Intro
language를 전혀 포함하지 않는 task에서도 Language 모델을 사용하여 어떻게 올바른 policy를 배울 수 있으며 string 만 처리하게 학습된 모델에서 어떻게 이러한 방식이 가능할까?
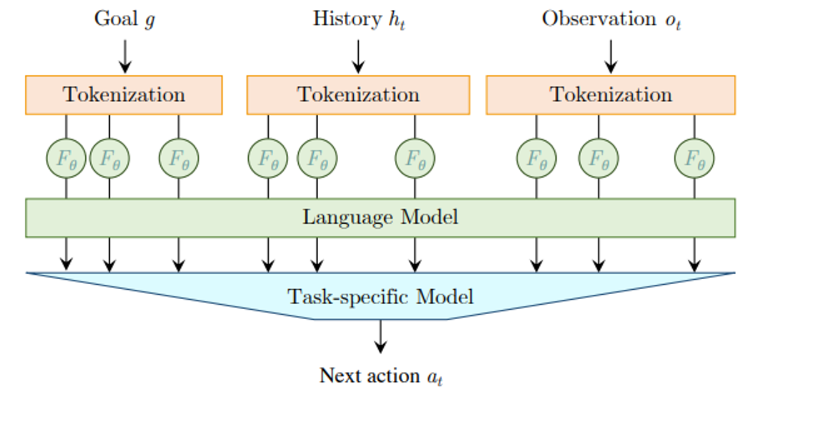
방법 : policy 로 들어가는 input을 embedding sequence로 encoding 한다 (obs, goal ,history)
이러한 embedding들은 pretrained LM 을 통과 후 action으로 변환된다
(LM 은 마지막 fine-tuned 됨)
env state, goal 의 형식 : string, image patches, scene graph 다 가능
발견
1) novel task에 대해 성능을 높이는 방법으로 pre-trained LM을 이용한 imitation learning이 있다 (but how?)
2) combinatorial task에서?
3) expert data가 없을 경우에 대처법 : Active Data Gathering 과정을 거친다
ADG 구성요소
1) current policy action + random action의 혼합으로 exploration 진행 후 trajectory를 모은다
하지만 대부분의 trajectory는 goal을 달성하지 못하고 중간에 실패할 것이다
이러한 trajectory 조차도 sub goal을 달성하는 sub trajectory들이 존재하며 hindsight relabeling stage에서 이들을 relabel 하여 학습에 활용한다 (어떤 sub goal 이 달성되었는지를 relabel 한다)
LM based policy initialization 이 효과적인 이유
1) language based input encoding scheme
2) fixed seized obs 와 비교한 sequential input
3) LM pretrainng 으로 인한 useful inductive bias
정리 : LM-pretraining 의 이점을 누리기 위해 가장 중요한 것은 sequential input encoding + weight pre-training
Related work
이 논문의 목표는 input, output 이 string 과 연관되어있지 않더라도 pre-trained LM을 사용해 decision making policy를 학습하자는 것
policy setting

goal, history info, partial obs에 결정되는 parametric model
전체적인 모델 구조