SAMPLE EFFICIENT DEEP REINFORCEMENT LEARNING VIA UNCERTAINTY ESTIMATION
Intro
DRL 알고리즘 자체에 내재된 uncertainty 를 공략하는 것이 learning efficiency를 높이기 위한 한가지 방안으로 떠오르고 있다!
그 중에서도 이 논문은 TD update에서 unreliable 한 supervision 과 policy optimization process의 uncertainty을 지적한다
- TD update 에서 value function 의 추정값은 학습의 label로 사용된다
- actor-critic framework 에서는 policy가 이러한 값을 optimize 하도록 (maximize?) 훈련된다
→ value function 이 noisy 하다는 성질이 learning을 느리게 만들고 불안정성을 일으킨다
기존 논문들 중에는 value prediction 의 불확실성을 exploration/ exploitation trade-off 를 guide 하도록 하는 내용이 많았지만
Unreliable prediction 의 영향을 피하도록 하는 방향은 연구되지 않았다
이전에 제시된 Distributional RL 에서는 value function을 distribution 으로 보고 이를 모두 학습해야 한다고 했지만
이 논문에서는 scalar value function 을 학습하도록 하고 label 의 uncertainty 를 이용한다
(Uncertainty 를 이용하는 선행연구에는 distribution 에서 벗어난 state, action pair를 훈련에서 제거하기 위해 uncertainty로 weighting 하는 방식이 존재한다 )
이번 연구와 비슷한 SUNRISE 라는 방식에서는 TD update 에서 높은 std 를 가진 label의 중요도를 낮추는 weighting 방식을 사용했다
이 논문에서는 IV-RL (inverse - variance reinforcement learning) 을 제안하며 앞선 방식 개념과 비슷하게 trainig 과정에서 불확실성이 높은 target의 중요도를 낮춘다
이를 위해 두 가지 방식으로 해결책을 제시한다
1) variance network 사용 (variance networks (Kendall & Gal, 2017) 가 무엇인가?)
→ 주어진 state, action 쌍에 대해 network는 target이 가진 noise(env 의 stochasticity나 policy update에서 기인한) 를 학습하여 높은 noise를 가진 sample 들을 down-weight 시킨다
이 방법은 HFRL 에서 제시한 env들의 작은 변화로 인한 stochasticity를 잡을 수 있는 대안이 될 것 같음!
2) variance ensemble 사용 (variance ensembles (Lakshminarayanan et al., 2017) 가 무엇인가?)
→ 앞서 variance network 를 통해 평가한 variance들을 받아 gaussian mixture 를 통과시켜 predictive uncertainty를 감지한다. 그 후 heteroscedastic regression 에 효과를 보인다고 알려진 Batch Inverse-variance를 적용한다
일단 읽기 전에는 BIV엔 std 값들이 전해져야 하는데 variance network 방식을 통해 구한 std 값들을 여기로 넘기는 것으로 보인다
Background
1) BIV - Batch Inverse Variance weighting
supervised learning에서 label 을 매기는 과정에서 추가되었을 수 있는 heteroscedastic 한 noise를 잡는데 도움이 되는 방식이다.
Dataset 의 setting 은 다음과 같다
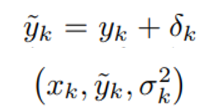
label 과 prediction 간 loss function에 L2 가 사용될 때 아래와 같은 loss function을 통해 NN parameter를 결정한다
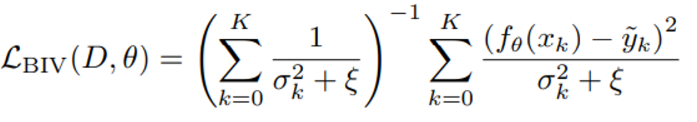
hyperparameter 에타는 optimization 과정의 안정성을 조절하는데 기여하며 그 방식은 에타가 큰 값을 가지면 작은 variance를 가진 data 가 loss function 에 대부분을 기여하게 되는 것을 막는 형태로 이해할 수 있다.
에타값을 정하는 방식은 DRL과 같이 profile of variance 가 계속 변하는 경우는 상수로 미리 정해놓으면 안되고 에타가 가져야 하는 하한을 정해 최소 일정량의 data는 loss function 을 통한 학습에 사용되도록 설정해야 한다. (에타에 대한 하한은 일반적으로 전체 batch size에 대해 현재 fraction 을 구하면 보장된다고 한다?)
2.1) Sampled Ensembles
동시에 여러 네트워크들이 prediction 값을 산출하며 이는 prediction distribution으로 여겨진다. 이러한 모델들이 같은 input에 대해 비슷한 결과를 내기 위해서는 충분한 time step 이 필요하며 이에 따라 network 출력값에서 얻은 sample variance 는 epistemic 불안정성(trained model에 관련해 training data, model capacity 등에 영향을 받는 불안정성) 으로 이해할 수 있다.
여기에 확률 p의 Bernoulli mask 를 씌워 각각이 다른 training 을 진행하고 있음을 확신시킬 수 있다.
RPF - Randomized Prior Functions 방식은 각 network를 fixed, untrained network 와 강제로 매치시켜 variance에 prior 를 강제하는 방법인데 잘 탐색되지 않은 input space에서는 high variance를 이미 탐색되고 converge 해야하는 영역에서는 lower variance를 내게 만들어 준다.
2.2) Variance Networks
network 의 출력은 mean과 variance이며 아래와 같은 loss function을 minimize 시키는 방향으로 학습된다.
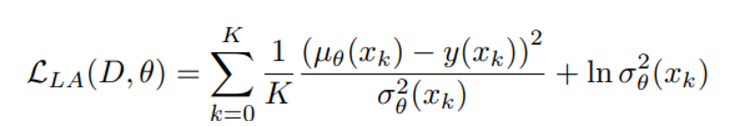
이러한 구조는 high variance 를 가진 data를 down-weight 시키며 (분모가 커지면 자연스레 전체값 감소)
2.3) Variance Ensembles
variance network 로 구성되어 잇는 ensemble ; 최종 prediction은 ensemble들을 gaussian mixture 해서 얻어짐
Sampled ensemble과 비슷하게 underestimated early epistemic variance estimation 에 시달린다
3) Uncentainty and exploration in DRL
exploration method로 BootstrapDQN을 사용하며 여러 ensemble에서 하나의 network를 골라 each episode의 시작 action 을 고르도록 실행된다.
본문
