메시지큐의 기본 개념에 대해 설명한 뒤, 아래 나열한 통합 기술들에 대해 설명합니다.
각 상황에 맞는 기술들이 있으니 선택할 때, 고려해야 할 사항들을 보시길 바랍니다.
- Spring Integration
- RabbitMQ
- Apache Kafka
- Apache ActiveMQ
- Apache Pulsar
- Apache Camel
- AWS SQS
RabbitMQ, Apache Kafka, Apache ActiveMQ의 경우 예시 코드가 있습니다.
모든 예제 코드는 Github Repository에서 확인하실 수 있습니다.
1. 메세지 큐 기본 개념

1-1. 메세지 큐란?
- 메시지 큐는 시스템 간 데이터 통신을 위한 중요한 컴퓨팅 구성 요소입니다.
- 송신자와 수신자 간의 통신을 분리하여 느슨하게 결합된 아키텍처를 가능하게 합니다.
- 이는 비동기적으로 데이터를 전달하고 처리할 수 있도록 합니다.
1-2. 메세지 큐의 개념
- 메시지 큐는 데이터를 보내는 곳과 받는 곳 사이에서 중간 매개체 역할을 합니다.
- 송신자는 메시지를 큐에 보내고, 수신자는 큐에서 메시지를 받아 처리합니다.
- 이러한 방식으로 송수신자 간의 결합도를 낮추고, 시스템의 확장성과 유연성을 높입니다.
1-3. 메세지 큐의 구성 요소
- 메시지: 데이터의 단위로, 큐를 통해 전달되는 정보입니다.
- 큐: 메시지를 저장하고 관리하는 데이터 구조입니다.
- 송신자(Producer): 메시지를 생성하여 큐에 보내는 주체입니다.
- 수신자(Consumer): 큐에서 메시지를 가져와 처리하는 주체입니다.
1-4. 메세지 큐의 활용
- 비동기 통신: 송신자가 메시지를 보낸 후에도 즉시 결과를 기다리지 않고 다른 작업을 수행할 수 있습니다.
- 분산 시스템: 여러 시스템 간의 데이터 통신을 효율적으로 처리할 수 있습니다.
- 이벤트 기반 아키텍처: 이벤트에 따라 메시지를 생성하고 처리하여 시스템을 구축할 수 있습니다.
1-5. 메시지 큐의 장점
- 신뢰성: 메시지 전송의 신뢰성을 보장하여 데이터의 손실이나 중복 전송을 방지합니다.
- 확장성: 대용량의 데이터를 효율적으로 처리하고 시스템을 확장할 수 있습니다.
- 유연성: 다양한 프로토콜 및 데이터 형식을 지원하여 상호 작용을 용이하게 합니다.
1-6. 메세지 큐 선택 시 고려 사항
- 성능
- 처리량, 지연 시간, 처리 속도
- 대규모 시스템에서는 높은 처리량과 낮은 지연 시간을 제공하는 메시지 큐가 필요
- 확장성
- 시스템이 확장 가능한지, 즉 새로운 노드를 추가하거나 노드를 확장하는 과정이 얼마나 간편한지
- 지원하는 메시지 유형
- 다양한 종류의 데이터(텍스트, 바이너리, JSON, XML 등)를 전달할 수 있는 능력
- 관리 용이성
- 모니터링, 로깅, 경고, 클러스터 관리, 스케일링 보안 설정 등
2. Spring Integration

- 스프링 프레임워크 기반의 엔터프라이즈 통합 솔루션으로, 각종 프로토콜 및 메시지 브로커와의 통합을 지원합니다.
- 메시지 기반의 마이크로서비스 아키텍처를 구축하기 위한 다양한 기능을 제공합니다.
2-1. Spring Integration 핵심 개념
- 메시지: 시스템 간 데이터 교환의 기본 단위
- 채널: 메시지를 보내고 받는 대상을 정의하는 데 사용되는 통신 채널
- 엔드포인트: 메시지가 송수신되는 지점으로, 메시지의 소스 및 대상
- 필터 및 변환기: 메시지를 필터링하거나 변환하는 데 사용되는 구성 요소로, 메시지의 내용을 변경하거나 처리
- 라우터 및 분배기: 메시지의 라우팅을 담당하며, 메시지를 다른 채널로 분배하는 데 사용
- 어댑터: 외부 시스템과의 통합을 위한 인터페이스로, 다양한 프로토콜 및 데이터 형식을 지원
2-2. Spring Integration 장점
- 스프링 생태계 통합
- Spring Integration은 스프링 프레임워크와 긴밀하게 통합되어 있어, 스프링 기반 애플리케이션과의 연동이 용이
- → 스프링의 다양한 기능 및 특징을 활용할 수 있음.
- 다양한 프로토콜 및 데이터 형식 지원
- Spring Integration은 다양한 프로토콜 및 데이터 형식을 지원하여 시스템 간 통신을 유연하게 처리할 수 있습니다.
- 이는 메시지 큐뿐만 아니라 다른 시스템과의 통합에도 유용합니다.
- 엔터프라이즈 통합 패턴 구현
- Spring Integration은 엔터프라이즈 통합 패턴을 쉽게 구현할 수 있는 다양한 컴포넌트와 모듈을 제공
엔터프라이즈 통합 패턴(Enterprise Integration Patterns, EIP)
- 엔터프라이즈 시스템 간의 통합을 설계하고 구현하기 위한 공통된 문제 해결 방법을 정의한 패턴
- 시스템 간의 통합은 주로 메시지를 통해 이루어 지며, 메시지 기반의 아키텍처에서 특히 유용
2-3. Spring Integration 단점
- 학습 곡선
- 다양한 기능과 설정 옵션들이 제공되어 강력한 통합을 가능하게 한다.
- → 이로 인해 초보자에게는 학습이 어려울 수 있다.
- 성능
- Spring Integration은 가벼운 통합 솔루션이 아니며, 대규모 애플리케이션에서는 성능 이슈가 발생할 수 있다.
- 특히 고성능 및 대용량 데이터 처리를 요구하는 환경에서는 다른 솔루션을 고려해야 할 수 있습니다.
3. RabbitMQ

- AMQP(Advanced Message Queuing Protocol)의 구현체로, 신뢰성과 확장성이 뛰어난 오픈 소스 메시지 브로커
3-1. RabbitMQ 장점
- 신뢰성 높은 메시지 전달
- 메시지를 안전하게 전달하는데 중점을 두고 있으며, 메시지의 손실이나 중복 전송을 방지하기 위한 다양한 기능을 제공
- 메세지를 디스크에 저장하여 지속성을 보장
- 다양한 프로토콜 지원
- RabbitMQ는 다양한 프로토콜을 지원하여 다른 시스템과의 통합이 용이함.
- HTTP, AMQP를 비롯하여 STOMP, MQTT 등 다양한 프로토콜을 지원
- Kafka의 경우, 대량의 이벤트 스트리밍에 적합하므로 AMQP나 STOMP를 지원하지 않음.
- 고가용성 및 확장성
- RabbitMQ는 클러스터링을 통해 고가용성을 제공하고, 필요에 따라 노드를 추가하여 시스템을 확장 가능 → 덕분에 대규모 및 실시간 데이터 처리를 지원
- 클러스터링이란?
- 여러 노드를 하나의 그룹으로 묶어 단일 시스템처럼 동작하는 컴퓨터 구성 기술
- 하나의 노드가 다운되어도, 다른 노드들이 메시지를 계속 처리할 수 있음.
- 클러스터링이란?
- RabbitMQ는 클러스터링을 통해 고가용성을 제공하고, 필요에 따라 노드를 추가하여 시스템을 확장 가능 → 덕분에 대규모 및 실시간 데이터 처리를 지원
- 관리 및 모니터링 기능
- RabbitMQ는 관리 및 모니터링을 위한 다양한 도구와 API를 제공하여 시스템의 운영 및 관리가 용이
- RabbitMQ Management UI : 큐,교환,바인딩,연결 등의 리소스를 시각적으로 확인 가능
- Management Plugin : 플러그인을 활성화하여 RabbitMQ 클러스터를 관리하는 RESTful API를 제공
- Command Line Tools (
rabbitmqctl) - Prometheus Exporter Plugin & Grafana Dashboard
- RabbitMQ는 관리 및 모니터링을 위한 다양한 도구와 API를 제공하여 시스템의 운영 및 관리가 용이
3-2. RabbitMQ 단점
- 고가용성 설정이 복잡
- RabbitMQ의 고가용성 설정 및 클러스터링 구성은 다소 복잡하여 초기 설정이 어려울 수 있다.
- 관리 비용
- RabbitMQ를 운영하고 관리하는 데 필요한 인력 및 자원이 많을 수 있어, 대규모 및 복잡한 환경에서는 관리 비용이 증가한다.
- 성능
- RabbitMQ는 대용량 및 고성능 데이터 처리에는 적합하지만, 다른 솔루션에 비해 처리량이 떨어질 수 있다.
- 특히 매우 높은 처리량이 필요한 경우 성능 이슈가 발생할 수 있다.
4. Apache Kafka

- 대용량의 데이터를 실시간으로 스트리밍 처리하기 위한 분산 스트리밍 플랫폼
- 대규모 데이터 처리 및 실시간 데이터 분석에 적합한 오픈 소스 솔루션
4-1. Apache Kafka 장점
- 높은 처리량과 낮은 지연 시간
- Apache Kafka는 대용량의 데이터를 효율적으로 처리하고 낮은 지연 시간으로 데이터를 전달할 수 있다.
- → 이는 높은 처리량과 실시간 데이터 스트리밍에 적합하다.
- 확장성
- Kafka는 분산 아키텍처를 기반으로 하여 수평적으로 확장이 용이하다.
- 클러스터에 노드를 추가함으로써 처리량과 스토리지를 쉽게 확장할 수 있다.
- 내결함성
- Kafka는 메시지를 클러스터 내에 각각의 브로커 노드에 분산 저장한다.
- 또한 메모리에 저장된 데이터를 주기적으로 디스크에 저장하여 데이터의 지속성을 보장.
- 따라서 한 개의 브로커가 다운되더라도 시스템 전체에 영향을 미치지 않는다.
- Kafka는 메시지를 클러스터 내에 각각의 브로커 노드에 분산 저장한다.
- 유연한 데이터 보존
- Kafka는 메시지를 영속적으로 보존하여 필요한 만큼 오랫동안 데이터를 보관할 수 있다.
- → 이를 통해 데이터 리플레이, 재처리 및 분석에 활용할 수 있다.
4-2. Apache Kafka 단점
- 복잡한 설정 및 관리
- 클러스터의 구성, 파티션의 관리, 복제 및 보존 정책 등을 설정해야 하므로 초기 설정 및 운영이 다소 복잡하다.
- 높은 메모리 요구
- Kafka는 메시지를 메모리에 보관하므로, 대용량 데이터 처리를 위해서는 충분한 메모리가 필요
- 데이터 유실 가능성
- 설정에 따라 디스크에 영속화되기 전에 데이터가 메모리에만 저장된다.
- 따라서 예기치 않은 하드웨어 또는 네트워크 문제가 발생할 경우에는 데이터의 일부가 손실될 수 있다.
- 데이터 처리 지연
- 메시지를 디스크에 영속화하기 위해 별도의 커밋 프로세스를 거친다.
- 이러한 커밋 작업이 데이터의 지속성을 보장하지만, 데이터 처리에 약간의 지연을 초래한다.
5. Apache ActiveMQ

- 오픈 소스 메시지 브로커로서, JMS(Java Message Service) 표준을 준수하는 대규모 메시지 큐 시스템
5-1. Apache ActiveMQ 장점
- JMS 표준 준수
- Apache ActiveMQ는 JMS 표준을 지원하여 Java 애플리케이션과의 통합이 용이.
- → 이는 Java 개발자에게 익숙한 API를 사용하여 메시지 큐를 쉽게 구축할 수 있음을 의미.
- 다양한 프로토콜 지원
- ActiveMQ는 다양한 프로토콜을 지원하여 다른 시스템과의 통합이 용이.
- OpenWire, STOMP, MQTT, AMQP 등의 프로토콜을 지원하여 다양한 클라이언트와의 상호 운용성을 제공
- 관리 및 모니터링 기능
- ActiveMQ는 다양한 관리 및 모니터링 도구를 제공하여 클러스터의 상태를 모니터링하고 운영을 관리 가능
- 웹 기반 콘솔 및 JMX를 통한 모니터링이 가능
- 확장성
- ActiveMQ는 대규모 메시지 큐 시스템을 구축할 수 있도록 확장성을 제공
- 클러스터링 및 분산 아키텍처를 통해 높은 가용성과 확장성을 보장
5-2. Apache ActiveMQ 단점
- 성능
- Apache ActiveMQ는 다른 메시지 큐 시스템에 비해 상대적으로 성능이 떨어질 수 있다.
- 특히 고부하 환경에서는 처리량이 제한될 수 있다.
- 확장성
- 대규모 클러스터링 및 확장성 측면에서 Apache Kafka와 비교할 때 제한적
- 큰 규모의 클러스터를 구성하거나 수천 개의 연결을 처리해야 하는 경우, 성능 저하 및 확장 어려움이 발생할 수 있음.
- 복잡한 설정
- ActiveMQ의 초기 설정 및 운영이 다소 복잡할 수 있다.
- 특히 클러스터링 및 고가용성 설정이 추가적인 노력과 관리를 필요
- 메모리 사용량
- ActiveMQ는 메시지를 메모리에 보관
- → 대용량 데이터 처리에는 메모리 사용량이 증가할 수 있다.
6. Apache Pulsar

- Yahoo!에서 개발한 클라우드 기반의 메시징 시스템
- 확장성과 성능이 뛰어난 실시간 메시지 스트리밍 및 메시지 큐 시스템
6-1. Apache Pulsar 장점
- 뛰어난 확장성
- Apache Pulsar는 분산 아키텍처를 기반으로 하여 높은 확장성을 제공
- 브로커를 수평적으로 확장할 수 있으며, 토픽과 파티션을 동적으로 추가할 수 있다.
- 수평적 확장 : 클러스터에 새로운 노드를 추가하여 처리 능력을 증가시킴을 말함.
- Apache Kafka의 경우는 토픽이 생성할 때 설정되며, 런타임에서는 변경 불가.
- → 이는 대규모 및 실시간 데이터 처리에 적합!
- 멀티 토픽과 멀티 서브스크립션 지원
- Pulsar는 여러 토픽과 여러 서브스크립션을 효과적으로 처리 가능.
- → 이는 다양한 데이터 스트림과 다양한 구독자들 간의 복잡한 상호작용을 지원
- 멀티 테넌시
- 여러 개의 다른 애플리케이션 또는 사용자가 동시에 데이터를 사용할 수 있는 멀티 테넌시를 지원
- 각각의 애플리케이션은 독립적으로 데이터를 사용할 수 있다.
- 비동기 복제
- 데이터를 여러 곳에 비동기적으로 복제하여 안정성을 보장.
- 이를 통해 하나의 서버가 고장나더라도 데이터가 안전하게 보존된다.
- 서버리스 및 클라우드 네이티브 지원
- Pulsar는 서버리스 아키텍처와 클라우드 네이티브 환경에 적합한 설계를 갖춤.
- 내장형 함수(Pulsar Functions)를 사용하면 데이터를 실시간으로 처리하고 분석하는 함수를 작성 가능
- 이를 통해 별도의 서버 없이도 데이터를 처리하고 비즈니스 로직을 실행할 수 있다.
6-2. Apache Pulsar 단점
- 학습 곡선
- Apache Pulsar는 비교적 새로운 기술이므로 학습 곡선이 가파를 수 있다.
- 특히 기존 메시지 큐 시스템에 익숙한 사용자들에게는 적응하기 어려울 수 있다.
- 아키텍처의 차이
- Kafka : 데이터를 토픽 및 파티션으로 구성된 브로커에 저장
- Pulsar : 토픽과 파티션을 분리하여 별도의 역할을 부여
- 기능 및 용어
- Pulsar는 메시지의 수명을 관리하기 위해 영속성과 데이터 보관정책을 사용
- 아키텍처의 차이
- 성숙도 부족
- Pulsar는 상대적으로 성숙도가 낮은 편이며, 일부 기능이나 도구의 부족할 수 있다.
- 생태계 부족
- 기존에 비해 Apache Pulsar의 생태계는 아직 크게 발달하지 않았다.
- 이는 추가적인 플러그인, 라이브러리 및 도구의 개발이 필요함을 의미
7. Apache Camel

- 엔터프라이즈 통합 패턴을 구현하기 위한 오픈 소스 프레임워크로 메시지 기반의 애플리케이션을 쉽게 구축
7-1. Apache Camel 장점
- 엔터프라이즈 통합 패턴(EIP) 지원
- 엔터프라이즈 통합 패턴을 다양하게 지원하여 복잡한 통합 시나리오를 쉽게 구현 가능.
- 라우팅, 필터링, 변환, 집계, 분할 및 병합 등의 패턴을 제공하여 유연하고 확장 가능한 통합 솔루션을 구축 가능
- 다양한 프로토콜 및 데이터 형식 지원
- Apache Camel은 다양한 프로토콜과 데이터 형식을 지원하여 다른 시스템과의 통합이 용이
- HTTP, FTP, JMS, AMQP, MQTT 등 다양한 프로토콜을 지원하며, JSON, XML, CSV 등 다양한 데이터 형식을 처리 가능
- 스프링 통합
- Apache Camel은 스프링 프레임워크와의 통합을 강점으로 가진다.
- 풍부한 커뮤니티 및 생태계
- Apache Camel은 활발한 커뮤니티와 다양한 확장 모듈을 제공하여 개발자들이 필요한 기능을 쉽게 확장 가능다.
- 또한, 다양한 엔터프라이즈 시스템과의 통합을 위한 컴포넌트 및 어댑터가 제공된다.
7-2. Apache Camel 단점
- 학습 곡선
- Apache Camel은 다양한 패턴과 구성 요소를 이해하기 위해 초기 학습 곡선이 가파를 수 있습니다.
- 설정 및 디버깅의 복잡성
- Apache Camel은 유연하고 강력한 기능을 제공하지만, 구성 파일의 작성 및 디버깅이 다소 복잡하다.
- 특히 복잡한 통합 시나리오를 구현할 때는 설정의 복잡성이 증가할 수 있습니다.
- 성능
- Apache Camel은 다른 메시지 큐 시스템에 비해 처리량이나 성능 면에서 다소 느릴 수 있다.
- 특히 고부하 환경에서는 성능 이슈가 발생할 수 있다.
8. AWS SQS

- AWS SQS(Amazon Simple Queue Service)
- 클라우드에서 호스팅되는 완전 관리형 메시지 대기열 서비스
8-1. AWS SQS의 장점
- 완전 관리형 서비스
- 서버 프로비저닝, 관리, 유지보수 등을 사용자가 신경 쓸 필요가 없다.
- 이를 통해 사용자는 메시지 대기열을 쉽게 설정하고 사용할 수 있다.
- 신뢰성 및 확장성
- 메시지는 여러 가용 영역에 걸쳐 저장되며, 이를 통해 메시지 손실을 방지하고 가용성을 보장
- 또한, SQS는 대기열을 자동으로 확장하여 수십만 개의 메시지를 처리할 수 있다.
- 다양한 전송 방식
- SQS는 여러 전송 방식을 지원하여 다양한 용도에 활용할 수 있다.
- 표준 대기열은 최소 한 번 처리 보장을 제공하고, FIFO(First-In-First-Out) 대기열은 정확한 순서대로 메시지를 전달.
- 복구 가능한 메시지
- SQS는 메시지를 자동으로 백업하고 복구할 수 있다.
- 메시지가 처리되지 않으면 일정 시간 동안 다시 대기열로 전송되어 다시 처리 가능
- 비용 효율적
- 사용자는 필요한 만큼의 리소스만 사용하고 비용을 지불하므로 비용이 효율적.
- 또한, AWS의 사용량 기반 요금 체계를 통해 사용자는 실제 사용한 만큼만 비용을 지불
8-2. AWS SQS의 단점
- 지연
- SQS는 메시지 전송 및 수신을 위해 HTTP 또는 HTTPS 프로토콜을 사용하며, 이는 가끔씩 더 긴 지연을 유발할 수 있다.
- 특히 매우 빠른 응답 시간이 필요한 애플리케이션의 경우 이 지연이 문제가 될 수 있다.
- 리스너의 복잡성:
- SQS를 사용할 때 메시지를 처리하는 리스너 애플리케이션을 작성해야 한다.
- 이 과정에서 메시지 처리 및 오류 처리 로직을 구현해야 하며, 이는 약간의 추가 복잡성을 유발.
- 제한된 시스템 메트릭
- SQS는 제한된 시스템 메트릭을 제공하므로 애플리케이션 성능을 모니터링하고 튜닝하는 데 어려움을 겪을 수 있다.
- 따라서 애플리케이션의 성능을 최적화하려면 추가적인 모니터링 및 디버깅 도구가 필요할 수 있다.
- 비용
- 사용하는 데 일정한 비용이 발생
- → 메시지의 양이 많거나, 메시지 크기가 큰 경우 비용이 증가할 수 있다.
9. Kafka만의 다른 동작방식
RabbitMQ를 예시로 비교하였습니다.
가장 큰 차이점
- RabbitMQ : 전통적인 메시지 브로커
- Kafka : 이벤트 스트리밍 플랫폼
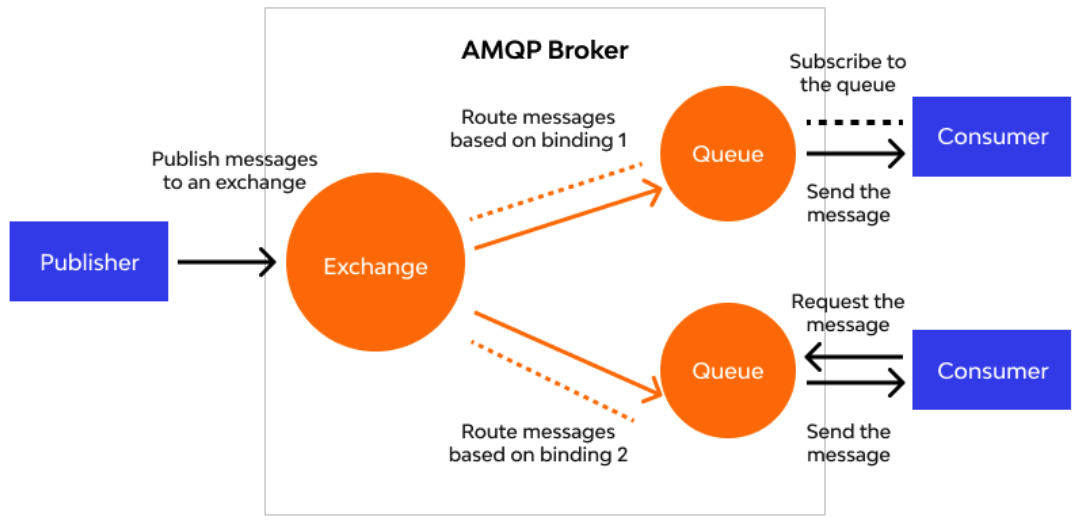
메시지 브로커의 동작 방식
- 발행자가 Message Exchange에 메시지를 보내면, 정해진 규칙에 따라 큐에 라우팅
- 컨슈머들은 메시지를 구독하여 처리
- 이후, 컨슈머가 메시지를 가져가면 큐에는 더 이상 남지 않고 사라짐
메시지 브로커의 단점
- 소비자와 메시지 브로커의 결합력이 높아져, 트래픽이 증가했을 때 수평적 확장이 어렵다.
- 이벤트 메시지가 성공적으로 전달되었다고 판단될 경우, 큐에서 메시지가 삭제된다.
- → 후에 다시 이벤트를 받기가 어렵다.
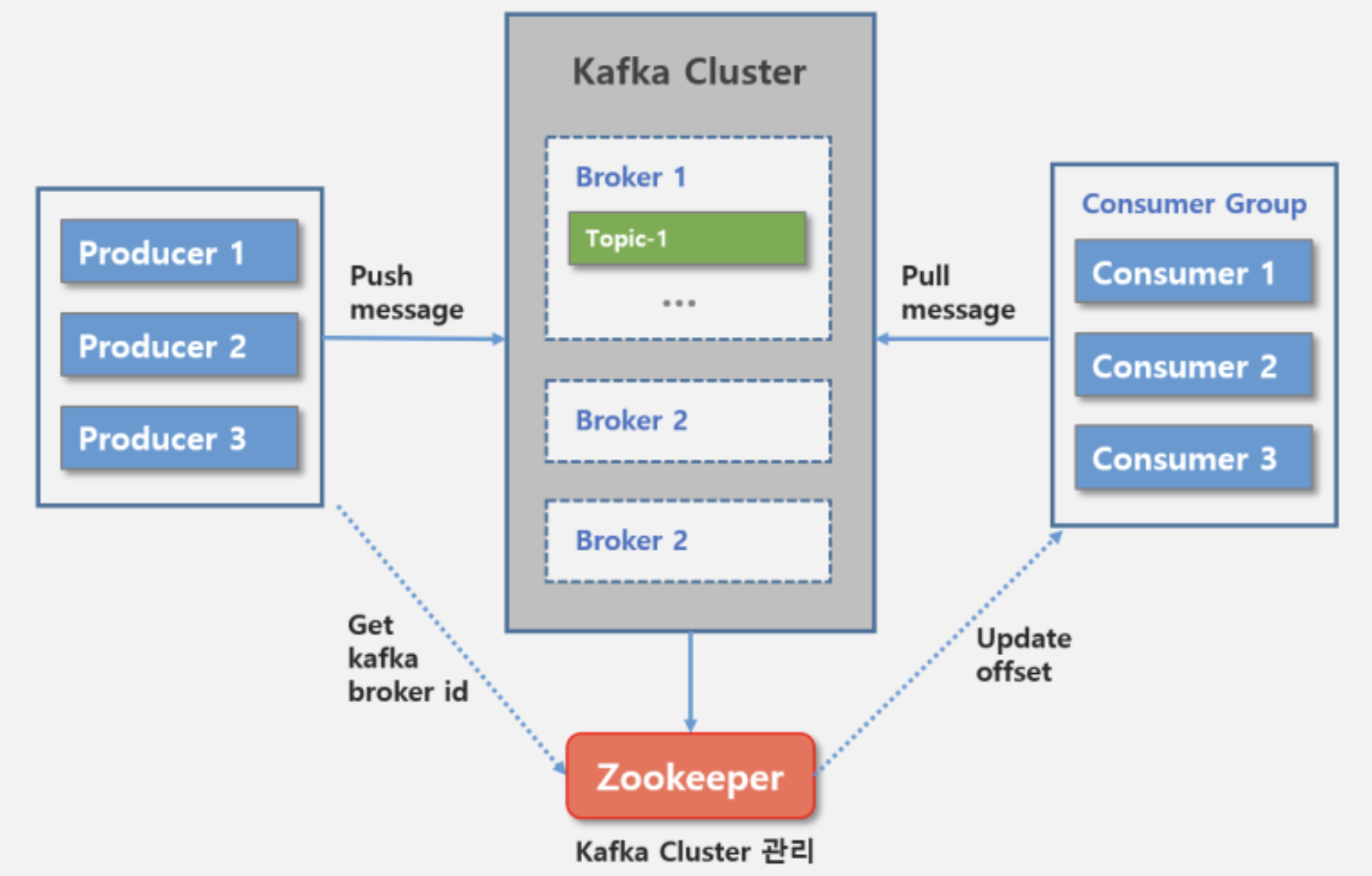
카프카(이벤트 스트리밍 플랫폼)의 동작 방식
- 메시지 브로커와 다르게 토픽이라는 것이 Event Streamer에 저장됨
- 발행자가 이벤트를 생성하면, 토픽이라고 불리는 이벤트의 레코드 로그를 Streamer에 순서대로 기록
- 그 후, 해당 토픽을 구독한 컨슈머에게 전달됨
- 컨슈머가 토픽을 가져간 후에도, 이벤트 스트림에서 토픽을 계속 유지하여 추후 다시 발행할 수 있음.
RabbitMQ와 Kafka 비교
| RabbitMQ | Kafka | |
|---|---|---|
| 성능 | 초당 4,000 ~ 10,000개의 메시지 처리 가능 | 초당 1,000,000 개의 메시지 처리 가능 |
| 메시지 생명주기 | 소비되는 순간 삭제 | 정책 기반(설정 한 기간만큼) |
| 트랜잭션 데이터 | 중복 메시지 발송 및 메시지 손실 가능성 존재 | 순서 보장 및 메시지 유실 가능성이 적음 |
| 운영 데이터 | 라우팅, 클러스터링, 메시지 확인 등의 운영 데이터 처리에 강점 | 대량의 실시간 로그 또는 스트림 데이터 처리에 강점 |
| 클러스터링 | 클러스터링 지원, 노드 간 메시지 복제로 고가용성 제공 | 클러스터링 지원, 자동 복제와 파티셔닝을 통해 고가용성 및 장애 복구 기능 제공 |
| 메시지 모델 | Queue와 Topic 모델 지원 | Topic 모델만 지원 |
| 스케일링 | 스케일 업에 적합 | 스케일 아웃에 적합, 대량의 데이터를 처리할 수 있는 높은 확장성 |
10. 참고자료
- hihello(Velog) : Spring Integration Framework
- f-lab : 메시지 큐의 실제 적용 사례
- 최범균 Youtube : kafka 조금 아는 척하기 1
- spring-kafka docs
- Kafka 개념과 Spring Boot + Kafka 적용하기
- https://dkswnkk.tistory.com/705
- https://devocean.sk.com/blog/techBoardDetail.do?ID=164007
- https://medium.com/@underwater2/docker-compose로-kafka-cluster-구성하기-10863606c526

백엔드 개발자로 등 따숩고 배 부르게 되는 그 날까지