
MRC란
MRC(Machine Reading Comprehension)는 기계 독해라는 의미로, 문단(context)을 이해하고 질의(query)에 대한 답(answer)을 추론하는 task다. huggingface에 의하면, MRC는 답변의 생성과정에 의해 두 종류로 볼 수 있다.
- Extractive Answering
질의에 대한 답이 통상적으로 주어진 지문에 존재하고, 범위가 주어진다. 여기서도 question과 answer의 구조에 의해 두 종류로 나누어진다.
- Cloze Tests dataset
 빈칸에 있는 단어를 맞추는 방식으로 query와 answer를 구하는 dataset을 Cloze Tests dataset이라고 하며, 대표적인 예시로는 위의 사진과 같은 CBT(Children's Book Test)가 있다.
빈칸에 있는 단어를 맞추는 방식으로 query와 answer를 구하는 dataset을 Cloze Tests dataset이라고 하며, 대표적인 예시로는 위의 사진과 같은 CBT(Children's Book Test)가 있다.
- Span Extraction
 우리가 일상적으로 질문하고 답하는 것과 같이, 빈칸을 맞히는 것이 아닌 답을 구하는 dataset이다.
우리가 일상적으로 질문하고 답하는 것과 같이, 빈칸을 맞히는 것이 아닌 답을 구하는 dataset이다.
두 dataset 모두, context 내에 answer에 대한 정확히 일치하는 단어가 존재해야한다.
- Abstractive Answering
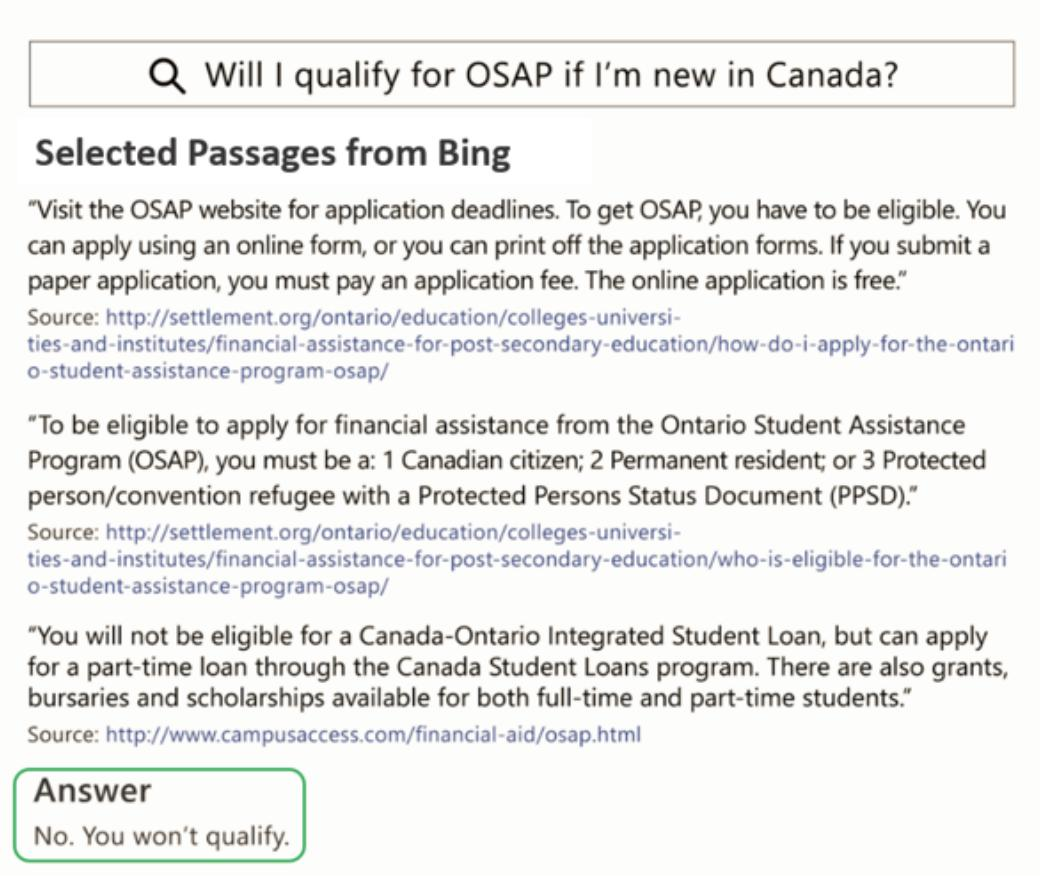 답이 context 내에서 추출한 span이 아니라, 질의를 보고 생성된 free-form 형태이다. 위의 MS MARCO dataset이 예시이다.
답이 context 내에서 추출한 span이 아니라, 질의를 보고 생성된 free-form 형태이다. 위의 MS MARCO dataset이 예시이다.
Challenges in MRC
Paraphrased / Corefernece
먼저, paraphrased는 의역된 이라는 뜻이다. 단어들의 구성은 유사하지 않지만, 동일한 의미의 문장을 이해하는 과정은 큰 어려움이 될 수 있다. 아래의 두 paragraph를 보자
P1 :
..., Cole is selected for a mission, ....
P2 :
..., James Cole, who after retrieving samples is given the chance to go back in time
to 1996 and find information about ...이제 해당 Passage에서의 Question과 answer를 확인해보자
Question : What is the name for the person who selected for the mission
Answer : ColeP1의 경우 Model이 Question 내 단어와 일치하는 paragraph 내 단어인 selected나 mission 을 찾게 되면 단서가 될 수 있다. 하지만, P2는 같은 answer 인 Cole을 포함한 passage이지만, 유사한 의미에 다른 표현이다. (who after~~ 은 mission에 관한 내용으로 볼 수 있음)
또한, Coreference Resolution는 상호 참조라는 뜻이다. 상호 참조의 예시로는 대명사가 있다. 대명사는 뭐를 지칭하는지 이해를 하고 해결해야한다.
P : Tzykanisterion (stadium for playing the game) was built by Theodosius inside
the Great Palace of Constantinople. Emperor Basil excelled at it.위의 passage에 대한 question이 아래와 같다고 하자.
Question : What is Byzantine name of the game that Emperor Basil excelled at?위의 question에 대한 대답은 passage에서 it이다. 하지만. 이는 Tyzkanisterion이라는 것을 알아야한다.
Unanswerable
이는 주어진 지문에서 답을 찾을 수 없는 경우를 의미한다. 예를 들어 passage에서 little change이고, question에서 significant change인 경우 둘의 뜻은 천지 차이이다. 하지만, change 가 일치하기 때문에 이를 정답으로 오인하고 model이 출력하게 되는 것이다.
GPT도 hallucination이 큰 문제로 꼽히는데, 인공지능 모델은 답을 출력하지만, 답이 맞는지 틀렸는지 비판적으로 스스로 평가하는 것이 아직 힘들다. 이렇게 사실 정답이 없는 question에 대해서 정답을 구하려고 하는 문제도 꼽을 수 있다.
Multi-hop
추론의 과정에서 한개의 document만 보고 한다는 확신은 할 수 없다. A,B,C 문서 세개가 존재하고 질문에 대한 답을 구하기 위해서 세 문서를 모두 참조해야 추적해서 답을 찾을 수 있는 경우도 존재한다. 따라서 이 점도 해결해야하는 도전과제 중 하나이다.
MRC Eval
MRC 모델의 평가방법에 대해서 알아보자. 대표적으로 EM과 F1 score가 있다. EM은 Exact Match로 말 그대로 아예 똑같은 답을 내야 1로 계산하는 것이다. F1 score는 답이 정확히 일치하지 않더라도 겹치는 것을 기준으로 계산한다. F1 score는 아래와 같이 계산한다.
Precision 은 사실 BLEU score와 동일하다.
Recall은 사실 ROUGE score와 동일하다.
만약 정답이 I love NLP인데 예측한 결과값이 I really love NLP 라면 recall 값은 1이다. precision은 이다. 쉽게 precision은 분모로 예측한 token의 수가 들어가고, recall은 정답 token의 수가 들어가고 분자는 공통되게 맞힌 token의 수가 들어간다고 계산하면 된다.
Reference
https://huggingface.co/docs/transformers/tasks/question_answering
https://paperswithcode.com/dataset/cbt
https://paperswithcode.com/dataset/squad
