오늘은 그래프를 순회(traversal)하는 알고리즘인 DFS(깊이 우선 탐색)과 BFS(너비 우선 탐색)에 대해 공부해보려고 합니다.
먼저 알고리즘을 배우기전에 그래프에 대한 기본적인 개념, 그리고 DFS에서 사용되는 스택과 재귀함수, BFS에 사용되는 큐에 대해 간단히 짚고 넘어가려고 합니다.
🎓 사전 지식
그래프(Graph)
그래프는 다음과 같이 노드(Node, Vertex)와 엣지(Edge, Link)로 이루어진 자료구조입니다. 보통 두 노드가 연결되어 있으면 인접하다(Adjacent)라고 설명할 수 있습니다. 파이썬에서는 그래프를 표현할 때, 행렬 또는 리스트로 표현이 가능합니다.
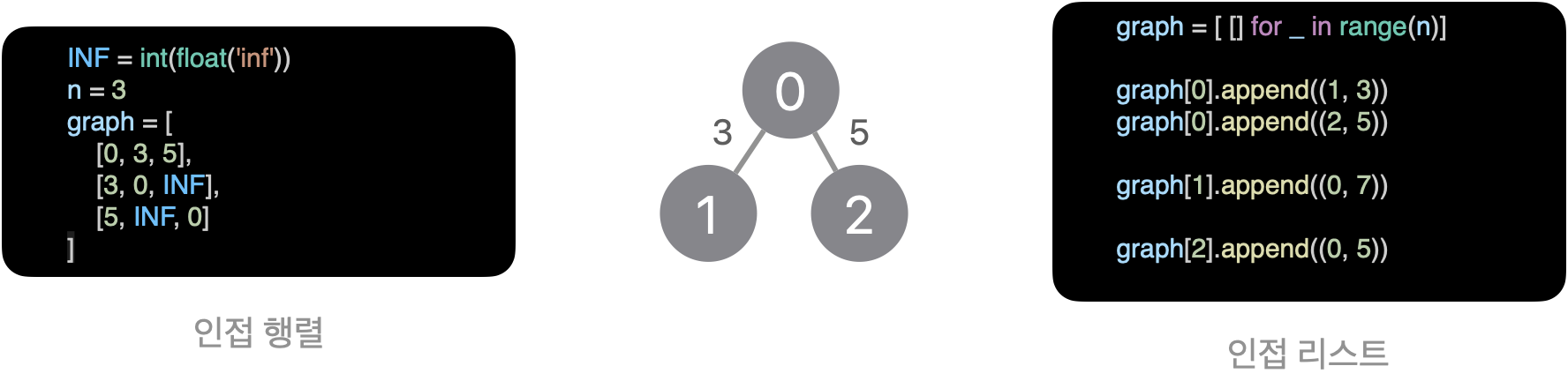
각 자료구조의 장단점으로는 인접행렬은 INF 처럼 연결되어 있지 않은 정보도 넣어야 하므로 메모리가 많다는 단점이 있지만 또 그만큼 찾는 속도는 빠르다는 장점이 있습니다.
- 인접 행렬 :
- 인접 리스트 :
💡 순회 알고리즘의 특징
순회하는 문제가 나오는 경우, 방문 여부를 확인하는 배열을 만들어주면 풀기 쉬워집니다.visited
스택(Stack), 큐(Queue)
- 스택(Stack) : 가장 나중에 들어온 것이 먼저 나가는 LIFO 구조를 가지고 있습니다. 보통 함수의 콜스택이나 문자열 역순 출력에 사용됩니다.
- 큐(Queue) : 가장 먼저 들어온 것이 먼저 나가는 FIFO 구조를 가지고 있습니다.
재귀함수(Recursion)
하나의 함수를 실행하는 동안 다른 함수를 호출하거나 자신의 함수를 호출하여 콜스택에 쌓아가는 구조입니다.
재귀함수에는 반드시 명시 해야할 조건이 있습니다.
- 종료 조건 : 언제 끝날지 모르는 함수를 멈춰서 다시 돌아오게 만들게 하는 것이죠.
- 점화식 : 재귀함수는 점화식을 이용해 문제를 풉니다.
def fibonacci(n):
if n == 0:
return 1
elif n == 1:
return 1
else: # n >= 2 인 경우
return fibonacci(n-1) + fibonacci(n-2)💡 스택보다 좀 더 간결한 코드
추후에 DFS 파트를 보면 알겠지만 재귀함수를 사용하면 코드가 더 간결해집니다. 이유는 수학 점화식을 그대로 코드로 옮겼기 때문입니다.
시뮬레이션 문제
DFS/BFS 같은 알고리즘은 보통 시뮬레이션 문제로 출제되는 경우가 있습니다. 예를들어, 다음과 같은 문제가 있습니다.
여행가 A는 N X N 크기의 정사각형 공간 위에 서있다. 이 공간은 1 X 1 크기의 정사각형으로 나누어져 있는데 가장 왼쪽 위 좌표는 (1,1)이며, 가장 오른쪽 아래 좌표는 (N,N)이다. 여행가는 상하좌우로 움직일 수 있으며 시작 좌표는 (1,1)이다

- 첫째 줄에는 공간의 크기
N이 주어진다. 둘째 줄에는 이동 계획이 주어진다. - 줄을 기준으로 L R U D로 움직일 수 있다.
- 만약, 공간을 벗어나는 움직임은 무시된다.
그렇다면 최종적으로 도착하는 위치를 출력하라.
# 입력
5
R R R U D D
# 출력
3 4이러한 시뮬레이션을 통해 경로를 탐색하는 문제는 dx와 dy 처럼 방향을 지정한 다음, 경로에서 벗아날 듯한 장애물, 벽은 무시하는 코드를 짜야합니다.
n = int(input())
x, y = 1, 1
directions = list(map(str, input().split()))
dx = [0, 0, -1, 1]
dy = [-1, 1, 0, 0]
move_type= ['L','R','U','D']
for dir in directions:
for i in range(len(move_type)):
# 이동 후 좌표 구하기
if dir == move_type[i]:
nx = x + dx[i]
ny = y + dy[i]
# 공간을 벗어나는 경우 무시
if nx < 1 or ny < 1 or nx > n or ny > n:
continue
x, y = nx, ny
print(x, y)📚 DFS
깊이 우선 탐색은 깊은 부분(자식 노드)까지 먼저 탐색한 다음 방문할 노드가 없으면 다시 돌아와 경로를 탐색하는 알고리즘입니다.
💡 그래프(Graph)랑 트리(Tree)의 다른 점
그래프랑 트리의 큰 차이점으로는 사이클의 여부에 따라 다릅니다. 트리는 사이클이 되지 않고 그래프는 사이클이 됩니다. 그러므로 DFS나 BFS 같은 경우도 다시 돌아와 경로를 탐색할 수 있는 것이죠.
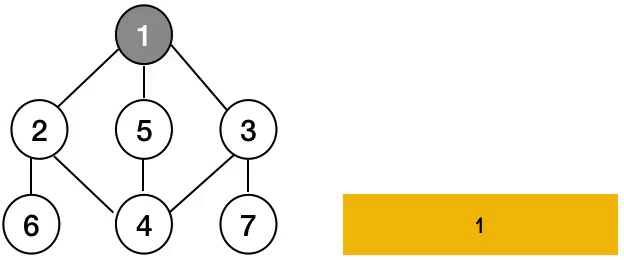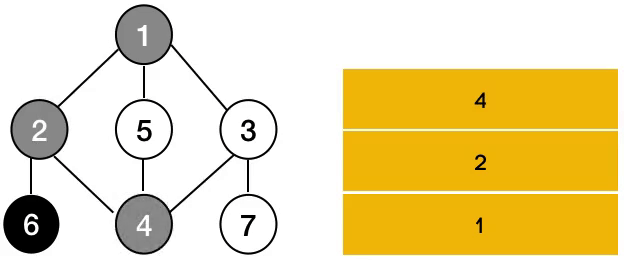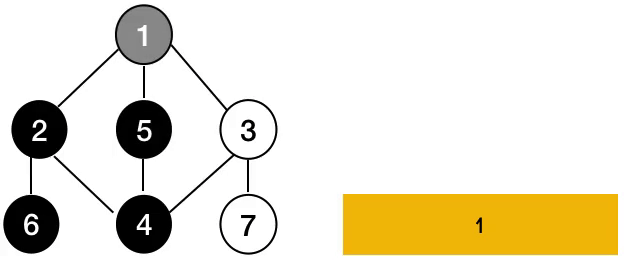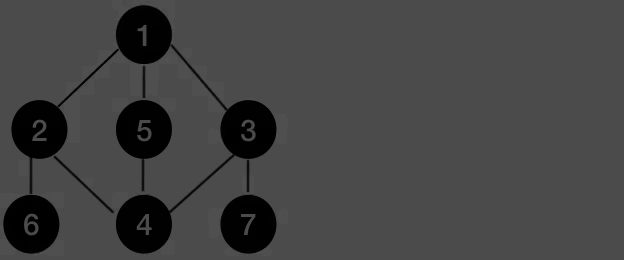
동작 방식
트리의 전위순회와 유사한 방식으로 동작합니다. DFS가 동작하기 위해서 스택 자료구조나 재귀함수를 사용합니다. 이 두 방법은 동일한 답을 내놓긴 하지만 다른 방식으로 순회를 합니다. 이유는 스택은 재귀함수와 다르게 배열의 뒤에서 pop을 하기 때문이죠.
-
시작노드
Push: 시작 정점을 스택에 넣습니다. -
스택의 최상단의 정점을
pop하고 방문 표시합니다. -
pop된 정점에서 방문하지 않았던 인접 정점들을 다시 스택에push하여 넣습니다.
- 만약 인접노드가 여러개라면 번호(인덱스)가 낮은 순부터 처리합니다.
- 방문하지 않은 인접 노드가 없으면 스택에서 최상단의 노드를 꺼냅니다.(다시 돌아오기)
- 스택에 데이터가 없을 때 까지 2번과 3번 과정을 반복합니다.
💡 DFS 같은 경우, 주로 위상 정렬이나 미로, 연결 문제등에서 많이 나옵니다.
코드
- 스택을 사용했을 경우
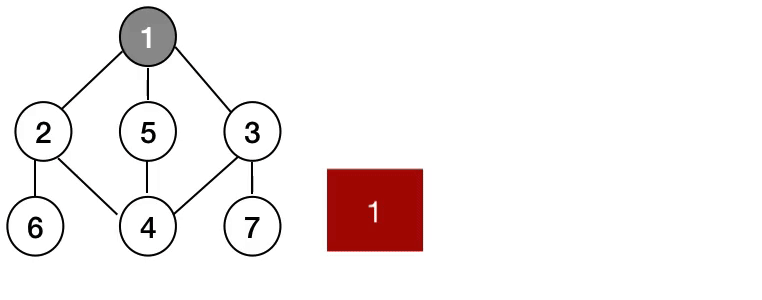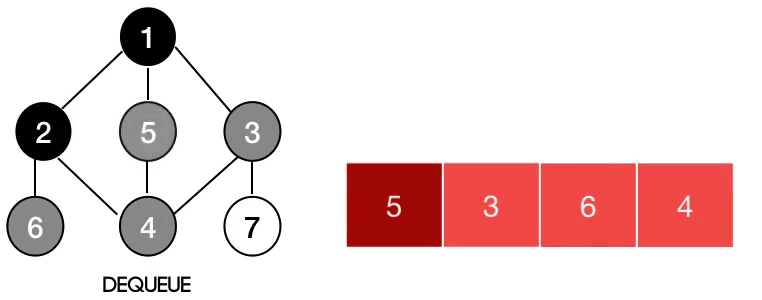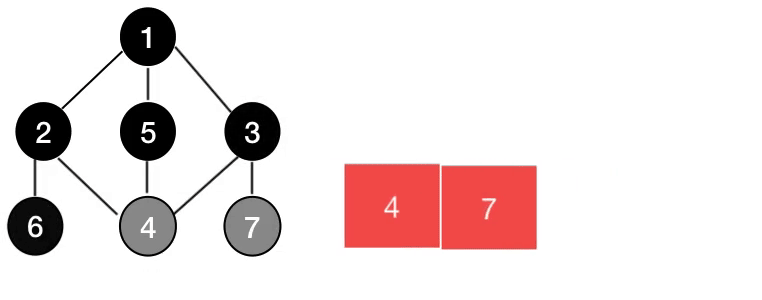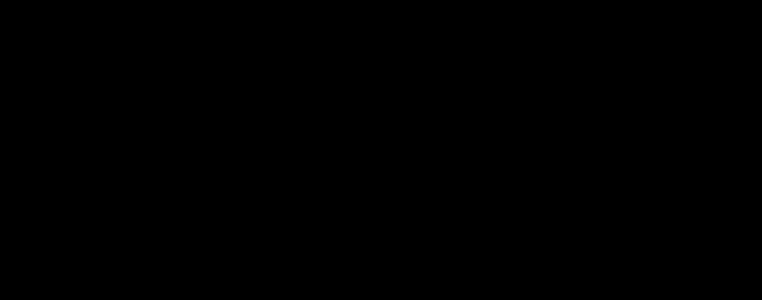
graph = [[], [2, 5, 3], [1, 6], [1, 4, 7], [2, 5, 3], [1, 4], [2], [3]]
visited = [False] * len(graph)
stack = [1] # 시작 노드를 스택에 넣습니다.
while stack:
node = stack.pop() # 가장 top 노드를 뽑아 방문 여부를 확인
if visited[node] == False:
visited[node] = True
print(visited)
stack.extend(graph[node]) # top 노드의 인접 노드를 넣기- 재귀 함수를 사용했을 경우
def dfs(graph, v, visited):
# 현재 노드 방문 처리
visited[v] = True
print(v, end=' ')
# 인접 노드 재귀적으로 방문
for i in graph[v]:
if not visited[i]:
dfs(graph, i, visited)
print(dfs(graph, 1, visited))📚 BFS
너비 우선 탐색은 가까운 부분(형제 노드)부터 탐색한 다음 멀리있는 노드까지 방문하는 알고리즘입니다.
동작 방식
BFS는 그래프의 Level 순서로 동작합니다. BFS가 동작하기 위해서 큐 자료구조를 사용합니다. 큐 자료구조는 가장 앞선에 있는 데이터를 먼저 처리하기 때문에 근처에 있는 인접 노드를 돈 다음 그 인접 노드의 인접노드를 돌게 되는 것이죠. 파이썬에서는 큐를 사용하는데 deque라는 라이브러리를 사용하면 유용하게 문제를 풀 수 있습니다.
💡
deque라이브러리from collections import deque data = deque([2,3,4]) data.append(5) #push data.popleft() #pop
deque라이브러리는 넣고 빼는게 효율적이고 큐 라이브러리보다 간단한 모듈입니다.
-
시작노드
Push: 시작 정점을 큐에 넣습니다. -
큐의 가장 앞단에 있는 정점을
popleft하고 방문 표시합니다. -
popleft된 정점에서 방문하지 않았던 인접 정점들을 다시 큐에push하여 넣습니다.
- 방문하지 않은 인접 노드가 없으면 큐에서 가장 첫번째 정점을 뺍니다.
- 큐에 데이터가 없을 때 까지 2번과 3번 과정을 반복합니다.
💡 BFS 같은 경우, 네트워크 라우팅이나 주변 위치, 가장 먼 노드 찾기등에서 많이 나옵니다.
코드
from collections import deque
graph = [[], [2, 5, 3], [1, 6], [1, 4, 7], [2, 5, 3], [1, 4], [2], [3]]
visited = [False] * len(graph)
queue = deque([1]) # 시작 노드를 큐에 넣습니다.
while queue:
node = queue.popleft() # 가장 앞단에 노드를 뽑아 방문 여부를 확인
if not visited[node]:
visited[node] = True
print(visited)
queue.extend(graph[node]) # 노드의 인접 노드를 넣기정리
DFS와 BFS의 차이를 두자면, 뒤에서 꺼내기와 앞에서 꺼내기의 차이...? 인듯 하다.
| DFS | BFS | |
|---|---|---|
| 원리 | 스택(재귀) | 큐 |
| 공통점 | 모든 노드 탐색 | 모든 노드 탐색 |
| 장점 | 깊이가 깊을 수록 빠름 | 찾는 노드가 인접할 수록 유리 |
| 단점 | 깊이가 너무 길면 메모리가 많이 소비될 것 같음 | 인접 노드가 많은 경우 메모리가 많이 소비될 것 같음 |
| 응용 | 미로나 경로 찾기 | 주변 위치 찾기, 먼 노드 찾기 |
🏄♂️ 문제
여행 경로
문제
주어진 항공권을 모두 이용해 여행경로를 짜려고 합니다. 항상 ICN 공항에서 출발합니다.
항공권 정보가 담긴 2차원 배열 tickets가 매개변수로 주어질 때, 방문하는 공항 경로를 배열에 담아 retrun 하도록 함수를 작성하세요.
- 모든 공항은 알파벳 대문자 3글자로 공항의 수는 3개 이상 10,000개 이하입니다.
tickets의 각 행[a, b]는 a 공항 → b 공항으로 가는 항공권이 있다는 의미입니다.- 만일 가능한 경로가 2개 이상일 경우 알파벳 순서가 앞서는 경로를 return 합니다.
- 모든 도시를 방문할 수 없는 경우는 주어지지 않습니다.
| tickets | return |
|---|---|
| [["ICN", "JFK"], ["HND", "IAD"], ["JFK", "HND"]] | ["ICN", "JFK", "HND", "IAD"] |
| [["ICN", "SFO"], ["ICN", "ATL"], ["SFO", "ATL"], ["ATL", "ICN"], ["ATL","SFO"]] | ["ICN", "ATL", "ICN", "SFO", "ATL", "SFO"] |
풀이
여러번 1,2번만 자꾸 틀리게 되서 결국엔 1번 2번 예시를 보게되었습니다.
1번 2번 입출력 예시는 다음과 같습니다.
| tickets | return |
|-::-|-::-|
|[["ICN", "AAA"], ["ICN", "BBB"], ["BBB", "ICN"]]| ["ICN", "BBB", "ICN", "AAA"]|
제가 했던 코드 대로 진행한다면 AAA가 먼저 뽑혀 갈 곳이 없기 때문에 돌아올 수 없게 됩니다.
그래서 해당 티켓은 반환한 뒤 다른 경로(‘BBB’)를 찾아야합니다.
저는 스택에서 출발지점을 뽑아 다른 곳으로 갈 수 있다면 도착지를 스택에 다시 넣고 갈 곳이 없다면 다음 티켓을 답에 추가하는 방식으로 진행했습니다.
{ 시작점 : [도착점], ... } 형식으로 인접 리스트를 생성합니다.
def solution(tickets):
# 특정 티켓의 인접 리스트를 구하는 함수
def init_graph():
routes = defaultdict(list)
for key, value in tickets:
routes[key].append(value)
return routes
routes = init_graph()도착점의 리스트를 알파벳 순서대로 정렬합니다.
# 갈 수 있는 공항을 역순으로 정렬
for r in routes.keys():
routes[r].sort(reverse=True)
# {'ICN': ['SFO', 'ATL'], 'SFO': ['ATL'], 'ATL': ['SFO', 'ICN']}DFS 알고리즘을 사용해 스택이 빌 때까지 모든 점들을 순회합니다.
- 만약 가져온 데아터(top)가 그래프가 없가나 티켓을 모두 사용한 경우에는
answer에 저장하고 - 아니라면 데이터(top)을 시작점으로 하는 도착점 데이터 중 가져와 stack에 저장합니다.
# 스택을 사용한 DFS
stack = ["ICN"]
while stack:
top = stack[-1]
# 특정 공항에서 출발하는 표가 없다면 또는 있지만 티켓을 다 써버린 경우
if top not in routes or not route[top]:
answer.append(stack.pop())
else:
stack.append(routes[top].pop())
return answer[::-1]아래는 스택 변화입니다.
['ICN']
['ICN', 'ATL']
['ICN', 'ATL', 'ICN']
['ICN', 'ATL', 'ICN', 'SFO']
['ICN', 'ATL', 'ICN', 'SFO', 'ATL']
['ICN', 'ATL', 'ICN', 'SFO', 'ATL', 'SFO']
['ICN', 'ATL', 'ICN', 'SFO', 'ATL']
['ICN', 'ATL', 'ICN', 'SFO']
['ICN', 'ATL', 'ICN']
['ICN', 'ATL']
['ICN']- 재귀를 이용한 방법
from collections import defaultdict
def solution(tickets):
# 특정 티켓의 인접 리스트를 구하는 함수
def init_graph():
routes = defaultdict(list)
for key, value in tickets:
routes[key].append(value)
return routes
# 재귀 호출을 사용한 DFS
def dfs(key, footprint):
if len(footprint) == N + 1:
return footprint
for idx, country in enumerate(routes[key]):
routes[key].pop(idx)
fp = footprint[:] # deepcopy
fp.append(country)
ret = dfs(country, fp)
if ret: return ret # 모든 티켓을 사용해 통과한 경우
routes[key].insert(idx, country) # 통과 못했으면 티켓 반환
routes = init_graph()
for r in routes:
routes[r].sort()
N = len(tickets)
answer = dfs("ICN", ["ICN"])
return answerhttps://wwlee94.github.io/category/algorithm/bfs-dfs/travel-route/
가장 먼 노드
문제
N개의 노드가 있는 그래프가 있습니다. 각 노드는 1부터 N까지 번호가 적혀있습니다. 1번 노드에서 가장 멀리 떨어진 노드의 개수를 구하려고 합니다. 가장 멀리 떨어진 노드는 최단 경로로 이동했을 때, 간선의 개수가 가장 많은 노드들을 의미합니다.
노드의 개수 n, 간선에 대한 정보가 담긴 2차원 배열 vertex가 매개변수로 주어질 때, 1번 노드로부터 가장 멀리 떨어진 노드가 몇 개인지를 return 하도록 solution 함수를 작성해주세요.
- 노드의 개수
n은 2 이상 20,000 이하입니다. - 간선은 양방향이며 총 1개 이상 50,000개 이하의 간선이 있습니다.
vertex배열 각 행 [a, b]는 a번 노드와 b번 노드 사이에 간선이 있다는 의미입니다.
| n | vertex | return |
|---|---|---|
| 6 | [[3, 6], [4, 3], [3, 2], [1, 3], [1, 2], [2, 4], [5, 2]] | 3 |
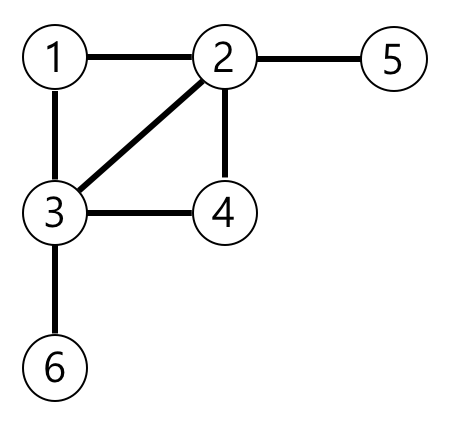
가장 멀리 떨어진 노드는 4,5,6입니다.
풀이
참고
https://yoongrammer.tistory.com/85
이것이 취업을 위한 코딩테스트다. with 파이썬
https://reeborg.ca/reeborg.html?lang=ko&mode=python&menu=undefined&name=%2Fworlds%2Fmenus%2Fselect_collection_en.json&url=%2Fworlds%2Fmenus%2Fselect_collection_en.json
