1. 개요
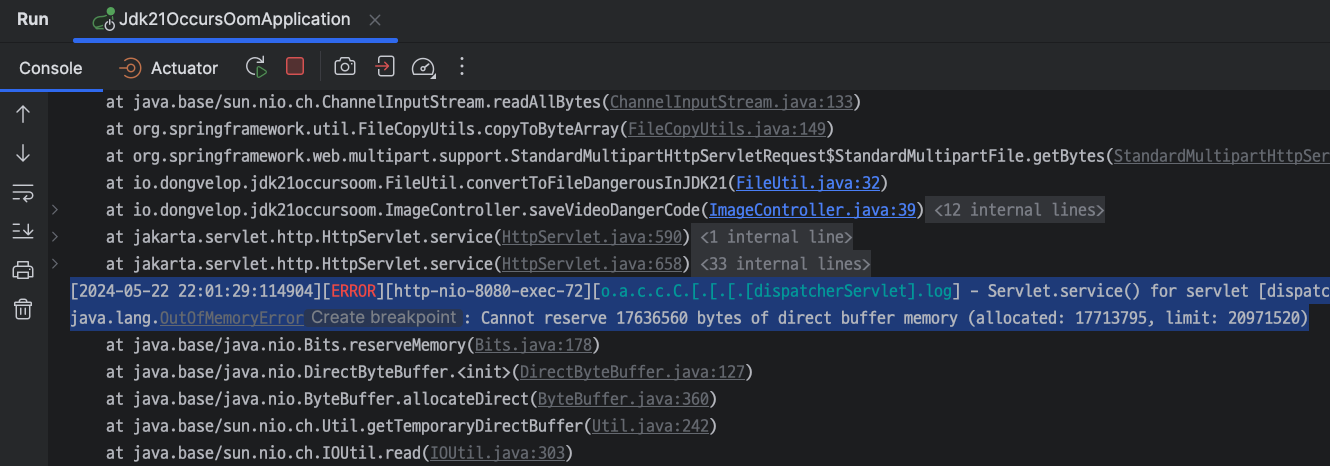
JDK 21를 사용할 경우, MultipartFile.getBytes() 메서드 호출시 아래 사진과 같이 Direct Buffer Memory가 부족하여 Out of Memory Error가 발생하는 경우가 있습니다.
다만, 동일한 소스코드로 JDK 17을 사용할 경우에는 발생하지 않습니다.
따라서 두 JDK 버전 간의 Direct Buffer Memory 사용량을 비교하는 글 입니다.
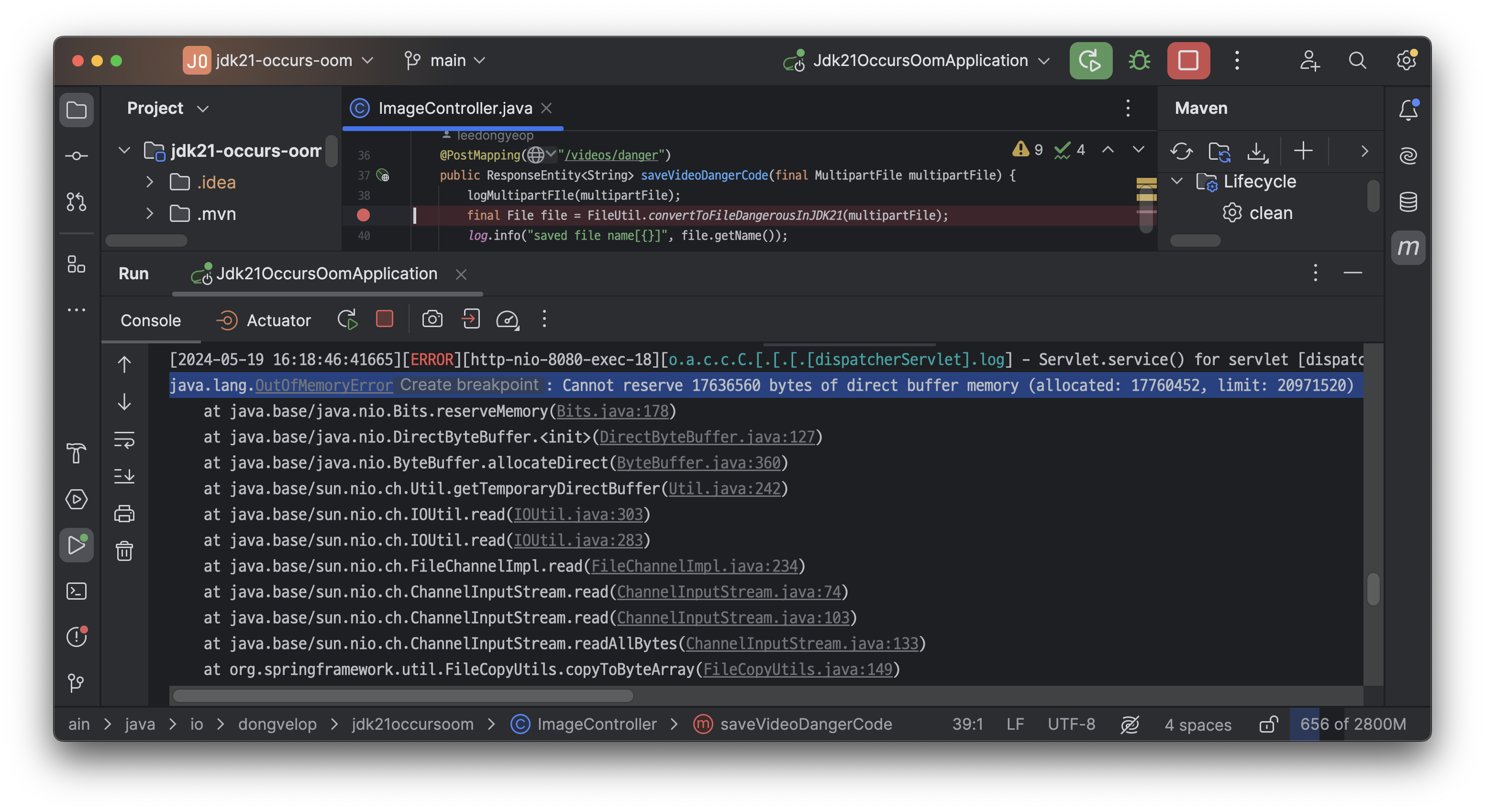
20.9MB 중 17.7MB가 할당되어 있는 상태임. 따라서 17.6MB를 더 할당할 수 없다는 내용
- junhyunny 님의 블로그 글을 참고했으며, 원본 글로부터 아래 내용을 첨언하였습니다.
- Apache Jmeter 사용 방법
- VisualVM 사용 방법
- jcmd 사용 방법
- Spring Boot 실행 시, JVM Option 설명
- InputStream 디폴트 버퍼 크기 변경으로 인한 내용 최신화 (8192Byte → 16384Byte)
2. 프로젝트 세팅
2-1. 주요 코드 작성
MultipartFile.getBytes()를 호출하는 로직 작성
public File convertToFile(final MultipartFile multipartFile) {
final File convertedFile = new File(Objects.requireNonNull(multipartFile.getOriginalFilename()));
try (OutputStream os = new FileOutputStream(convertedFile)) {
os.write(multipartFile.getBytes());
} catch (IOException e) {
log.error("fail to transform multipart to bytes", e);
}
return convertedFile;
}2-2. 실행 환경 구성
-
프로젝트 스펙
- Spring Boot 3.2.5 & JDK 21/JDK 17
-
힙 메모리 사용량 확인할 도구
- VisualVM
- jcmd
-
Apache Jmeter 구성
- 스레드 수 : 200개
- 램프 업(ramp-up) 시간 : 3초 (3초간 나누어 지속적으로 요청이 실행됨을 의미)
- 5초간 반복
-
요청에 사용될 샘플 동영상(17.6MB mp4)
-
실행시 사용될 JVM Options
java -jar -XX:NativeMemoryTracking=summary -Xmx2G -XX:MaxDirectMemorySize=20M {jar 파일명}-
-Xmx2G : 최대 힙 메모리 사이즈를 2GB로 제한
-
-XX:MaxDirectMemorySize=20M : 다이렉트 메모리 사이즈를 20MB로 제한
- 다이렉트 메모리 : JVM 프로세스가 I/O 작업을 위해 사용하는 바이트 배열 저장 위치 → 네이티브 메모리에 속함
-
-XX:NativeMemoryTracking=summary- 이 옵션을 사용하면 JVM의 네이티브 메모리(힙 이외의 메모리) 사용량을 추적 가능.
- 모든 옵션은 다음과 같다. [off/summary/detail]
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=<file-or-dir-path>이 힙 메모리 문제를 진단하기 위해 사용된다면,NativeMemoryTracking옵션은 네이티브 메모리를 진단하는데 사용됨.
-
이외 참고하면 좋을 JVM Options
-Xms<heap size>[unit] -Xmx<heap size>[unit] -XX:MaxMetaspaceSize=<metaspace size>[unit] Metaspace는 크기가 전역 한계에 도달하면 JVM이 자동으로 이를 늘리므로, 크기가 정의되지 않는다. 그러나 불필요한 불안정성을 극복하기 위해 다음을 사용하여 메타스페이스 크기를 설정할 수도 있다. -XX:NewSize=<young size>[unit] Oracle 지침에 의하면 Young 영역의 최소 크기는 1310MB이고 , 최대 크기는 무제한으로 권장하고 있다. -XX:+UseG1GC: Enables the Garbage-First (G1) garbage collector, which is designed for applications with large heaps and limited Garbage Collection latency requirements. -XX:+UseZGC: Enables the Z Garbage Collector, which is designed for applications requiring low latency without sacrificing throughput. -XX:+UseShenandoahGC: Enables the Shenandoah Garbage Collector, which aims to reduce Garbage Collection pause times by performing more garbage collection work concurrently with the application threads. -XX:+UseParallelGC: Enables the parallel garbage collector for the young generation. -XX:NewRatio=<ratio>: Sets the ratio between the young and old generation sizes. For example, -XX:NewRatio=3 means the old generation will be three times the size of the young generation. -XX:SurvivorRatio=<ratio>: Sets the ratio of the eden/survivor space size. Decreasing this ratio can increase the size of the survivor spaces. -XX:MaxGCPauseMillis: Sets a target for the maximum Garbage Collector pause time. This is a soft goal, and the Java Virtual Machine will make its best effort to achieve it. -XX:+UseSerialGC: Enables the serial garbage collector, which uses a single thread for garbage collection and is suitable for small applications with low memory footprint. -XX:ParallelGCThreads: Sets the number of threads used during parallel phases of the garbage collectors. The default value varies with the platform on which the Java Virtual Machine is running. -XX:ConcGCThreads: Number of threads concurrent garbage collectors will use. The default value varies with the platform on which the Java Virtual Machine is running. -XX:InitiatingHeapOccupancyPercent: Percentage of the entire heap occupancy to start a concurrent Garbage Collection cycle. -XX:+HeapDumpOnOutOfMemoryError: Tells the Java Virtual Machine to generate a heap dump when it throws an OutOfMemoryError. -XX:+PrintGCDetails: Prints detailed output at each garbage collection. Useful for tuning the garbage collector. -XX:+PrintGCDateStamps: Adds a date stamp to each garbage collection event printed in the logs. -XX:+PrintHeapAtGC: Prints detailed information about the heap before and after Garbage Collection. -XX:+PrintGCApplicationStoppedTime: Prints how much time was spent in Garbage Collection pauses, helping in identifying pause times due to Garbage Collection. -XX:+PrintGCApplicationConcurrentTime: Reports the time spent outside of garbage collection (i.e., the time the application was running). -XX:+UseCodeCacheFlushing: Allows the Java Virtual Machine to flush the code cache when it is full, which can help prevent the Java Virtual Machine from shutting down if the code cache fills up.
-
3. 도구들 사전 설명
3-1. Apache Jmeter 설정
- 첫 실행시, Test Plan의 이름 및 설명을 첨부할 수 있음
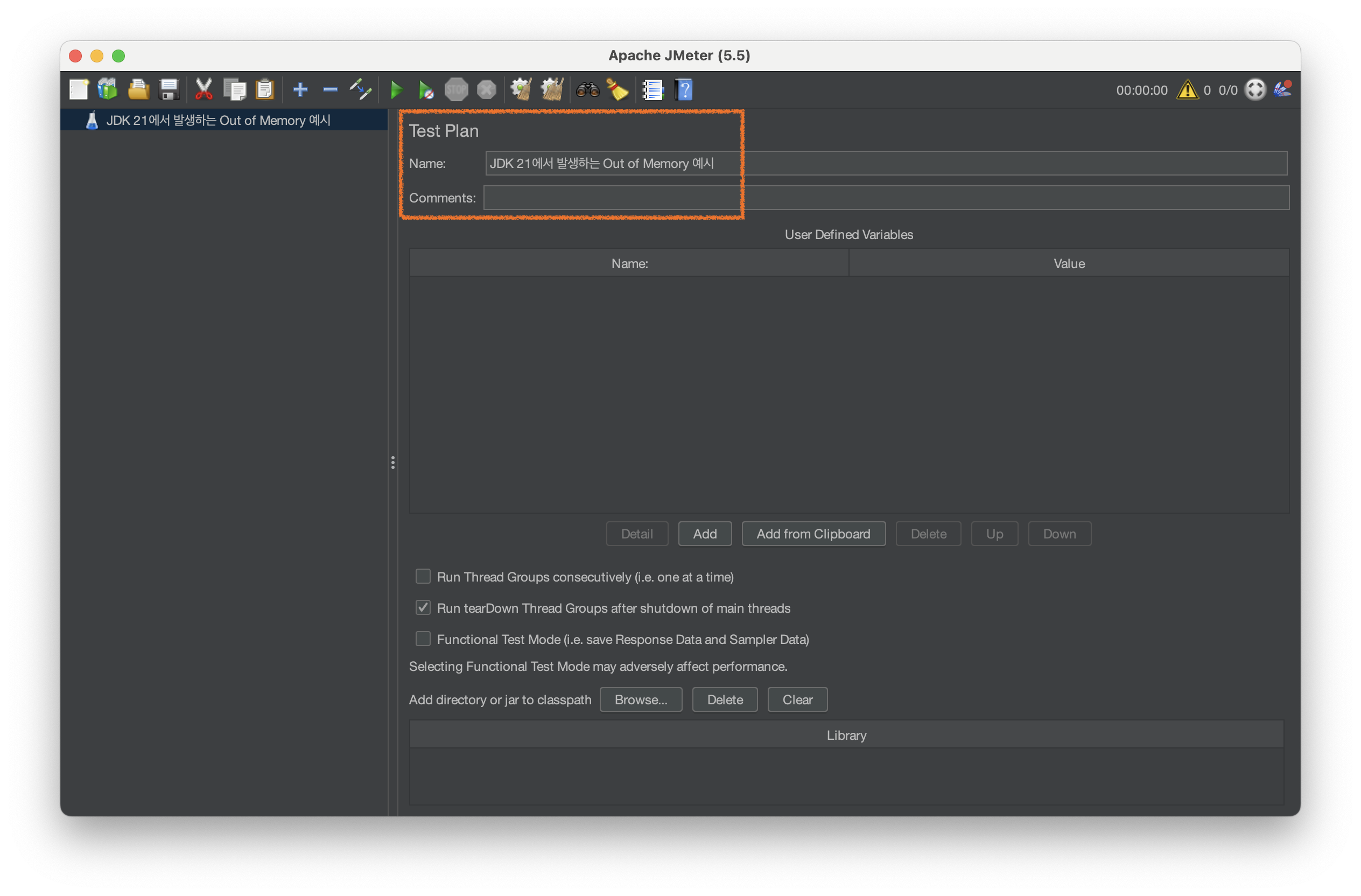
-
스레드 요청 그룹 생성 후, 요청 속성 설정
- Number of Threads : 동시에 실행되는 가상 사용자의 수
- Ramp-up Period : 가상 사용자가 전체 시간 동안 동시에 시작되지 않고, 일정한 시간 동안 차례로 시작되는 기간을 지정
- Loop Count : 반복 횟수
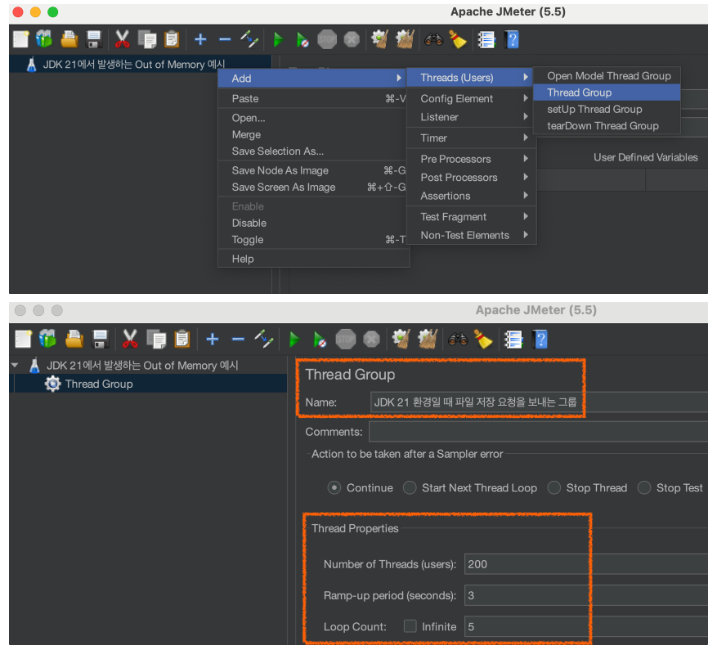
-
요청 생성 후, Request URL 및 헤더, 파라미터(혹은 Body) 지정
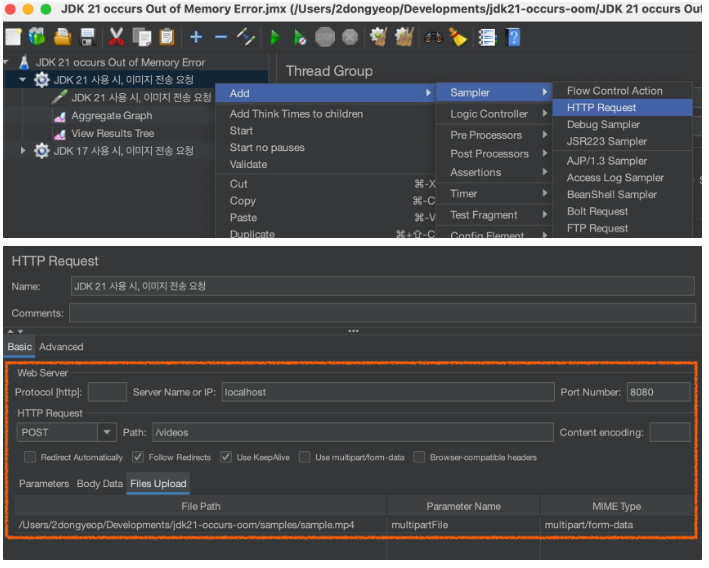
3-2. VisualVM 간단 설명
-
VisualVM : Download에서 운영체제에 맞는 설치 파일을 다운로드
-
로컬에서 Spring Boot 애플리케이션을 실행시 VisualVM을 실행하면
Local탭에서 확인 가능- Local : 로컬에서 실행되는 Java 프로세스 목록을 제공
- Remote : 원격에서 실행되는 Java 애플리케이션을 연결 시, 모니터링 가능
- Vm Coredumps : JVM에서 생성된 코드 덤프를 관리하고 분석하는 데 사용
- JFR SnapShots : Java 애플리케이션의 JFR 스냅샷을 찍고 분석하는 데 사용
- Snapshots : 힙 덤프 및 스레드 덤프를 분석하는 데 사용
-
Overview
- 런타임 시에 JVM arguments 및 System properties를 확인할 수 있음
- 런타임 시에 JVM arguments 및 System properties를 확인할 수 있음
-
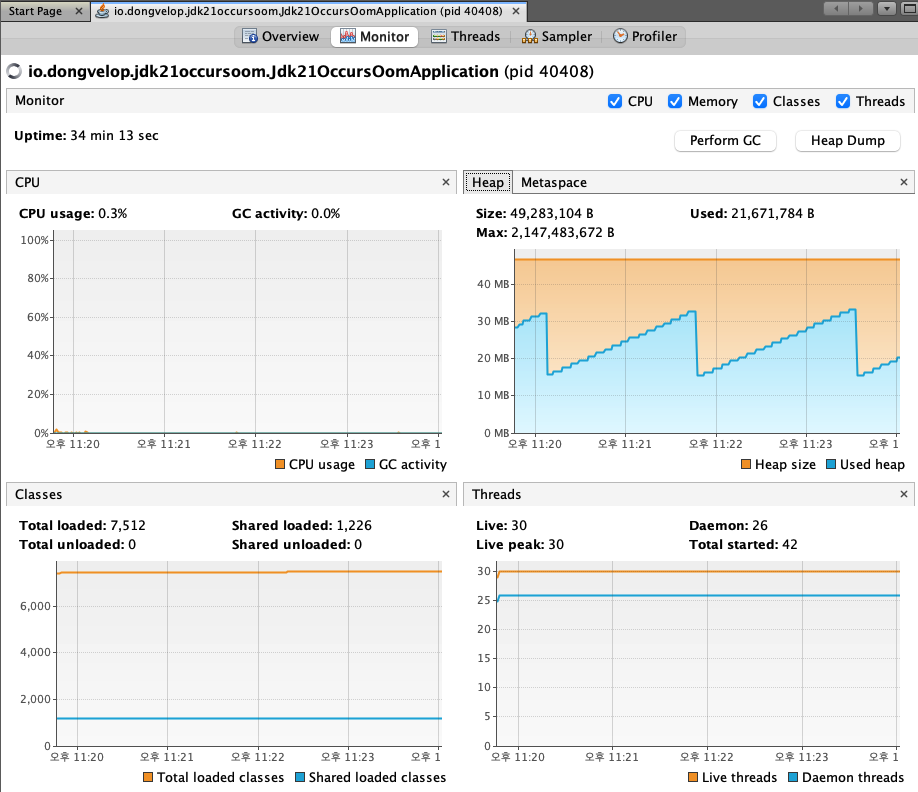
Monitor
- 이 메뉴에서 힙/메타스페이스 메모리 영역을 확인 가능
- 이외에도 스레드 수 및 GC 발생 등을 확인 가능
3-3. jcmd 간단 설명
오라클 공식 문서에서는 jcmd는 아래와 같이 설명한다.
The jcmd utility is used to send diagnostic command requests to the JVM, where these requests are useful for controlling Java Flight Recordings, troubleshoot, and diagnose JVM and Java Applications. It must be used on the same machine where the JVM is running, and have the same effective user and group identifiers that were used to launch the JVM.
요약하면 아래와 같다.
- JDK를 설치하면 실행 파일이 모여있는 bin 폴더 내에 내장
- JVM 애플리케이션의 상태를 진단하기 위해 요청을 보내는 도구
- JVM 애플리케이션이 실행되고 있는 환경에서만 사용할 수 있다.
- JVM 애플리케이션을 실행한 후 jcmd를 활용해 PID를 알아낼 수 있다.
$ jcmd
69793 /opt/homebrew/Cellar/jmeter/5.5/libexec/bin/ApacheJMeter.jar
18561 com.intellij.idea.Main
4038 jdk.jcmd/sun.tools.jcmd.JCmd
3353 io.dongvelop.jdk21occursoom.Jdk21OccursOomApplication- 메모리 측정하기
jcmd는 기본적으로 네이티브 메모리의 정보는 제공하지 않는다.
따라서 JVM 애플리케이션을 실행할 경우 XX:NativeMemoryTracking=summary 와 같이 옵션을 줘야 한다.
기준선(baseline) 생성하기
이후 기준선이 만들어진 시점부터 메모리에 어떤 변화가 있는지 알 수 있도록 사용된다.
$ jcmd {PID} VM.native_memory baseline메모리 변경 확인하기
측정하고 싶은 타이밍이 되었을 경우, 아래 명령어를 입력하자.
$ jcmd {PID} VM.native_memory summary.diff4. 프로파일링
동일한 소스코드를 사용하며, JDK 버전만 바꾸어 테스트 환경을 변경합니다.
모든 실행 결과 및 메모리 분석은 아래 순서로 진행합니다.
- JDK 버전 선택 후 JVM 애플리케이션 실행
- VisualVM Monitor 탭에서 그래프 파악
- jcmd baseline 지정
- Apache Jmeter로 스레드그룹 요청 실행
- VisualVM Monitor 탭에서 그래프 비교
- jcmd Memory Diff 비교
4-1. JDK 21 테스트
JDK 21 테스트 한눈에 보기
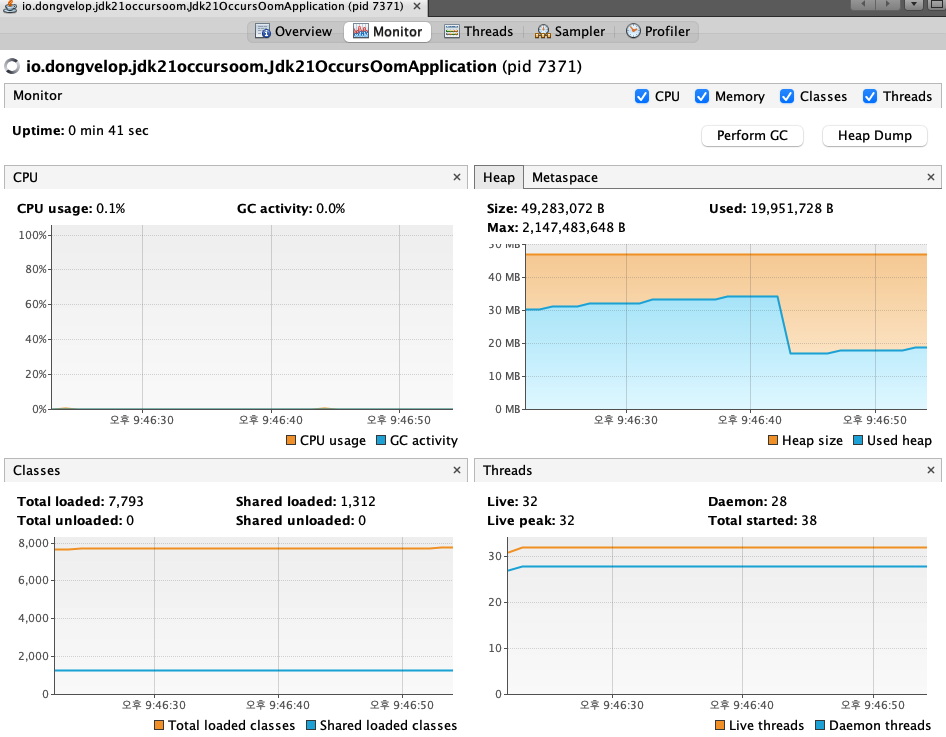
요청 전 VisualVM
힙 메모리 사용량이 10MB ~ 40MB 사이를 유지
jcmd
baseline 지정
$ jcmd 64214 VM.native_memory baseline
64214:
Baseline taken4-2. Apache Jmeter 요청 결과
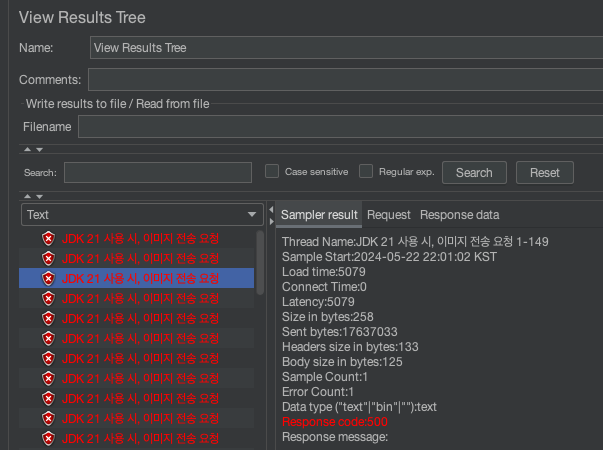
대부분의 요청이 500 에러를 응답으로 실패 처리
4-3. JDK 21에서의 메모리 분석
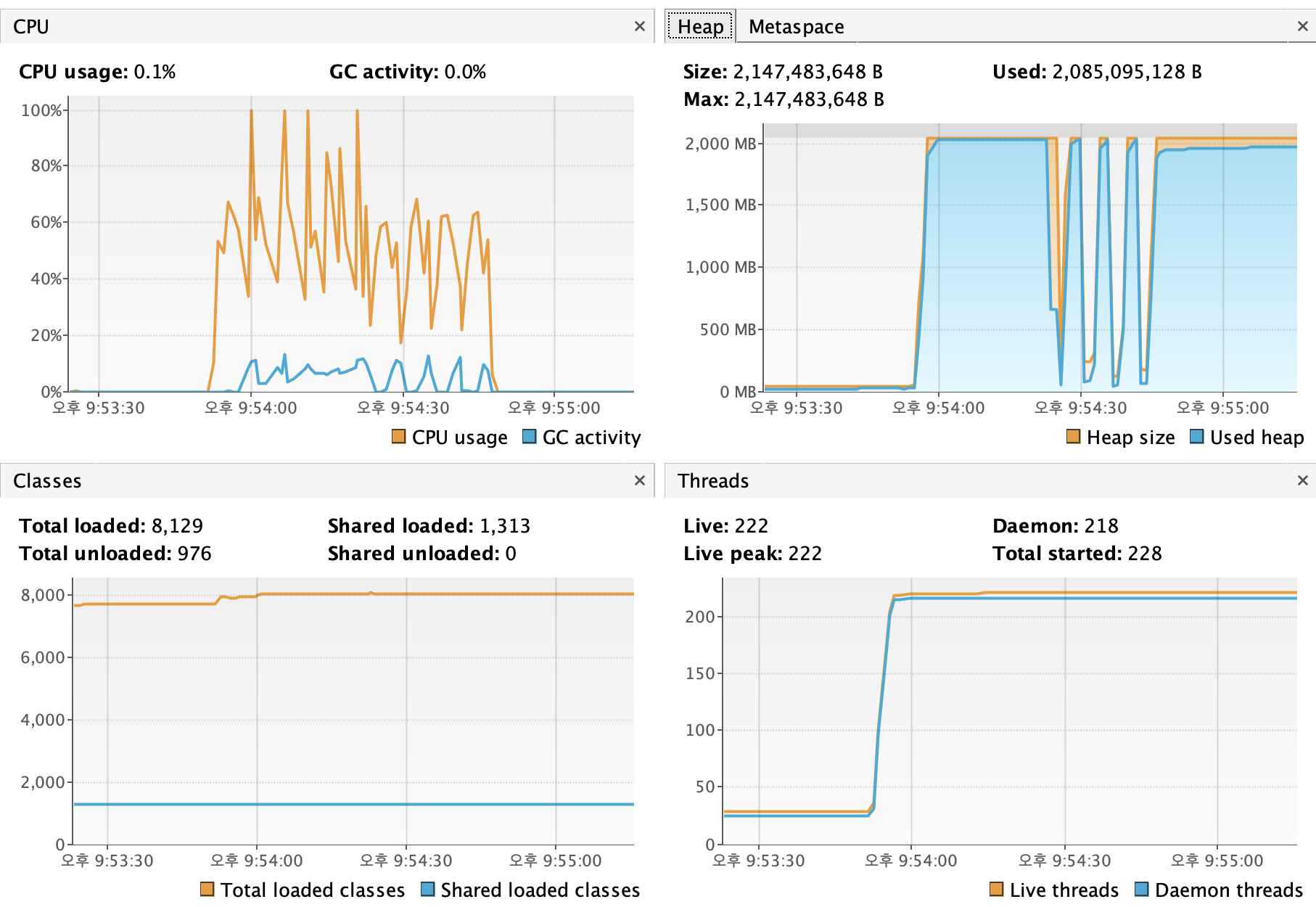
요청 후 VisualVM
요청이 들어옴과 동시에 힙 메모리의 사용량이 급증 → 이후 사용량이 낮아지지 않음
IntelliJ 콘솔창
OutofMemoryError 발생
20.9MB 중 17.7MB가 할당되어 있는 상태이므로, 17.6MB를 더 할당할 수 없다는 내용
jcmd 메모리 분석 결과
힙 메모리가 약 2GB정도 증가하고, 다이렉트 메모리가 약 17MB 증가했다.
$ jcmd 64214 VM.native_memory summary.diff
64214:
Native Memory Tracking:
(Omitting categories weighting less than 1KB)
Total: reserved=3894742KB +415479KB, committed=2769846KB +2499943KB
- Java Heap (reserved=2097152KB, committed=2097152KB +2039808KB)
(mmap: reserved=2097152KB, committed=2097152KB +2039808KB)
- Other (reserved=17705KB +17673KB, committed=17705KB +17673KB)
(malloc=17705KB +17673KB #403 +399)4-4. JDK 17 테스트
JDK 17 테스트 한눈에 보기
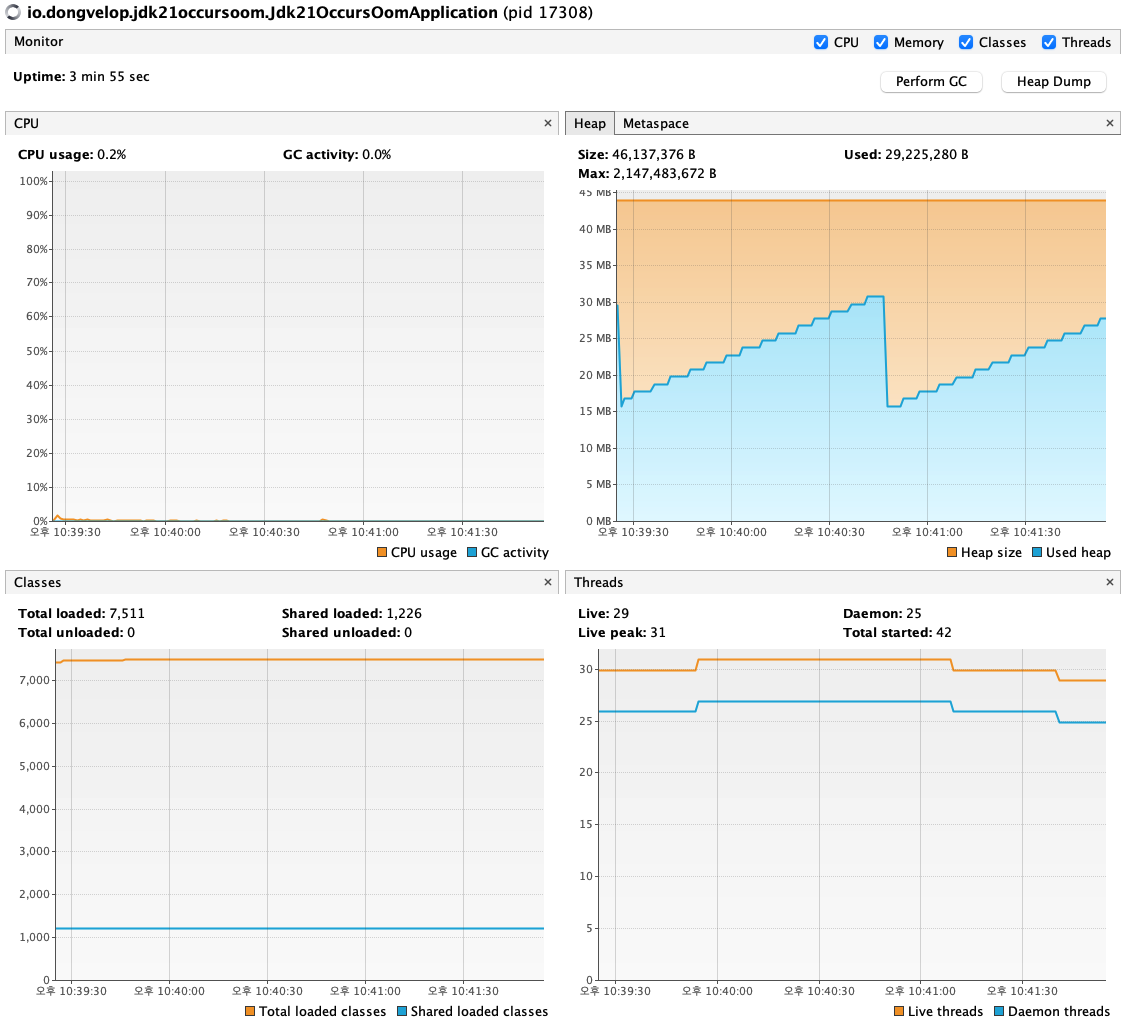
요청 전 VisualVM
힙 메모리 사용량이 15MB ~ 30MB 사이
jcmd
baseline 지정
$ jcmd 17308 VM.native_memory baseline
17308:
Baseline succeeded4-5. Apache Jmeter 요청 결과
대부분의 요청이 성공처리 (간혹 Out of Memory가 아닌, Socket이 끊어져 실패한 경우가 발생)
4-6. JDK 17에서의 메모리 분석
요청 후 VisualVM
요청이 들어옴과 동시에 힙 메모리의 사용량이 급증 → 이후에는 사용량이 점차 낮아짐
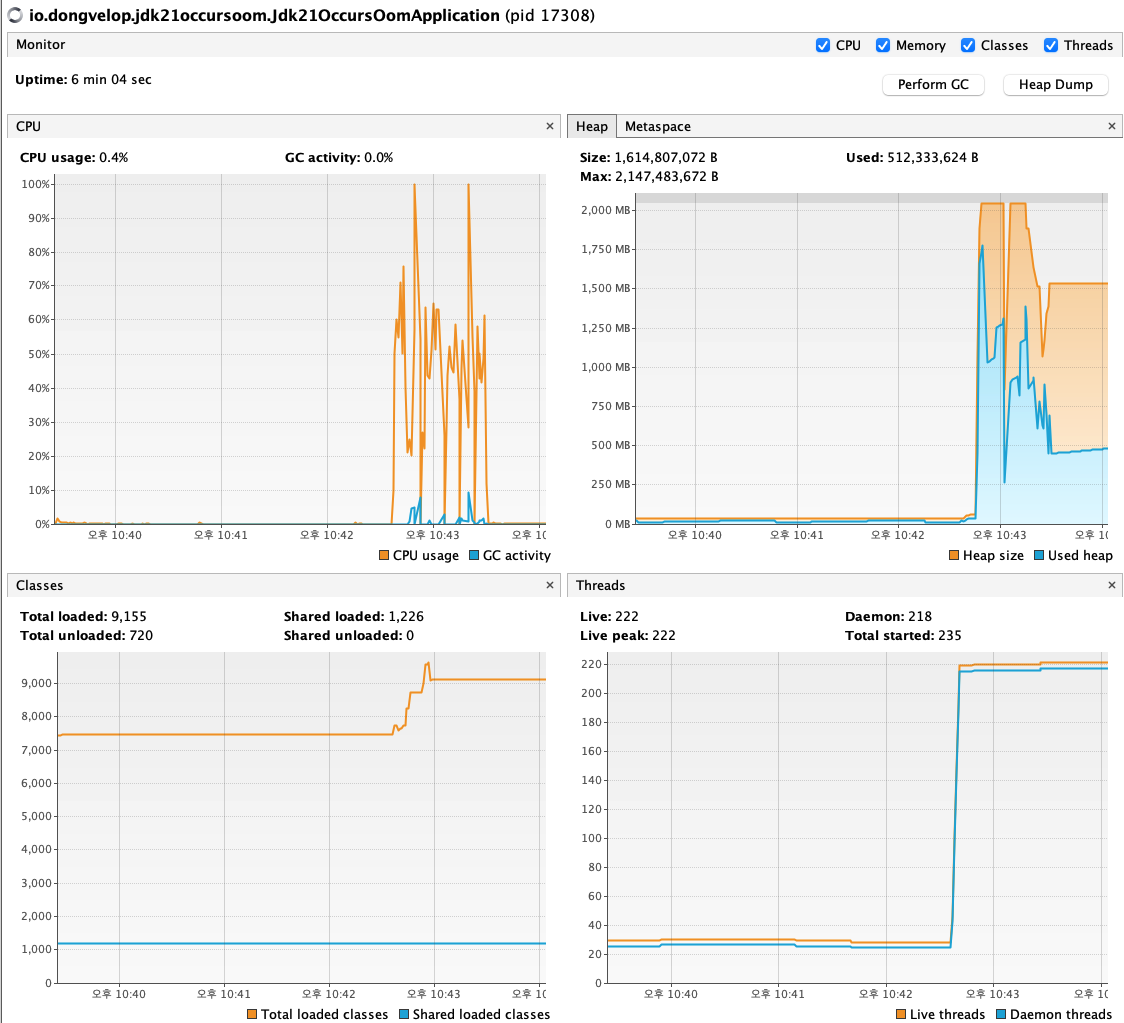
jcmd 메모리 분석 결과
힙 메모리가 약 1.5GB정도 증가하고, 다이렉트 메모리가 2MB 정도 증가한 것을 확인할 수 있다.
$ jcmd 17308 VM.native_memory summary.diff
17308:
Native Memory Tracking:
(Omitting categories weighting less than 1KB)
Total: reserved=3659277KB +209134KB, committed=2040773KB +1810298KB
- Java Heap (reserved=2097152KB, committed=1576960KB +1531904KB)
(mmap: reserved=2097152KB, committed=1576960KB +1531904KB)
- Other (reserved=2050KB +2008KB, committed=2050KB +2008KB)
(malloc=2050KB +2008KB #407 +401)
...4-7. JDK 17 vs JDK 21 : 메모리 분석 결과 요약
| JDK 17 | JDK 21 | |
|---|---|---|
| 요청 전 | 힙 메모리 사용량이 15MB ~ 30MB 사이를 유지 | 힙 메모리 사용량이 10MB ~ 40MB 사이를 유지 |
| 요청 결과 | 대부분의 이미지 저장 요청이 성공 | 대부분의 이미지 저장 요청이 실패 |
| 요청 후 | 점차 힙 메모리 사용량이 낮아짐 | 힙 메모리 사용량이 낮아지지 않음 |
| 힙 메모리 변화 | 약 1.5GB 증가 | 약 2GB 증가 |
| 다이렉트 메모리 변화 | 약 2MB 증가 | 약 17MB 증가 |
5. 원인 분석
5-1. Default GC(Garbage Collector)의 변경은 아닌지?
JDK 15에서 큰 메모리를 사용할 경우에 G1 GC보다 성능이 좋은 ZGC가 추가되었다.
따라서, JDK 버전 간에 기본적으로 적용되는 GC가 달라진 것은 아닐까?
→ 아직까지는 JDK 17과 JDK 21에 모두 G1 GC가 기본으로 적용된다.
5-2. 소스 코드 분석
런타임 시에 MultipartFile.getBytes() 호출 시 동작되는 소스 코드를 비교해보자.
MultipartFile은 인터페이스이므로, 런타임 시에 StandardMultipartFile이 개입된다.
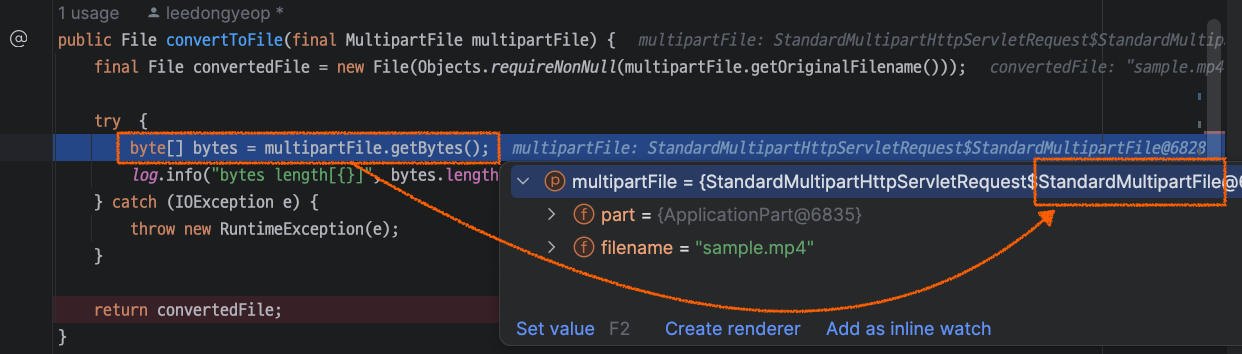
StandardMultipartFile.getBytes() 는 FileCopyUtils.copyToByteArray()를 호출한다.
private static class StandardMultipartFile implements MultipartFile, Serializable {
...
public byte[] getBytes() throws IOException {
**return FileCopyUtils.copyToByteArray(this.part.getInputStream());**
}
}copyToByteArray() 의 매개변수로는 InputStream의 구현체인 ChannelInputStream이 주입된다.
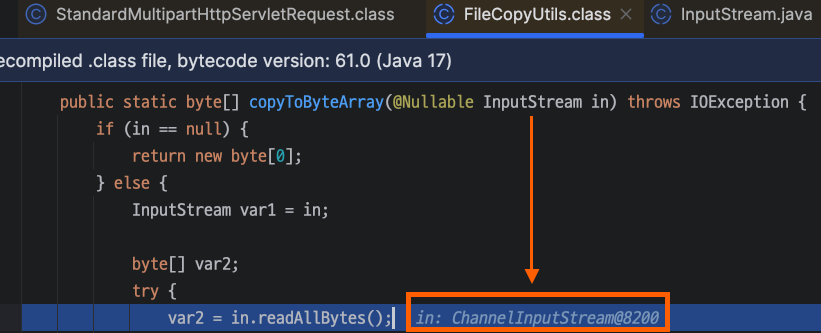
이제 FileCopyUtils.copyToByteArray(~~) 메서드를 살펴보자.
매개변수로 넘어온 InputStream이 null이 아니면, readAllBytes()를 호출해 바이트 배열로 읽어오도록 동작한다.
public abstract class FileCopyUtils {
public static final int BUFFER_SIZE = 8192;
...
public static byte[] copyToByteArray(@Nullable **InputStream in**) throws IOException {
...
byte[] var2;
try {
**var2 = in.readAllBytes(); // <---------- THIS**
} catch (Throwable var5) { ... }
if (in != null) {
in.close();
}
return var2;
}
}여기서부터 JDK 17과 JDK 21이 차이를 보인다.
-
JDK 17 :
InputStream.readAllBytes()를 호출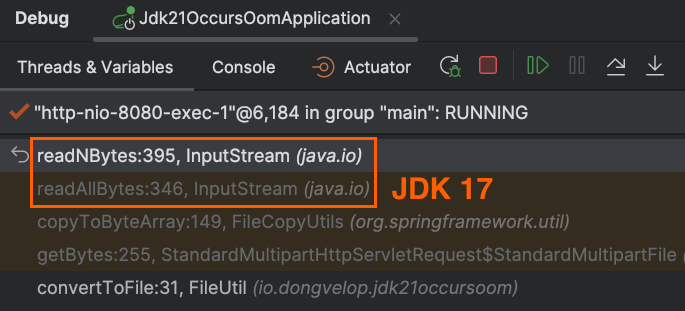
-
JDK 21 :
ChannelInputStream.readAllBytes()를 호출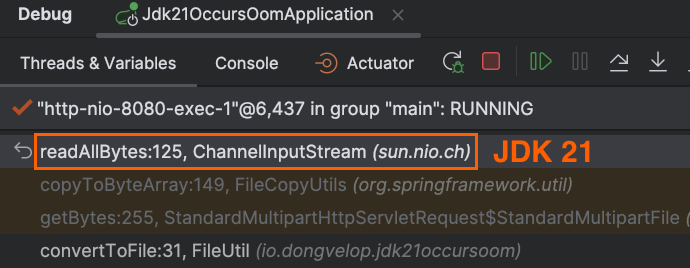
2021/10/02 OpenJDK Commit에서 ChannelInputStream 클래스에 readAllBytes() 메서드가 추가된 것을 볼 수 있다.
- https://github.com/openjdk/jdk/commit/0786d8b7b367e3aa3ffa54a3e339572938378dca
- → JDK 18부터 적용된 것으로 보임
그렇다면
InputStream.readAllBytes()과ChannelInputStream.readAllBytes()의 동작은 어떻게 다를까?
먼저 InputStream의 동작 방식을 알아보자.
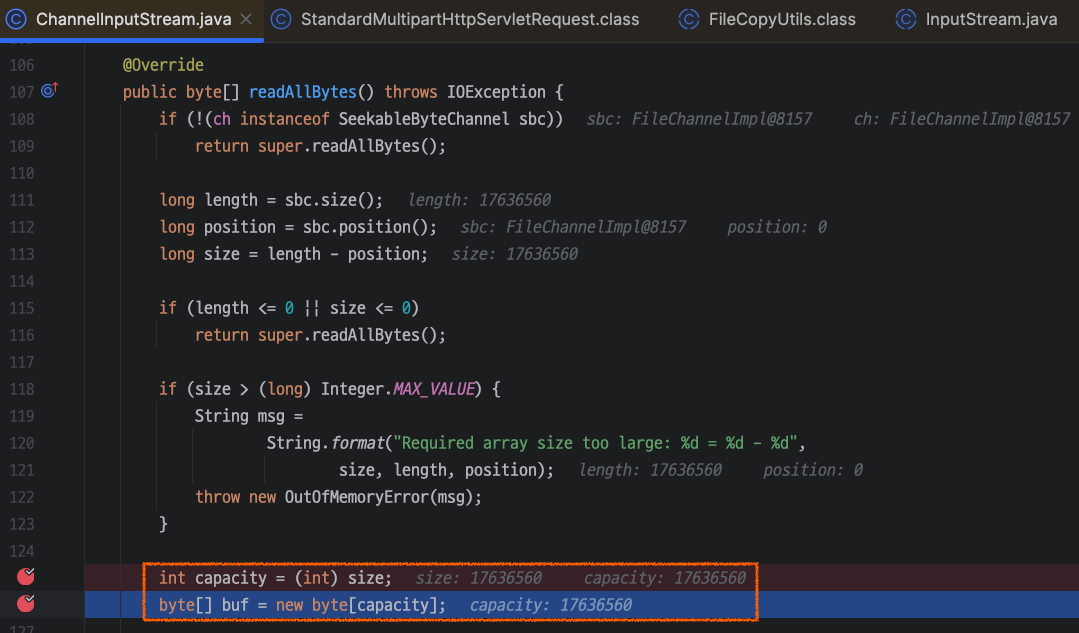
readAllBytes()→readNBytes()호출- 버퍼 할당 : 남은 버퍼의 사이즈와 디폴트 버퍼 사이즈 중 작은 크기로 할당
public abstract class InputStream implements Closeable {
private static final int MAX_SKIP_BUFFER_SIZE = 2048;
private static final int DEFAULT_BUFFER_SIZE = 16384;
public byte[] readAllBytes() throws IOException {
return readNBytes(Integer.MAX_VALUE);
}
public byte[] readNBytes(int len) throws IOException {
if (len < 0) {
throw new IllegalArgumentException("len < 0");
}
List<byte[]> bufs = null;
byte[] result = null;
int total = 0;
int remaining = len;
int n;
do {
**byte[] buf = new byte[Math.min(remaining, DEFAULT_BUFFER_SIZE)]; // <----- THIS**
int nread = 0;
// read to EOF which may read more or less than buffer size
while ((n = read(buf, nread, Math.min(buf.length - nread, remaining))) > 0) {
nread += n;
remaining -= n;
}
...
}
}ChannelInputStream 의 동작 방식
- 버퍼 할당 : 요청을 받은 FileChannelImple의 사이즈를 그대로 사용한다.
- → 17.6MB의 동영상을 요청했으니, 버퍼 사이즈가 17.6MB가 된다.
5-3. 버퍼 크기가 미치는 영향
-
처음 요청이 들어오면 요청을 처리하는 스레드의 캐시에 메모리가 할당된다.
- 이때 캐시에 담긴 버퍼 메모리는 서블릿 컨테이너의 스레드풀에 저장되어 메모리가 해제되지 않는다.
-
현재 이 프로젝트 기준으로, 17.6MB 크기의 동영상을 보내는 상황을 기준으로 한다.
- JDK 17을 사용 시, 캐시에 담긴 버퍼 사이즈는 16384Byte (=
InputStream.DEFAULT_BUFFER_SIZE값) - JDK 21을 이용 시, 캐시에 담긴 버퍼 사이즈는 17.6MB (= 요청 보낼 때 사용한 동영상 파일 크기)
- JDK 17을 사용 시, 캐시에 담긴 버퍼 사이즈는 16384Byte (=
-
Spring Boot의 내장 WAS를 Tomcat을 이용할 경우,스레드 풀의 최대 크기는 기본 값이 200이다.
-
server.tomcat.threads.max속성을 확인하자. -
Undertow를 이용할 경우는 아래와 같이 설정할 수 있다.
server: undertow: io-threads: 8 # 기본 값 : 논리 프로세서 수의 2배 worker-threads: 64 # 기본 값 : IO 스레드 수 * 8
-
스레드가 200개가 존재하고, 동일한 스레드 그룹을 요청할 경우에 필요한 다이렉트 버퍼 메모리 크기는 아래와 같다.
- JDK 17 사용시 → 3.2MB씩 나눠서 처리 (= 16384Byte * 200)
- JDK 21 사용시 → 3.5GB (= 17.6MB * 200) 필요
5-4. 이 문제를 피하는 방법
바이트를 읽을 때 고정된 크기의 버퍼로 읽기
private File convertToFile(MultipartFile multipartFile) {
File copiedFile = new File(Objects.requireNonNull(multipartFile.getOriginalFilename()));
try (
InputStream is = multipartFile.getInputStream();
OutputStream os = new FileOutputStream(copiedFile)
) {
**byte[] buffer = new byte[10240];**
int read;
while ((read = is.read(buffer)) > 0) {
os.write(buffer, 0, read);
}
} catch (IOException e) {
// 예외 처리
}
return copiedFile;
}파일 변환시
MultipartFile.transferTo()메서드 이용하기 : 가장 성능이 좋은 방법
private File convertToFile(MultipartFile multipartFile) {
File copiedFile = new File(Objects.requireNonNull(multipartFile.getOriginalFilename()));
try {
multipartFile.transferTo(copiedFile.toPath());
} catch (IOException e) {
// 예외 처리
}
return copiedFile;
}transferTo() 메서드도 내부 동작을 살펴보면, 고정된 크기(16384 byte)의 버퍼로 읽고 쓰는 것을 확인할 수 있다.
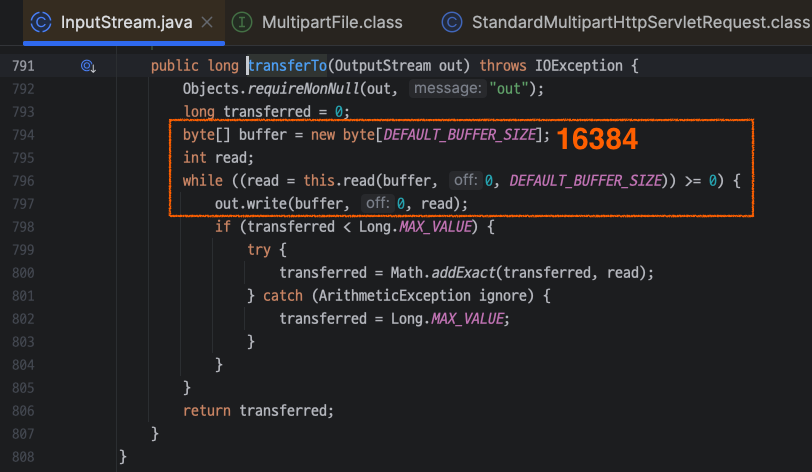
6. 결론
JDK 18부터 ChnnelInputStream 클래스에 readAllBytes() 메서드가 추가되어, Out of Memory Error가 발생한다.
JDK 17까지는 발생하지 않지만, 추후 버전업을 진행하게 될 경우 가장 성능이 좋은 transferTo() 메서드를 활용하자.
7. 참고자료
