Introduction
-
higher resolution image를 처리하는 것의 문제점
1) memory contraint로 인한 작은 mini batch 수 도입
2) 1로 인한 training stability 방해
-> 위의 대안으로 low-resolution image로 시작하여 점진적으로 high-resolution image를 도입하는
방안을 생각 -
생성된 image quality와 variation은 trade-off로 여겨져 왔지만 이를 타파할 minibatch standard
deviation 도입 -
새로운 Network initialization 방식 도입으로 balanced learning speed 달성
Contribution1 : Progressive Growth
- low resolution으로 시작해 large scale 정보를 배우고 finer scale detail을 배운다는 아이디어
- Generator 와 Discriminator는 대칭적인 구조를 가지며 새로운 layer는 alpha 파라미터를 통해 선형
보간법 같이 smooth fade-in 함
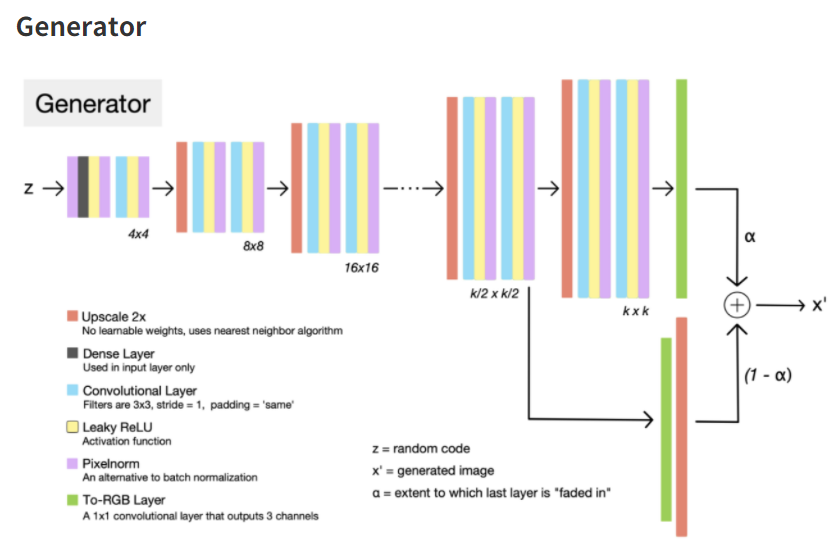
[출처: https://hackmd.io/@_XGVS6ZYTL2p6MEHmqMvsA/HJ1BBDtP4?type=view]
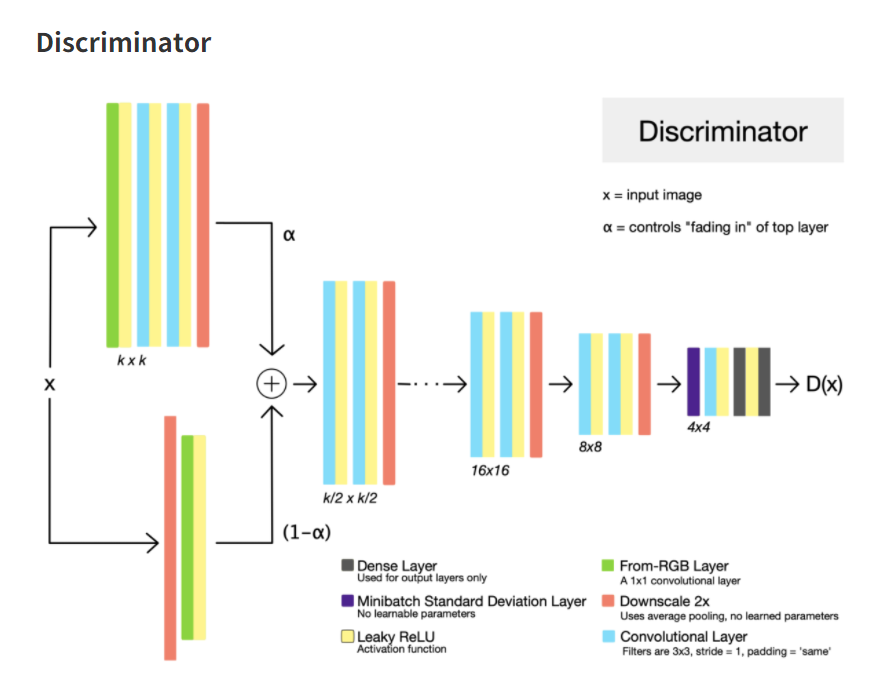
Contribution2: Minibatch standard deviation
- 자세한 내용에 대해서는 https://arxiv.org/pdf/1606.03498.pdf 참고
<해당논문 p.3 요약>
GAN이 빠질 수 있는 문제점으로는 Generator가 동일한 정보만 생성하도록 훈련될 경우이고 Discriminator도 대응하여 비슷한 latent space를 반복하여 가리키게 될 것이다(collapse to a single mode).
이러한 현상은 Discriminator가 input들을 independent하게 처리할 때 각 output latent space 간 연관성을 부여할 방법이 없을 때 문제가 되며 이러한 방법을 해결하기 위해서는 Discriminator에게 multiple data example들을 보여주면 연관성을 지을 수 있기 때문에 위의 그림에서 보는 것과 같이 Discriminator에 minibatch standard Deviation layer를 삽입한 것이다.
minibatch standard Deviation을 구하는 방법은 아래 그림과 같이 요약된다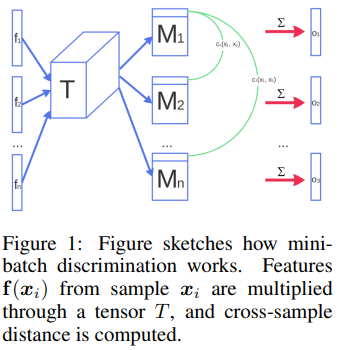
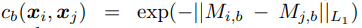
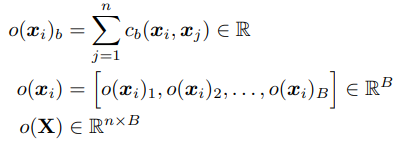
n 개의 minibatch가 존재한다고 했을 때 tensor matrix가 존재해 각 feature 값을 곱하면 Matrix n개를 얻을 수 있는데 각각의 row에 대해 L1 norm을 취한 뒤 다른 모든 Matrix와 이 값을 계산한 값을 더하면 i 번째 원소 값을 얻을 수 있다.
Contribution3: Equalized Learning Rate
- weight들은 N(0,1)으로 initialized 되지만 runtime에 명식적으로 scale된다.
wi/c 값이며 이 때 c는 He initializer의 per-layer normalization constant이다.
장점은 예측된 standard deviation으로 gradient update를 normalize하기 때문에 파라미터의 dynamic range에 상관없이 같은 속도로 update 된다는 점이다. - 이 방식은 Generator와 Discriminator에 모두 적용된다.
Contribution4: Pixelwise Normalization
- Generator와 Discriminator와의 경쟁으로 인해 magnitude가 발산해버리는 것을 방지하기 위해 Generator에서 각 convolution마다 pixelwise 하게 feature vector를 normalize 한다.
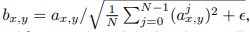
N은 feature map의 개수를 의미하며 a는 original, b는 normalized feature vector (x,y)자리 값을 의미한다. (N은 필터의 개수로 이해하였다)
Implementation and Code Review
-
To-RGB 와 From-RGB는 1x1 convolution layer를 의미하는데 이는 단지 전자의 경우 output channel을 3으로 맞추는 기능, 후자의 경우 channel 3에서 원하는 output channel로 맞추는 역할을 한다.
-
equalized learning rate
https://reniew.github.io/13/ - weight initialization 참고
scale constant는 He initializer 에서 왔으며 그 값은 sqrt(2/n) (n:이전 layer node수) 임을 참고하여
- pixelwise normalization
class PixelNorm(nn.Module):
def __init__(self):
super(PixelNorm,self).__init__()
def forward(self,x): # x will be (B,C,H,W) form
return x/(torch.mean(x**2,dim=1,keepdim=True)+1e-8)**0.5implementation 참고
https://github.com/jeromerony/Progressive_Growing_of_GANs-PyTorch
https://github.com/nashory/pggan-pytorch
https://github.com/Maggiking/PGGAN-PyTorch
다음으로 볼것?
meta-learning
few-shot learning
bias reduction
continual learning
