Webshop : Towards Scalable Real-World Web Interaction with Grounded Language Agents
Intro
기존 web 환경의 한계
1) transition (state의미하는 것 같음) depth 가 작고 scale up 하기가 어렵다
2) automated reward function 이 부족하다
Webshop : language understanding + decision making
환경 : e-commerce website에서 online 쇼핑 환경을 가정
goal : human-provided text instruction 을 이해하고 세부사항을 만족하는 아이템을 사는 것
action : web 에 query를 보내 검색결과 중 explore 할 item을 선정하고 그들의 description, detail을 읽은 후 좋은 option을 선택한다
action space : searching을 위한 text queries + choosing text buttons
좋은 item을 고르기 위한 tip : agent는 다양한 product를 탐색해야 하며 multiple search를 진행해야 한다
OPENAI Gym 에서 사용가능하며 (HTML, simple) 모드 2가지가 있다
reward : attributes, type, options, price 를 종합적으로 고려하여 내부적으로 매겨진다
논문에서 제시된 방법 : RL + Imitation Learning + pretrained language models
세부정보 : (State obs 와 action 은 ) Resnet(visual) , Transformer(text) 가 사용되며 each action은 attention layer를 통해 score 매겨진다
(62.4/100 점, 28.7%) 기록
heuristic : (45.6/100점, 9.6%) 기록
human expert : (82.1/100점, 59.6%) 기록
- 참고 : human worker 중에는 patience 와 consistency 가 부족한 사람들도 있었지만 이럼에도 불구하고 성능에 많은 차이가 존재한다
The Webshop Environment
goal : 자연어 instruction으로부터 알맞은 product를 사야한다
POMDP 설정이며 transition은 deterministic 하다
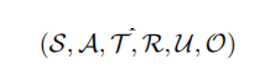
순서대로 state, action, transition function, reward, instruction space, state obs space
- state : web page 상태를 의미 (4 types)
→ search :
→ resut : list of products return by search engine
→ item : describes the product
→ item-detail : further information about product
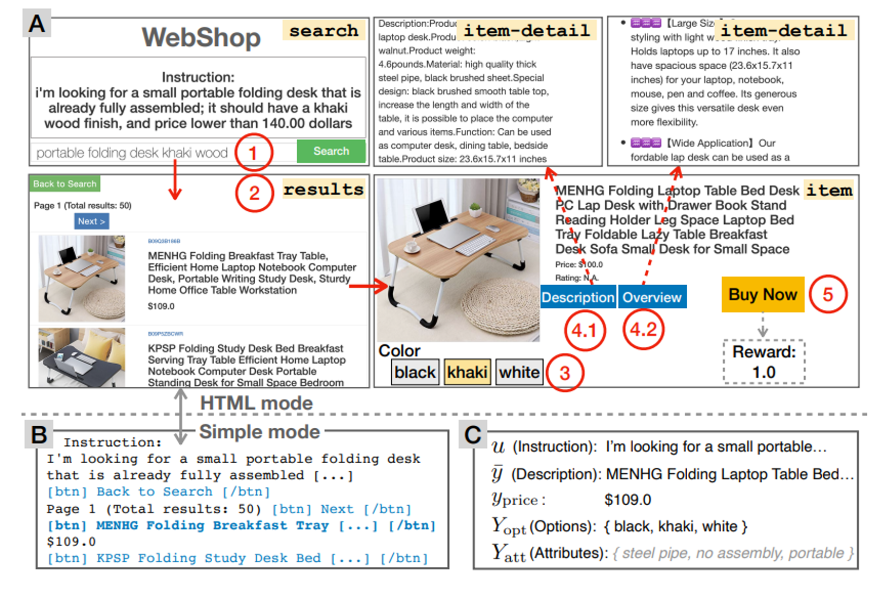
y_bar : product title, description, overview 를 포함한 aggregation
y_price : price
y_opt : set of buying options
I : set of images (correspondes to specific option)
Y_att : set of attributes for automatic reward calculation (각 product에 대응)
- action
→ searching을 위한 text query
→ 버튼을 누르기 위한 명령어
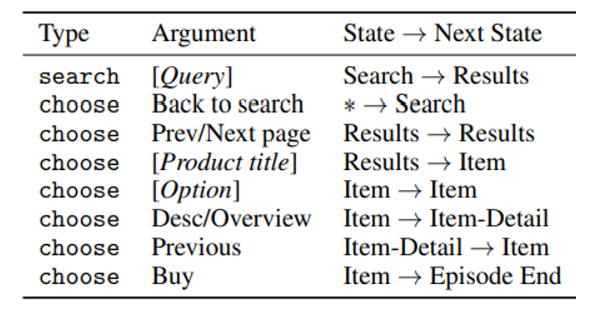
궁금증 : rewards는 buy action을 취했을 때만 얻을 수 있는가..?
특징)
- 두 종류의 action은 동시에 이뤄질 수 없다
- search action은 search page에서만 취해질 수 있다 (다른 곳에서는 click만)
Transition은 deterministic 하다
- observation
FLASK (웹 개발을 위한 가벼운 python framework) + openai gym
HTML , simple 모드 존재
모든 model은 simple mode에서 train, evaluate 된다
human performance score는 HTML 모드에서 실행 (human이 직접 하는 것이므로?)
참고) 환경은 HTML mode에서 raw pixel을 통해서 훈련할 수 있도록 제공할 수 있지만 low-level, non-semantic 한 action space를 제공하므로 simple을 권장한다는 뉘앙스
- Instruction and reward
instruction에 포함된 정보
→ U_att : set of attributes (non-empty)
→ U_opt : set of options
→ u_price : price
이해하기 쉬운 예시
‘ Can you find me a pair of black-and-blue sneaker that is good in rain weather? I want it to have puffy soles, and prices less than 90 dollars’
U_att : {’waterproof’, ‘soft sole’}
U_opt : {color : ‘black and blue’}
<각 에피소드에서 agent는 reward를 마지막 timestep T에서 받는다>
→ reward를 buy action 이후에만 받을 수 있나보네…
아래의 reward function을 보기 전에 y는 마지막 state에서 agent가 고른 product를 의미하고 u는 instruction 이 갖고 있는 정보를 의미한다
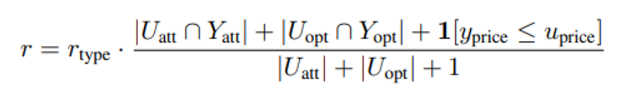
r_type : TextMatch(y, y*) 이며 attribute, option이 비슷하지만 type이 다를 경우 낮은 값을 return 한다
reward는 (0,1) 값을 갖는다
Evaluation Metric
1) task score : 100 x avg. reward
avg.reward = episode들 전반적으로 얻은 reward 값 평균
2) SR (success rate) : 전체에서 r = 1인 비율
참고) 어떤 특정한 item을 생각하고 generate 한 instruction 을 attribute, option이 같은 다른 상품이 만족할 수 있다
Environment Implementation
- Data (text) 세부정보
→ 평균 product text 개수 : 262.9
단어 사이즈 : 224041
unique option 개수 : 842849
- search engine 정보
→ deterministic 하다는 점 기억!
- attribute
→ 각 product는 숨은 attribute로 annotate 되어있으며 용도는 latent characteristic 표시와 reward 계산이다
- Human demonstration
→ expert 점수를 얻기 위해 13명 중 top 7명의 높은 점수를 택했으며 imitation learning 의 자료로도 사용됨
Imitation learning을 사용하지 않으려면 cold-start 논문도 참고!?
Research Challenges
1) 좋은 search query 만들기 , reformulation?
2) website를 탐색하는 strategic exploration
3) robust language understanding for textual state and action spaces
4) backtracking 과 comparing 을 위한 long-term memory
다시보기
Methods
- Rule Baseline
→ instruction text를 그대로 검색한 후 첫번째로 나타나는 item을 바로 사버린다
- Imitation Learning
→ two language model 이 각각 사람의 설명으로부터 search, choose 진행
1) human search 모방하기
searching을 seq-to-seq text 생성 문제로 frame 한다
agent는 instruction u가 주어졌을 때 과거 검색이나 방문 기록을 참고하지 않고 순수하게 search action(a)을 만들어낸다
instruction-search 쌍을 이용해서 데이터셋을 생성하고 BART 모델을 fine-tune 한다
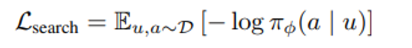
(위와 같은 loss를 최소화)
2) human choice 모방하기
observation 이 주어졌을 때, available 한 button 집합(A(o)) 중에서 사람이 클릭했던 button a* 에 대한 likelihood 가 최대가 되도록 훈련시킨다 .
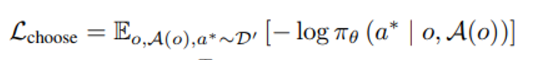
(위와 같은 loss를 최소화)
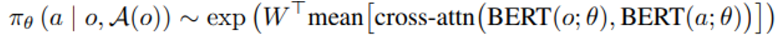
여기서 observation o는 pre-trained BERT에 통과되어 contextualized token embedding에 encode하며 action 도 비슷하게 처리된다.
이후 single vector로 mean pooled 되며 matrix W 와 곱해진다.
3) Image handling
pre-trained ResNet으로 512 feature vector를 생성하고 다시 학습된 linear layer를 통과시켜 768 dimension vector를 얻은 후 BERT(o) 에 concat 되어 observation representation 한다.
여기서 clip model 적용 여부?
4) Full Pipelline
BART model을 통한 search query 생성
BERT model을 통한 action 생성 (divserity 개선 여부?)
- Reinforcement Learning
Online RL을 통해 imitation learning을 fine tune 한다.
선행연구는 direct fine tuning 이 text drifting을 야기하기 때문에 BART 모델을 얼린 후 top -10 search generation 을 choice IL 의 action space로 제한시킨다
1) 이후 아래와 같은 policy gradient loss 를 최소화
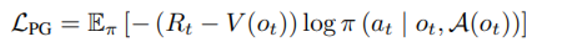
2) 아래와 같은 정해지는 value 에 대한 L2 loss
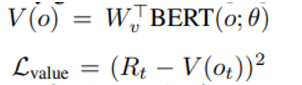
이 때 BERT 의 parameter가 policy 와 tied 되기 때문에 V를 기준으로 한 L2 loss가 policy parameter loss에 추가될 수 있을 것이다
3) 너무 빠른 convergence를 방지하기 위해 (suboptimal result에) 아래와 같은 entropy loss term을 추가한다
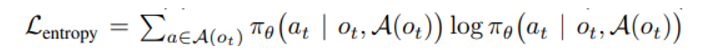
종합적인 loss는 1,2,3의 합으로 구성된다.
Experiments
IL model을 RL로 추가 training 하는 것은 average reward를 증가시키지만 success rate을 감소시킨다!
→ 아마 reward function 증대를 위한 방향으로 훈련되기 때문이라고 여겨짐
→ reward function 이 success rate를 감소시키면 잘못 설계된 것 아닌가..?
5.3에 설명 있다고 함
long term 이익 증대와 horizontal RL로 exploration 증대 에 대한 논문 참고해보자
- ablations
1) IL ablations
language pre-training 의 중요성 강조 (choose action 관점에서)
search query generator가 simple rule로 바뀌면 성능 감소
→ exploration 을 통한 search space를 증가시키는 것도 중요하지만 chose option 을 정확히 배우는 부분이 더 중요하다
오히려 past information을 추가시켰더니 성능이 살짝 감소하는 결과를 초래했다
2) RL ablations
RL agent를 pre-trained된 BERT 를 통해 직접 훈련시킬 땐 rule baseline 보다도 성능이 더 안좋게 나온다.
→ IL warm start의 중요성 강조!
단순 RNN 보다 transformer를 사용했을 경우 더 높은 성능을 보인다
→ better language 와 task prior가 준비되면 높은 성능을 낼 수 있을 것이다
analysis
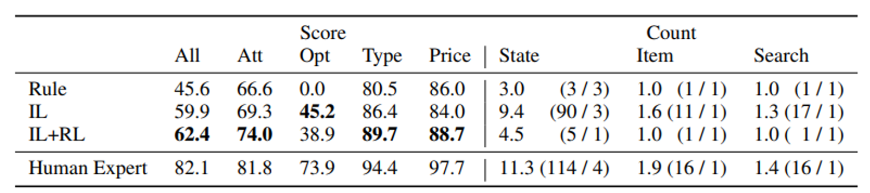
att : (물건 attribute과 instruction 의 교집합)/ (instruction 전체 attribute)
opt : (물건 option과 instruction 의 교집합)/ (instruction 전체 option)
type : r_type
price : y_price ≤ u_price
- 가장 많은 gap 차이가 발생한 부분은 option 분야이고 agent가 알맞은 option을 고르지 못하고 있다고 판단할 수 있다.
- Human은 긴 trajectory를 갖고 agent보다 더 많은 item을 관찰한다
→ 이는 search generation 이 발전할 필요를 의미한다 query reformulation[37, 1] 참고!
→ noisy 한 요약을 포함하고 있는 instruction span 과 option을 맞추는 semantic matching 이 중요하다
→ 사람은 예전에 찾았던 product로 다시 돌아오는 기능도 있지만 IR + RL 모델은 그렇지 않다는 점에서 long term memory 중요성이 대두된다
- IL 에 RL로 fine tuning 하는 것은 더 탐욕스럽게 만들지만 exploration을 줄이는 경향이 있다 (trajectory 길이가 9.4에서 4.8로 줄어든다)
→ attribute, type, price 점수가 오르지만 option 점수가 떨어진다
→ intrinsic bonus 를 통해 exploration 과 exploitation balance를 잡아야 한다고 주장
- search query 생성 방식을 고정시키고 choice oracle을 돌렸을 때 성능 향상을 보면서 right action choice 가 가장 중요한 팩터임을 알 수 있다.
→ choice oracle은 평균적인 IL + RL model과 사람의 trajectory 인 4.5, 11.3 보다 훨씬 높은 수백대의 trajectory 길이를 갖는 많은 탐색량을 가진 방식이다.
Sim-to-real Transfer
weshop에서 훈련한 IL + RL agent를 그대로 amazon 이나 eBay로 옮겨도 비슷한 성능을 기록한다.
두가지 addtional coding을 통해 이러한 결과를 얻을 수 있음은 실제 model deploy에 응용될 가능성을 의미한다.
Discussion
future 모델에 제안하는 방향
- multi-modal data를 통한 pre-training
- web hypertext
- web instruction-action mapping
- search exploration 공간을 늘리기 위한 query formulation
- action exploration 과 long term memory (long horizon을 위한)
