Intro
기존에 제시된 RL 방식은 Multi-agent에 적용하기에는 적합하지 않다.
→ 각 agent들의 끊임없는 변화는 각각의 시점에서 볼 때 환경의 stability를 낮추기 때문
General - purpose MARL 제안
1) 실행과정에서는 local information 만 활용
2) 환경에 대한 differentiable 모델을 가정하지 않음
3) cooperative + competitive 환경 모두에 대한 적용
기존 Q-learning은 training 과 test 타임에 다른 정보를 줄 수 있는 구조가 아님
→ 이에 따라 actor-critic PG 방식에 critic이 다른 agent들의 policy 정보를 활용해 (training time에만) 학습할 수 있도록 함
→ 위의 방식은 CTDE(centralized training Decentralized execution)을 가능하게 함
→ 모든 과정에서 actor 는 계속 자신의 local observation만 알 수 있음
DPG 복습
Objective 를 최대화 시키기 위한 gradient step
Stochastic policy에서 objective gradient step은 아래와 같다.
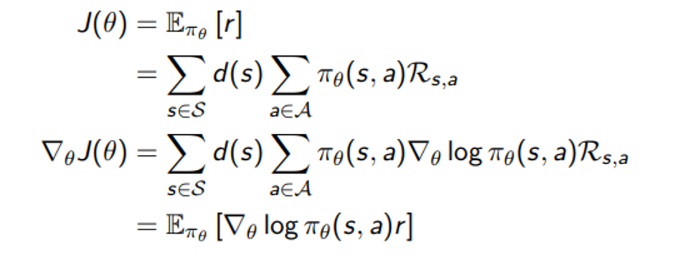
Deterministic 한 식에서는 두번째 sigma 부분이 로 바뀔 것이므로 (sigma가 없어지고) 아래와 같이 log term 이 없는 expectation 을 전개하게 될 것이다.
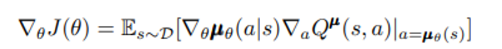
MADDGPG 구조
이제 Q function은 다른 agent들의 action 과 모든 agent들의 observation 총합을 받아 objective function (actor의 parameter가 속한)을 최대화 시킨다.
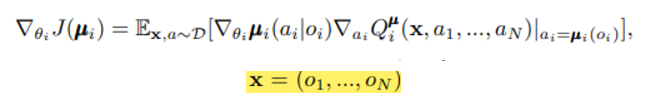
state 대신 들어가는 x는 위와 같으며 각 agent i에 대해 학습하고 있음을 알 수 있다.
이제 replay buffer에는 모든 agent 을 종합한 정보가 아래와 같이 저장된다.
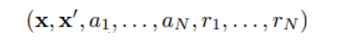
loss Function 도 원래 DDPG와 비슷한 모양, 단지 다른 agent들의 action을 참고한다는 점에 차이가 있음
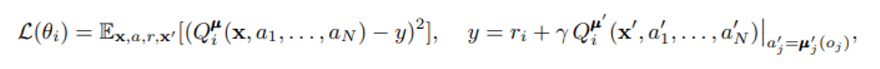
- 여기서 주의할점은 target y에서는 buffer에 저장된 것보다 하나 뒤의 step을 더 진행시켜 최종 target을 계산해야 하는데 이 때 각 agent의 a’들은 각각의 policy와 observation을 알야아 가능하다. 모든 agent의 policy 와 observation 을 알고있다는 것은 과한 가정이 아니지만 만약 불가능할 경우을 section 4.2 에서 설명하고 있다.
이러한 구조를 가능하게 한 것은 policy 의 변화에도 environment 기준에서는 state에 대응되는 action 만 동일하면 항상 같은 다음 state로 넘어갈 것이라는 성질 때문
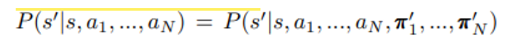
section 4.2 - 각 agent의 policy를 알고 있다는 가정 없애기
다른 agent들의 policy를 u_hat으로 function approximation 해 추정하는데 이 때 다음과 같은 loss를 최소화 시키는 방향으로 학습한다.
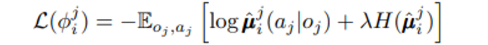
target 을 정할 때 approximated policy를 사용한다.
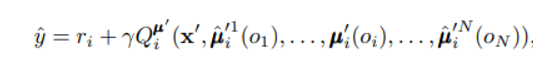
하지만 이런 제약은 후에 등장하는 MARL 논문에서는 모두 허용되는 범위이므로 무게두어 고려하지 않는다.
section 4.3 - 다른 agent policy를 의식한 과적합 문제
Competitive task의 경우 상대 agent의 정책에 맞써 이기기 위해 과적합되는 위험성이 있으므로 K개의 다른 sub policy 중 하나를 골라 학습하는 방향으로 이뤄진다.
각각의 sub policy는 policy estimator parameter와 Replay buffer를 갖는다.
1) Uniform sampling 을 통한 정수 k 설정
2) 각각의 sub policy parameter는 아래와 같은 objective를 최대화하게 학습
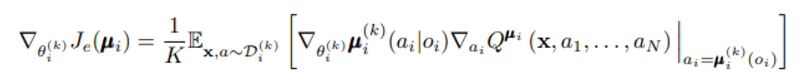
전체 알고리즘

원래 방식과 구조는 비슷하다.
action을 결정해 replay buffer에 1개 저장한 후 N개의 mini batch를 꺼내 actor와 critic을 훈련시키는 것인데 여기에는 N개의 mini-batch를 꺼내는 과정에 for문을 추가해 i개의 agent 각각에 대해 actor, critic을 모두 훈련시킬 수 있도록 했다.
