Intro
experience replay 를 버리고 multiple agent 들을 asynchronously execute 하게 변경
선형연구 Gorila는 agent - parameter server - cenetral model 구조로 이뤄져 각 parallel 한 agent들의 parameter update는 parameter model 에 반영되고 이는 다시 central model의 parameter 변경에 영향을 준다.
Actor-critic Recap
policy parameter 개념이 도입되며 아래와 같은 크기만큼 gradient ascend 시킨다.
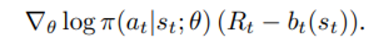
이 때 basefunction b를 V로 잡으면 각 (s,a) pair 에서 advantage 를 계산하기 때문에 Advantageous Actor-critic 이라고 한다. (V는 모든 action 에 대한 expectation 을 의미하는 value 이므로)
Asynchornous RL framework
1) asynchronous actor-learns
→ Gorila 방식에서 쓰던 여러 machine들과 parameter server 대신 하나의 machine에 multi-thread 환경 사용
2) Multiple actors (learners) running in parallel
→ Single agent 가 online update를 하는 것과 비교해서 다른 영역의 env를 탐색하고 있을 확률이 높기 때문에 parallel 하게 이뤄진 탐색결과의 parameter update는 서로 less correlated 되어있을 것이다.
이는 동시에 experience replay 의 대체 가능성을 의미한다.
추가적인 장점 )
1) parallel actor-learner 로 O(n)의 시간을 O(1)로 단축
2) experience replay가 사라졌기 때문에 on-policy 방식을 적용하기 용이함
Asynchronous one-step Q learning
Asynchronous one-step Sarsa
TD target 이 아래와 같이 바뀐다
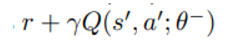
A3C algorithm

