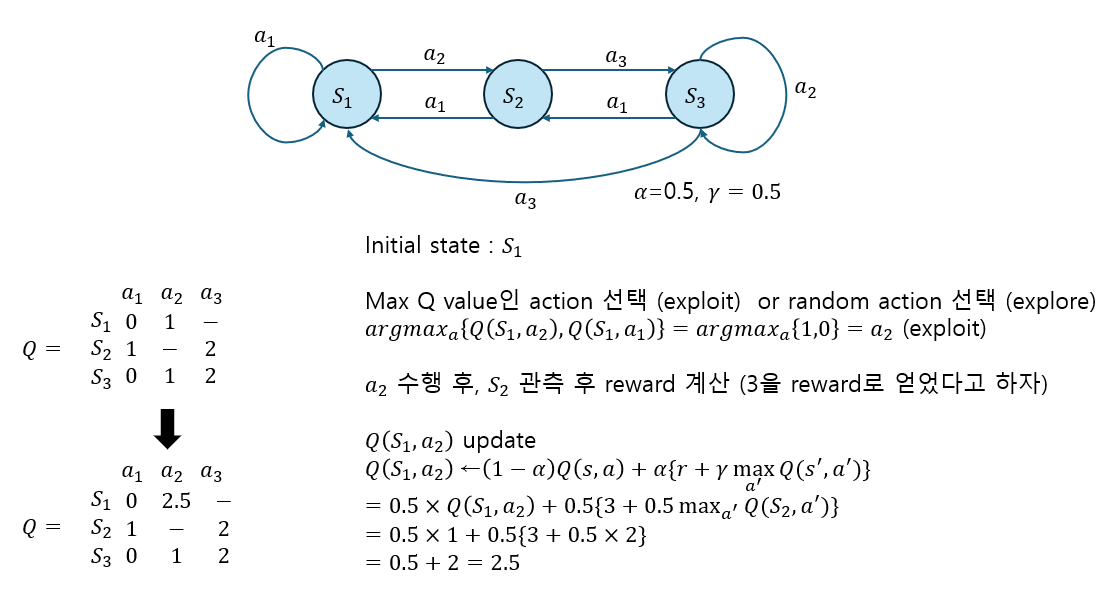
Q Matrix update example
실제로 Q learning에서는 next state, current state에서의 action에 대한 Q value 값들로 이루어진 Q table이 존재하고 이를 활용해서 Q value를 update한다. 방법은 아래와 같다.
SARSA와 Q learning의 차이
둘의 차이를 설명하기 위해서, "Cliff Walking" 예시를 들어서 차이를 확인해보자.
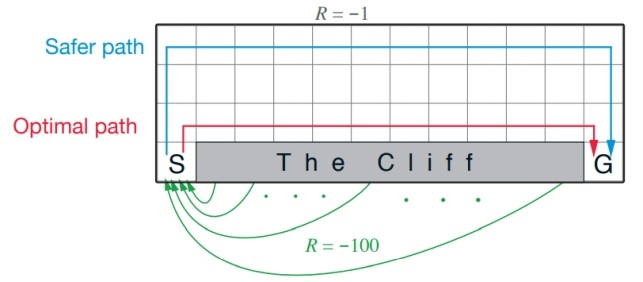
위의 그림에서 알 수 있듯이 절벽에 해당하는 부분으로 이동하게 되면 -100 reward를 받고 시작점으로 이동하게 되고, 나머지 모든 이동에서는 지속적으로 -1 reward를 받게 된다. 같은 환경에 대해서 Q learning과 SARSA는 다르게 동작한다.
- Q learning : 절벽을 따라서 목적지에 도달하면 가장 적게 이동하기 때문에, Optimal policy에 해당한다. 이 값들을 토대로 Q learning을 진행하지만, greedy 방법 때문에 절벽으로 떨어지는 일이 종종 벌어질 수 있다.
- SARSA : Q learning과 다르게 실제로 행한 action을 고려하여 학습하기 때문에 더 오래걸리지만 더 안전한 길로 가게 된다. 즉, greedy 로 action을 하고난 후에 update를 진행한다. 둘의 reward graph는 아래와 같이 그릴 수 있다.
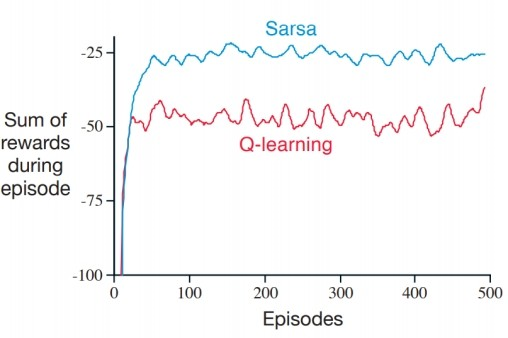
결론적으로, SARSA는 보수적인 접근을 하여, 다음 행동을 고려할 때 최대한 절벽 근처를 피하려고 한다. Q learning은 최적의 경로를 찾을 때, 절벽에 떨어지는 위험을 감수하더라도 더 짧은 경로를 시도할 수 있다. SARSA는 현재 정책에 따라 신중하게 행동하고, Q learning은 최적의 가능성을 추구하며 때로 큰 위험을 감수한다는 것을 결론적으로 알 수 있다. 환경에 따라서, 각각의 장단점을 고려하여 선택하면 된다.
- 환경의 위험성
SARSA: 위험이 크거나 잘못된 결정이 큰 손실을 초래할 수 있는 환경에서는 SARSA가 더 안전한 방법일 수 있다. 에이전트가 현재 정책에 따라 행동하기 때문에, 위험을 회피하는 경향이 더 크다.
Q-learning: 환경이 안정적이고 탐험을 통해 더 빠른 학습이 필요한 경우, Q-learning이 더 효과적일 수 있다. 이 알고리즘은 최적의 행동을 항상 추구하기 때문에, 더 빨리 최적의 해결책을 찾아낼 수 있다.
- 학습의 목표:
SARSA: 에이전트가 안전하고 안정적인 방법으로 학습하길 원할 때 적합하다. 에이전트의 현재 정책에 충실하면서 점진적으로 개선된다.
Q-learning: 최적화된 결과를 빠르게 도출하는 것이 목표일 때 유리할 수 있다. 최적의 경로를 무리하게 시도하면서도 빠른 성과를 얻을 수 있다.
- 에이전트의 정책:
SARSA: 에이전트가 현재 학습 중인 정책에 따라 행동한다.
Q-learning: 에이전트가 현재 정책과 무관하게 최적의 행동을 추구한다.
TD learning의 문제, Double Q learning
Overestimate
TD learning에 해당하는 Q learning과 SARSA 모두 Maximization 문제가 발생할 수 있다. Q learning에서 target policy는 max로 정의한 action을 선택하고, SARSA에서도 마찬가지로 policy가 greedy를 따르기 때문에 Maximiazation 문제가 발생할 수 있다. 이는 positive bias로 이어질 수 있다.

target을 계산할 때, max operator를 사용하기 때문에, 비현실적인 action value로 학습하게 된다.
- A 노드에서 오른쪽으로 이동시 0의 reward 받음
- A 노드에서 B 노드쪽으로 이동시 평균 -0.1 분산 1 의 gaussian 분포의 reward를 받음
B노드로의 reward 분포에서 max Q value를 return하게 되면, 항상 최대값만 나오기 때문에 양수의 reward값 혹은 음수여도 0에 가까운 큰 값만 return하게 된다. 따라서, 에이전트는 B노드로의 이동을 선택하게 된다. 이처럼 max값만을 사용해서 target value를 예측하는 것이기 때문에 overestimate 현상이 발생하게 된다.
Double Q learning
위의 maximization bias를 줄이기 위해서, 나눠진 두개의 value function을 상호작용하여 학습하는 것이다.

table을 update 할때 table에서의 max Q 값을 사용해서 update하는 것이 아닌, table을 사용해서 update하는 것이다. max 값이였던 action을 그대로 table에서 선택한 후 value를 estimate한다. Q table을 두개 사용하면서, 바로 max Q 값을 사용하는 것이 아니라, max Q값을 가지는 action을 다른 Q table에서 선택하여 사용하기 때문에 maximization bias를 최소화 할 수 있는 것이다.
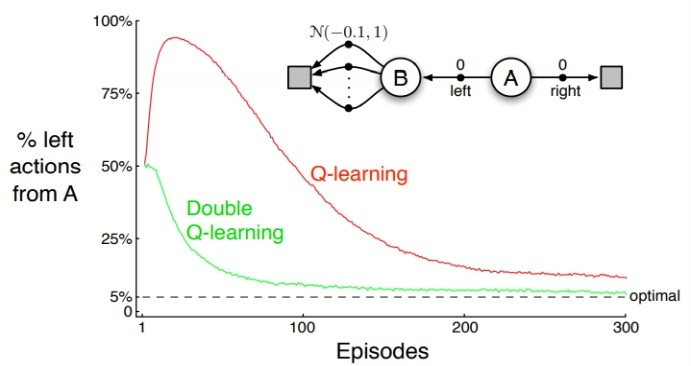
위의 같은 예시에서 Double Q learning을 진행했을 때, left action 비율이 확연히 줄어든 것을 확인할 수 있다. 이렇게, 지난 포스트에 이어서 TD learning 중 off policy에 해당하는 Q learning에 대해 공부해보고, TD method의 한계점과 이를 극복하기 위해 등장했던 방법에 대해서 알아보았다.
Reference
