
DQN
기존의 Q learning은 state,actoin에 해당하는 Q table이 필요했다. 이는, state와 action의 수가 많아지게 되면, Q table의 크기가 커지게 되며, 많은 memory를 필요로하게 된다. 따라서, 이를 딥러닝으로 해결하는 Deep Q Network가 등장하게 되었다.
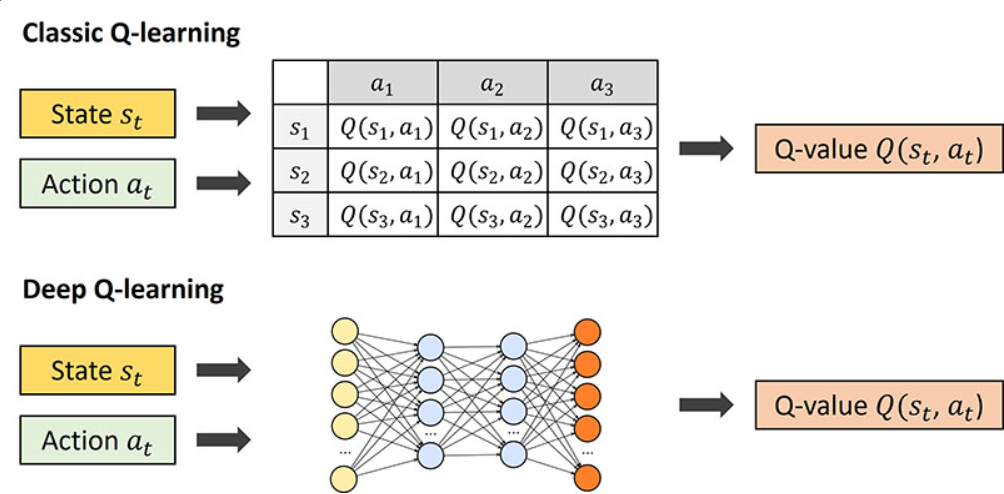
딥러닝을 이용하여 Q table에 해당하는 Q function을 non linear function으로 근사시키면, 모든 state와 action에 대한 Q value를 저장할 필요가 없어진다.
Deep Q learning 의 문제점
2015 Nature 논문에서는 아래를 기존의 Deep Q learning의 문제로 제시했다.
- sample간의 correlation → 현재 state와 다음 state가 독립적이지 않고 종속적이다.
- data distribution의 변화 → data가 고정된 분포를 가진다는 딥러닝과 다르게 강화학습은 에이전트가 새로운 action을 할 때 마다 데이터의 분포가 변경된다.
- 라벨링된 데이터 기반의 기존의 딥러닝 모델과 다르게 강화학습은 오로지 reward를 통해서 학습되고, 그 reward는 action을 한 후에 delay를 가지고 얻게 되며, noisy,sparse한 성격을 띈다.
DQN에서의 experience replay와 target network를 통해 위의 문제들을 해결하였다.
DQN의 특징으로는 1) CNN 2) Experience replay 3) Target network 를 세가지 핵심 요소로 볼 수 있다.
CNN구조
CNN은 고차원의 이미지 input을 효과적으로 처리 가능하다. Atari game에서의 이미지를 input으로 받았기 때문에, CNN을 사용하였고, 기존 linear function approximator보다 더 좋은 성능을 나타냈다.
CNN 구조의 input으로 오로지 state값들만 입력하고 output으로 여러개의 가능한 action에 해당하는 Q value를 가지게끔 설계했다. 값을 찾기 위해 action마다 CNN을 통과시킬 필요없이 이미지 state input을 한 번만 통과해도 되는 장점이 있다.
Experience Replay
Experience Replay
- 매 step마다 sample 을 memory D에 저장한다.
- D에 저장된 sample을 uniform하게 추출해 Q-update 학습에 사용한다.
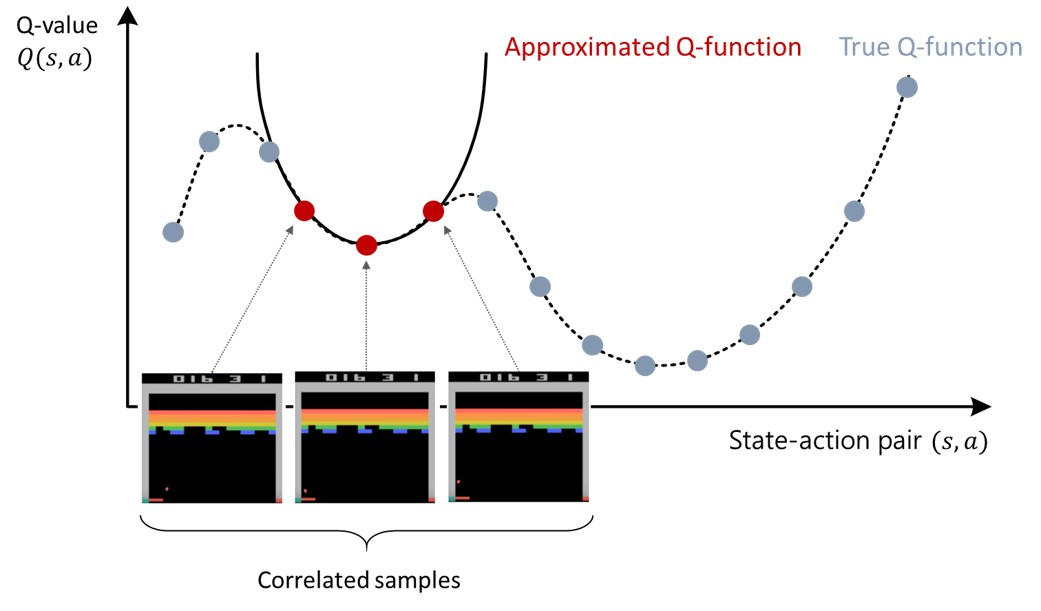
각 step마다 action에 대한 reward를 얻지만, 이를 바로 사용하지 않는다. 의도적으로 메모리에 저장했다가, 후에 균등하게 배치 사이즈만큼 뽑아내면서 1) sample correlation을 막아낼 수 있다. 또한, update를 한뒤 data sample을 버리던 기존 방법이랑 다르게 계속 메모리에 저장하면서 random sampling하기 때문에2) data effficiency를 늘릴 수 있다.
모델을 on-policy로 학습하게 되면, Q update로 인해 behavior policy가 바뀔 때 그로 인해 생성되는 training data의 분포도 크게 변할 수 있다. data 분포의 갑작스러운 변화는 모델이 local minimum에 수렴하거나 발산하게 만들 수 있다. 하지만, experience replay를 통해서 추출된 샘플들은 모두 다른 시간에서 수행된 sample이기 때문에 sample correlation이 작다. 또한, 다양한 action을 고려하여 update를 진행하기 때문에 3) behavior policy에 편향되지 않고 smoothing하는 효과를 가질 수 있다.
Target Network
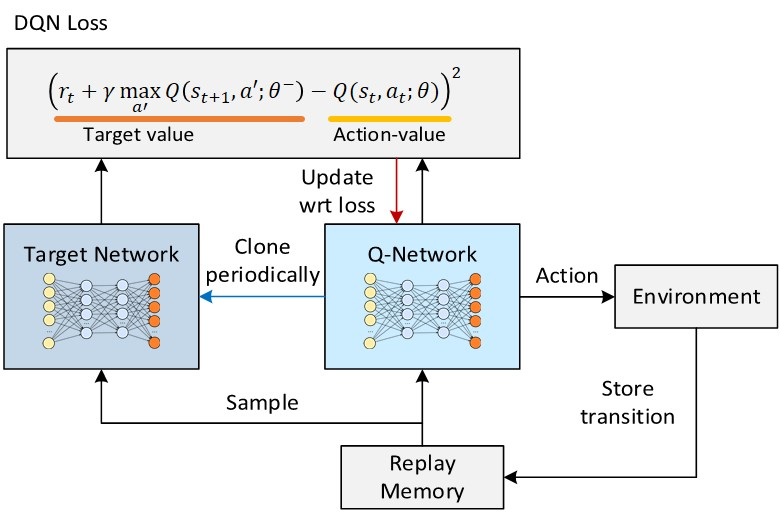
- Q-network: state,action을 이용해 Q value를 얻는데 사용된다. 매 스텝마다 update된다.
- Target-network : target value 를 얻는데 사용된다. 특정 스텝마다 파라미터를 Q-network와 동기화한다.
Target value를 예측할때 사용하는 다른 가중치 로 이루어진 target network를 따로 설정해주면서, target value가 action value를 따라가는 현상을 막아준다.
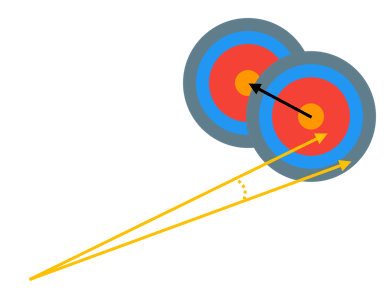
위의 사진을 예시로 설명하자면, 화살을 과녁 정중앙에 맞추기 위해서 점점 action을 수행해가며 영점을 맞추는 과정중에 과녁 자체가 이동해버린 것을 알 수 있다.
&nbps; On policy로 target value를 예측하면 딱 이와 같은 문제가 발생하는 것이다. Target value를 예측할때 사용되는 network가 action을 수행하는 network와 같다면, action을 수행하는 network의 가중치가 조정될때마다 target value도 따라서 이동하는 것이 된다. 따라서, target network와 Q network을 같은 값으로 초기화를 한 뒤, 특정 step을 기준으로 target network를 update하는 방향으로 DQN은 성능을 향상 시켰다.
결론적으로, DQN은 CNN, experience replay, target network의 특징을 가지고 있고. 1) Experience replay를 통한 sample간의 correlation 최소화 및 데이터 효율성 증대, 2) target network를 사용하며 target value가 Q network의 update과정 중에서 변하는 현상 억제, 3) CNN을 통한 이미지 state input 처리 성능 향상 을 이뤄냈다.
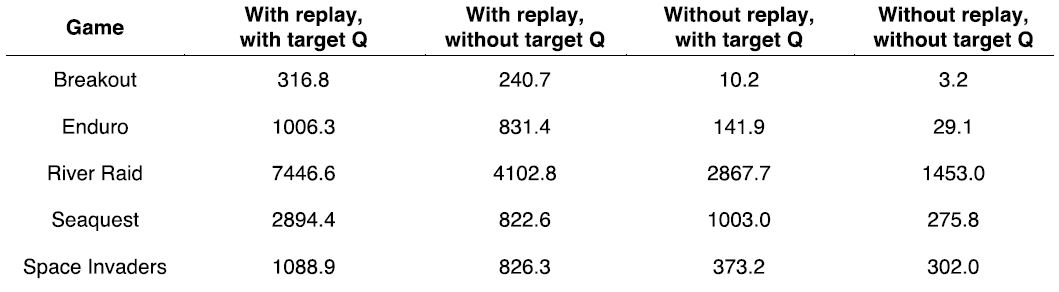
여러 아타리 게임에서 experience replay로 인한 성능개선 효과가 컸으며, Seaquest 게임에서는 target network를 사용하여 큰 성능 개선을 보인것을 알 수 있다.
Referneces
https://ai-com.tistory.com/entry/RL-%EA%B0%95%ED%99%94%ED%95%99%EC%8A%B5-%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98-1-DQN-Deep-Q-Network
https://velog.io/@sjinu/%EA%B0%9C%EB%85%90%EC%A0%95%EB%A6%AC-7.-DQNDeep-Q-NEtwork
