
🔎배경
프로젝트 중,
Pi Datametrics라는 외부 소스에서 API로 데이터를 받아
내부 DB에 테이블 형태로 저장해야 하는 상황이 발생했다.
즉, ETL 과정 중
- Extract(추출)+Transfrom(전처리) = 🐍 Python으로
- Load(적재) = 💾 SQL Server (MS SQL DB) 로
분리된 두 환경을 사용해야 하는 상황이 된 것이다.
이 때, 크게 사용할 수 있는 방법은 PyODBC 와 SQLAlchemy 두 패키지를 사용하는 것이다.
오늘은 두 가지 방법의 개발 방법을 모두 알아보고,
추후 편한 방법(혹은 상황에 맞는 방법)을 선택할 수 있도록 하자! 💪🏻💪🏻
📝 사전 정보
1. 추출한 데이터의 포맷: Pandas Dataframe
- 테이블명: df_IndexInfoimport pandas as pd /* API 호출 코드 ... */ # Pandas DataFrame 형식으로 저장 df_IndexInfo = pd.DataFrame(json_data['data'])
(이번 포스팅은 SQLAlchemy 사용법에 focus를 맞췄기 때문에 데이터 전처리 부분은 생략)
- df_IndexInfo 테이블 스키마 참고
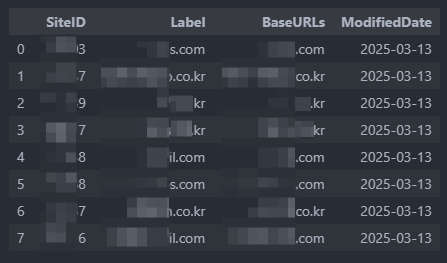
2. DB유형: SQL Server(MS SQL)
MySQL과 쿼리 문법이 조금 다를 수 있음.
3. DB에 테이블은 미리 CREATE 되어 있어야 함
Python에서 데이터를 쐈을 때, 데이터를 받을 테이블은 DB에 미리 준비 필요.
/** Pi Datametrics 사이트 master **/ CREATE TABLE [Scheme명].[DB명].[테이블명] ( SiteID NVARCHAR(10) , Label NVARCHAR(50) , BaseURLs NVARCHAR(50) , ModifiedDate Date );
4. DB 서버 접속정보도 미리 준비 필요
작업 중인 스크립트에 사전 명시 필요.
## MSSQL 서버 정보 server = '연결할 서버 주소' database = '전송 타겟 DB명' username = '접속계정의 사용자이름' password = '접속계정의 비밀번호'
🎯미션
Python 스크립트로 추출한 데이터를
ver1. SQLAlchemy 패키지를 사용하여
ver2. PyODBC 패키지를 사용하여
SQL Server(DB) 의 테이블에 저장한다! 🔥
📌 PyODBC vs SQLAlchemy
| 장점 | 단점 | |
|---|---|---|
| SQL Alchemy | 코드가 간결하고, 데이터 삽입이 간편 | SQLAlchemy와 Pandas를 설치하고 설정 필요 |
| PyODBC | SQL문 그대로 실행 가능 | 코드가 더 복잡하고, 각 행에 대해 개별적으로 쿼리를 실행하므로 성능이 떨어질 수 있음 |
꼭 SQL 쿼리로 해야 할 이유가 없다면, SQL Alchemy가 훨씬 이득인거 아닌가...?
🖥️ 본격 작업
1. SQLAlchemy.ver
1) SQLAlchemy용 DB 연결정보 세팅
- 위의
사전정보-4번단계로 세팅됨. → pass
2) DB 연결 및 테이블에 저장
from sqlalchemy import create_engine
engine = create_engine(f'mssql+pyodbc://{username}:{password}@{server}/{database}?driver=ODBC+Driver+17+for+SQL+Server')
PandasDataframe명.to_sql('받는(DB의)테이블명', engine, if_exists='replace', index=True)if_exists 옵션
중복값 처리 방식이다. 덮어쓰기 / 추가하기 중 택 1 하면 된다.
나는 master성 테이블이라
항상 전체 데이터를 덮어쓰기 하므로 if_exists 옵션을 replace 로 세팅했지만,
만일 기간계 데이터라 history 데이터도 그대로 남기고 신규 데이터를 추가하는 경우
if_exists 옵션을 append 로 설정하면 된다.
index 옵션
인덱스 컬럼 생성 여부 옵션이다.
나는 각 행의 순서 정렬 기준이 필요한 상황이라, True 로 세팅했다.
2. PyODBC.ver
1) PyODBC용 DB 연결정보 세팅
(*위의 사전 정보-4 에서 DB 접속정보 사전 명시 후 진행)
아래 이어질 데이터베이스 연결에 사용할 conn_str 정보를 세팅해주어
계속 full로 칠 필요 없이 conn_str로 재사용 할 수 있게 해준다.
conn_str = (
'DRIVER={ODBC Driver 17 for SQL Server};'
f'SERVER={server};'
f'DATABASE={database};'
f'UID={username};'
f'PWD={password};'
'Encrypt=no;'
)2. DB 연결 및 테이블에 저장
import pyodbc
cursor = None # cursor 변수를 초기화
conn = None # conn 변수를 초기화
try:
# 데이터 삽입
conn = pyodbc.connect(conn_str)
for index, row in df_indexInfo.iterrows():
conn.execute("INSERT INTO [DB명].[Scheme명].[테이블명] (SiteID, Label, BaseURLs, ModifiedDate) values(?,?,?,?)",
row.SiteID, row.Label, row.BaseURLs, row.ModifiedDate)
# 커밋
conn.commit()
cursor = conn.cursor()
print("INSERT 구문이 성공적으로 실행되었습니다.")
except Exception as e:
print("INSERT 구문 실행 중 오류 발생:", e)
finally:
if cursor is not None:
cursor.close() # cursor가 None이 아닐 때만 닫기
if conn is not None:
conn.close() # conn이 None이 아닐 때만 닫기에러 처리를 위해 try-except 구문을 사용했다.
conn.execute 구문 뒤에 INSERT를 위한 SQL 쿼리문을 그대로 사용하면 되고,
values 뒤의 ? 는 INSERT 될 컬럼 개수만큼 넣어주면 된다.
(iterrows를 사용하여 for문을 돌리기 위해 와일드카드를 사용했다고 생각하면 편함)
✨ 결과
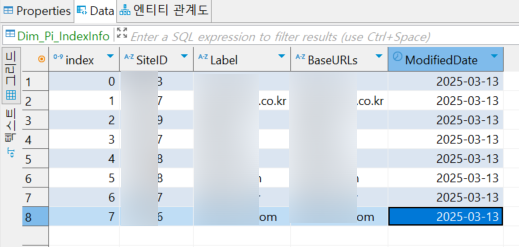
두 방식 모두
위와 같이 INSERT 시킨 데이터가 DB에 잘 들어갔음을 확인할 수 있다!
🫠 개인적 후기
개인적으로, SQLAlchemy 를 사용한 방식이
코드도 훨씬 짧고 간결하여
굳이 꼭 SQL문을 길게 써야하는 상황이 아니면
PyODBC보다는 SQLAlchemy를 애용할 것 같다!
+) 혹시 꼭 PyODBC를 사용해야 하는 경우가 있다면 댓글로 남겨주시길 바랍니다~!
